






凌云时刻


编者按:本文作者杜沁园(花名悬衡),2020 年进入钉钉审批团队担任研发工程师,负责审批底层的工作流引擎与规则引擎的研发工作。钉钉工作流每天有亿级的流程调度,是国内规模最大的工作流系统之一。
现在很多做流程工作或者调研流程引擎的人可能都已经没有听说过 PMC 了,但它在早期阿里工作流中确实是⼀个重要的角色。
有一个说法是当时阿里内外刚刚准备做自己的第一个工作流系统,Activiti 在那时也才刚出来不久,然后内外的早期开发者们经过调研,决定自研一个流程引擎,这样改起来更加方便。
若干年之后,阿里的业务越来越广泛,很多 toB 业务兴起,流程中有很多 toB 系统的重要组件,大家不想从零开始做,于是借鉴起步更早的阿里内外的经验,将 PMC 的代码 copy 一份部署便开始了自己的业务。目前我所知道的就包括钉钉审批、政务等等,经过这些年的发展,这几份 copy 代码应该都有了不少的区别,不过整体架构上应该都是差不多的。
如今,流程引擎的选择已经越来越多了,Activiti,Flowable, Camunda 或者帝奇的 SmartEngine,他们都比 PMC 更加开放,也拥有更加优秀的设计,或者更加遵守 BPMN 规范,基本上也不会有人再去 copy PMC 的代码了。不过,学习 PMC 的设计依旧能带给我们⼀些流程方面的启发。
流程引擎的简单原理

假设没有流程引擎,让你纯手撸⼀个审批流调度,你会怎么做呢?
假设有如下的流程配置:
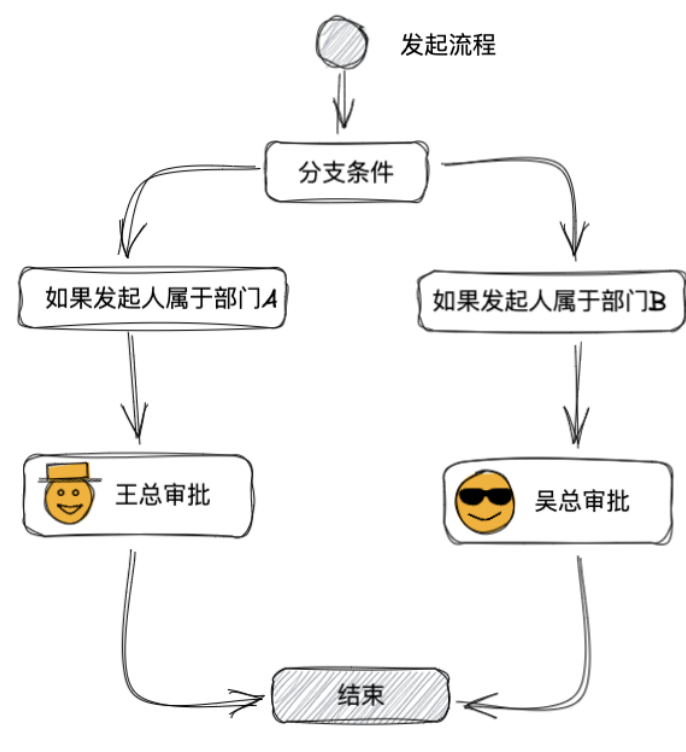
你肯定会先把流程配置保存在数据库,当有用户发起流程的时候就先从数据库中读取流程配置,然后遇到分支条件判断下发起人的部门。假如发起人是属于部门 A 的,就走左边的条件。这里发起人的所属部门可以理解成流程运行时的一个流程变量(Variable) ,然后依据这个变量的值进行分条,可以设计一张单独的表来存储这些变量,在流程发起时便将这些变量存储,审批的时候也可以支持增加或者更新。
左边的分支中只有一个活动(Activity) ,即王总审批,于是给王总生成一个审批任务(Task) ,其实就是在数据库中有个任务表,在里面插入一条操作人(Actioner) 是王总的记录,流程暂时停止运行,流程停止的节点位置也可以顺带存储在任务表中。等到王总打开“待我处理”页面时,后台会执行一条 sql,从任务表中读出所有操作人是王总的任务展示出来,然后每个任务展示一个同意拒绝按钮。
如果你觉得让用户主动打开页面体验太差,也可以通过观察者模式,写一个任务生成监听器,每当有新的任务记录生成时就会收到一个任务生成事件(这个事件可以是同一应用中观察者模式的一次同步或异步调用,也可以是一个 MQ 消息),收到事件后就给用户发送一个钉钉消息,直接把“待我处理”页面的 url 发送给用户,用户收到消息打开链接就可以进行审批了。
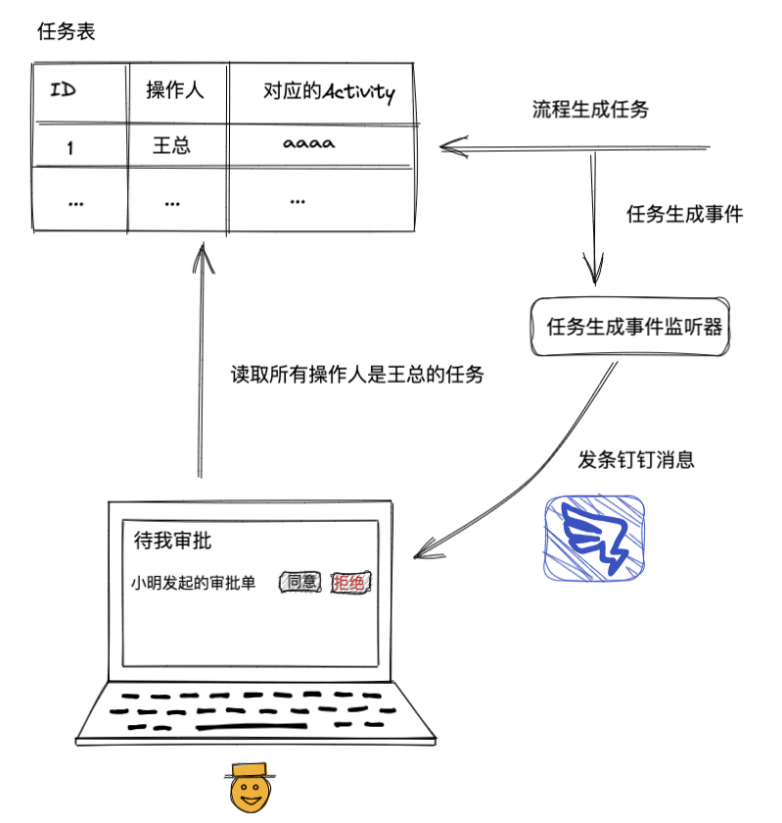
假设王总点了同意,那么后台收到请求后就会把任务表中相应的任务置为已完成,然后从 task 表中记录的流程位置开始继续运行流程,发现已经运行到了最后一个节点,于是将流程状态置位结束。
如果不加入其他更复杂的需求的话(比如会或签、加签等等),上面的这几个简单的元素就足以构成一个流程引擎,对于整个流程的流转,你可以选择迭代实现,或者递归实现,不过据我了解,PMC 以及其他的开源引擎貌似都是递归实现的,可能因为这样实现起来更简单一些。
先简单对上面的一些流程引擎的概念做个总结:
 流程配置:流程图的完整配置信息
流程配置:流程图的完整配置信息
 流程变量(Variable):流程运行过程中分支条件需要用到的变量
流程变量(Variable):流程运行过程中分支条件需要用到的变量
 活动(Activity):流程中的一个节点
活动(Activity):流程中的一个节点
 任务(Task):每个 Task 都对应一个具体的审批人,帮审批人记录他们待完成的任务
任务(Task):每个 Task 都对应一个具体的审批人,帮审批人记录他们待完成的任务
BPMN 规范的流程配置

流程配置要描述整个流程图的信息,必然很复杂,业务建模领域有一个通⽤的流程建模标准,叫做BPMN(Business Process Model And Notation),在 OMG 官网上有标准的文档可以下载查看,目前最新版本是 2.0。
规范基于 xml 描述流程,本身非常复杂,但是常用的不多,只要知道有以下类型的节点就行了,具体的节点内部的 xml 定义规范比较复杂,PMC 甚至都没有完全遵循,所以就不做过多阐述了。
 StartEvent
StartEvent

顾名思义,开始节点。所有流程都会从这里开始。
<startEvent>...</startEvent>
 EndEvent
EndEvent

顾名思义,结束节点。
<endEvent>...</endEvent>
 UserTask
UserTask

代表着有一个或多个人参与的任务,可以理解为审批节点,审批除了单人审批,还可以是复杂的会或签,依次审批等等。
<userTask>...</userTask>
 ServiceTask
ServiceTask

代表着一个可以自定执行任务的节点,比如抄送,发邮件等等都可以是一个 ServiceTask。
<serviceTask>...</serviceTask>
 SequenceFlow
SequenceFlow
这个不是节点,而是代表节点之间的连线,还可以在上面配置条件,只有符合条件才会走这一条连线。
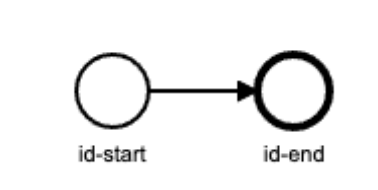
<startEvent id="id-start"/>
<endEvent id="id-end"/>
<sequenceFlow id="line_start_end" sourceRef="id-start" targetRef="id-end"/>
上面的配置的含义如下图:
 排他网关
排他网关

<exclusiveGateway>...</exclusiveGateway>
比如下图中只会走第一个符合条件的分支,其他分支都不会运行。
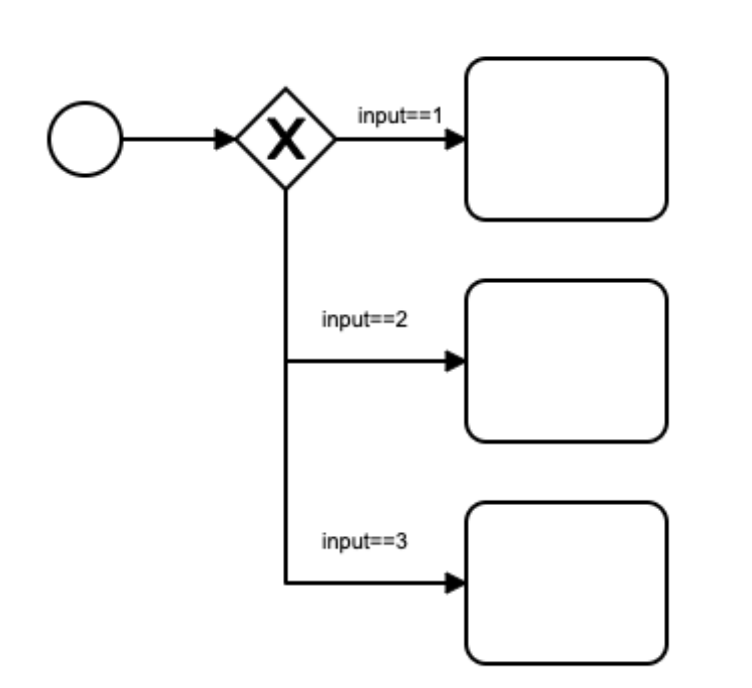
这个组件一般很少使用,因为直接使用 SeqenceFlow 也是和它等效的,一个和上面等价的画法如下:

 并行网关
并行网关

将排他网关中间的叉变成十字,就是并行网关了,并行网关会同时执行后续的所有分支。
 补充
补充
有这些基础,你已经能读懂基本的 BPMN 配置了,你还可以在 bpmn.io 网站上绘制 BPMN 流程,然后下载配置文件,看一下它的配置是什么样子。如果你看过一些简单流程的 BPMN 配置,会发现这是一个很重的 xml 规范,即使是简单的流程,可能也要百行的 xml 配置。
个人认为这个规范是 PC 时代的产物,比如 Office 全家桶的规范也都 xml,它们诞生的时代也都差不多,对于本地软件来说,配置重一点并没有什么问题,但是对于互联网时代,浏览器和服务端传递这么重的 xml 配置就不太合适了,像阿里云的 Serverless 工作流以及微软 Azure 的工作流都提出了新的 json 规范,钉钉审批虽然底层 PMC 运行的还是 BPMN 规范,但是前后端还是使用 json规范通信的,之后再转换成 xml 给 PMC 执行。
那么实现 BPMN 规范有什么好处呢?
好处就是网上有很多开源的设计器可以直接拿来用,比如bpmn.io。也有利于对业务建模比较了解的人上手(据说 MBA ⼀般都会学习 BPMN)。但是在互联网环境下,一般用户和开发者都不太了解 BPMN 规范,前端也不太可能直接用复杂的开源 BPMN 设计器的,一般都是重新写一套用户体验更好的设计器,所以个人感觉互联网应用实现 BPMN 规范意义不太,PMC这么做应该是受到了开源引擎 Activiti 的影响。
PMC 的流程执⾏过程

之前我们已经脑补过一个简单的流程引擎,我们以下面只有一个抄送节点的流程为例继续脑补
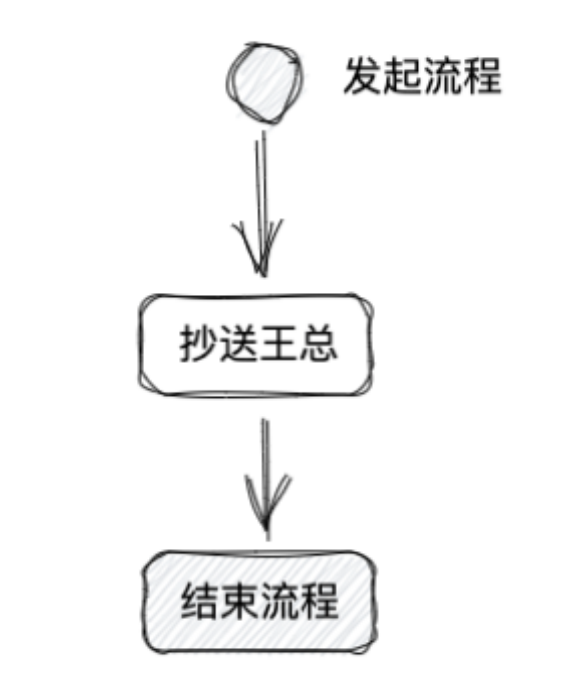
抄送节点在流程中一般是一个 ServiceTask,你可以有两种执行方式:
 在用户发起流程的请求处理过程中,就同步地完成抄送,然后流程继续执行(同步执行)
在用户发起流程的请求处理过程中,就同步地完成抄送,然后流程继续执行(同步执行)
 到“抄送王总”这个节点直接暂停流程,生成一个调度项(Resumption),由调度器异步重新拉起流程,完成抄送后再继续执行(异步执行)
到“抄送王总”这个节点直接暂停流程,生成一个调度项(Resumption),由调度器异步重新拉起流程,完成抄送后再继续执行(异步执行)
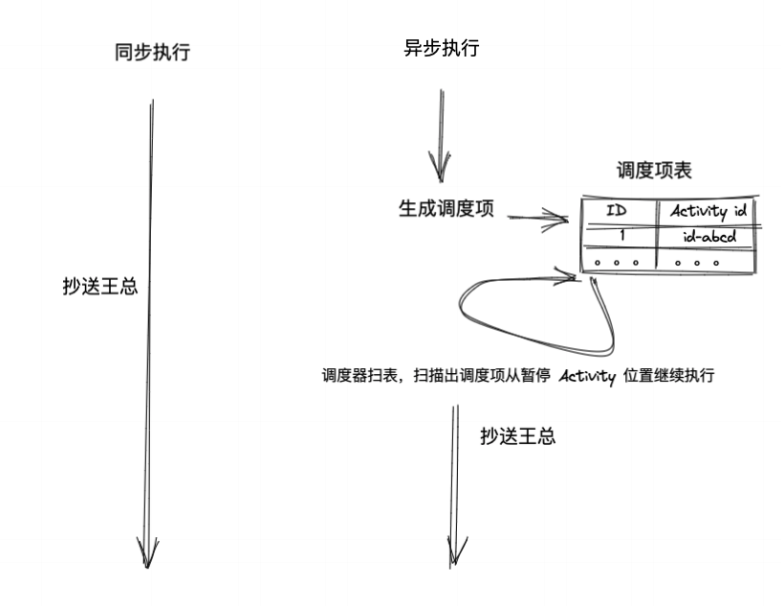
在开源引擎 Activiti 中,节点默认都是同步执行的,只有打开节点的 async=true 的开关,才会是异步执行。
在 PMC 中则相反,节点全部都是异步执行的,并且不开放配置。对于上图中的非常简单的流程,都需要经过三次调度才能完成:
 发起流程时
发起流程时
 抄送之前
抄送之前
 流程结束之前
流程结束之前
这个可能会让人困惑,为什么流程结束之前还要搞一次调度?这是因为 endEvent 节点在 PMC 中是被当成 ServiceTask 处理的,而 ServiceTask 都是需要调度后执行的,所以 endEvent 执行前会先生成一个调度项,被调度到后才会结束流程。
如此频繁地调度,还都是基于数据库扫表的,在业务量大之后很容易遇到性能问题,钉钉审批在去年确实也遇到了这方面的性能问题。如果你再仔细考虑下“异步执行”的方案,直接将需要异步处理的任务丢到一个线程里不就完了,为什么非要扫表呢?我的一位师兄去年就做了一个类似思路的优化,在调项生成之后,优先走内存调度,除非内存调度出现问题才会触发基于扫表的调度,帮助我们渡过了调度性能的危机。
userTask 的设计

在 PMC 中,对每种 BPMN 节点(比如 userTask, startEvent, serviceTask, endEvent 等等),都有一个类实现其节点行为,其中最复杂的莫过于 userTask 的实现。
在我们脑补的流程引擎中,userTask 里只有一个审批人,会直接给这个用户生成一条 Task 记录,但是我们要怎么处理会或签,依次审批或者加签呢?这时就要引入一些新的概念。对于一个 userTask,它内部可能会有多个TaskSequence,每一个 TaskSequence 内部也可能会有多个 TaskGroup,而 TaskGroup 里也可以有多个 Task,此时的 Task 才是我们之前讨论的 Task。
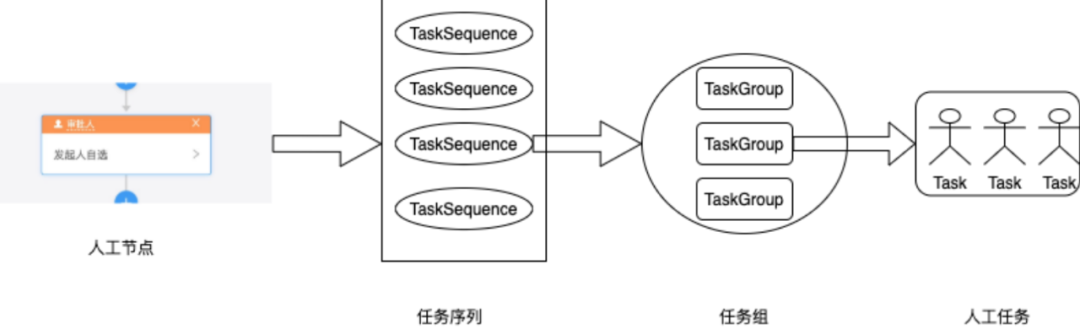
 TaskGroup
TaskGroup
任务组,里面有多个 Task,这些 Task 的关系由任务组的激活类型(ActivateType)决定,任务组有两种激活类型:
ALL:一次性产生所有 Task,即任务组中的所有审批人都会同时收到审批单,一般会或签都是这种激活类型。
ONE_BY_ONE:逐个产生 Task,举个栗子,任务组中第二个审批人要等第一个审批审批完才能收到审批单,依次审批用的就是这种激活类型。
任务组有一定的结束条件(FinishRule),达到结束条件后,即使有任务没有结束也会被强制结束,结束条件其实就是一个脚本:
会签一般是 all("agree") ,即全部同意才算审批通过。
或签一般是 atMostOf( 1, "agree" ) ,只要一个同意就算同意。
通过 TaskGroup 我们就可以实现简单的加签:
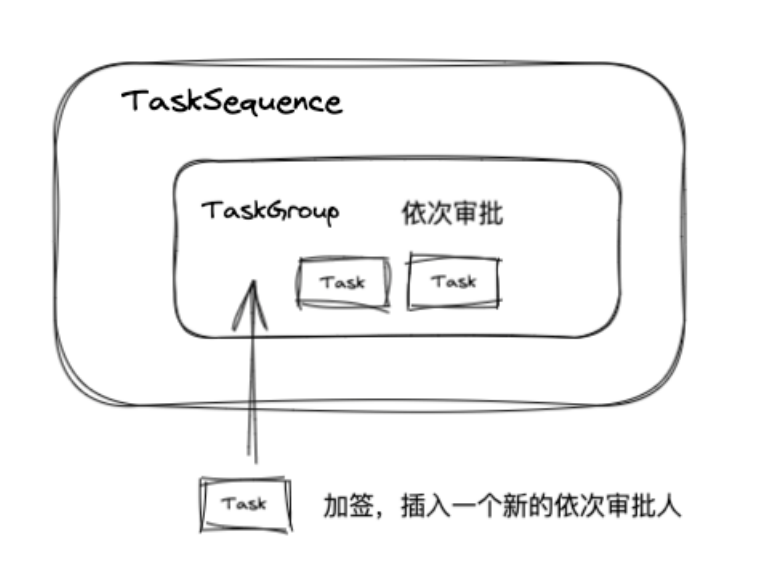
 TaskSeqence
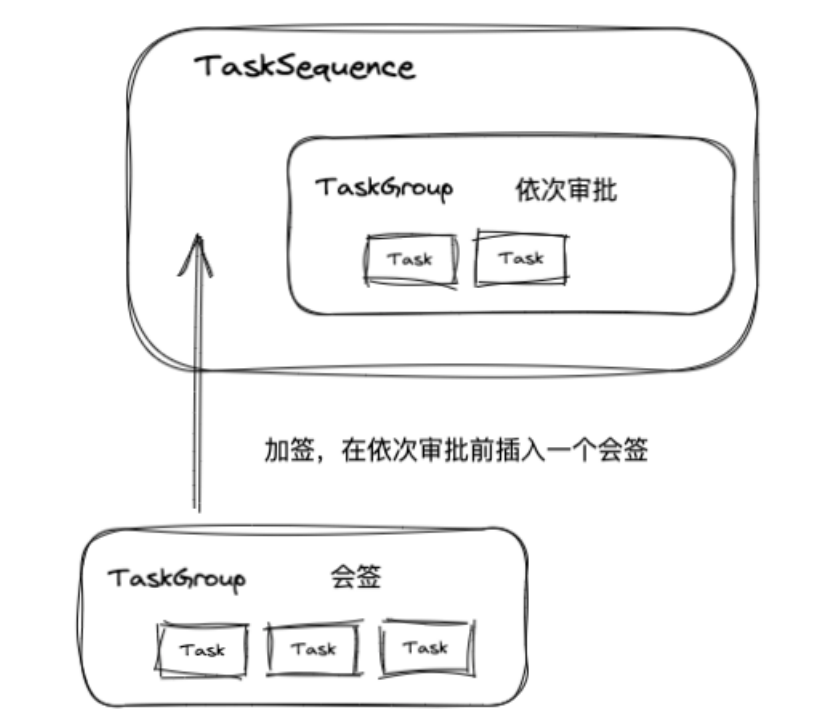
TaskSeqence
一个 TaskSequence 中有多个 TaskGroup,可以进行更加复杂加签,但是目前钉钉审批没有这么复杂的加签,所以相对比较鸡肋。当时 TaskSequence 的设计者可能还有更多的用途,而我没有想到,欢迎大家在评论区补充。
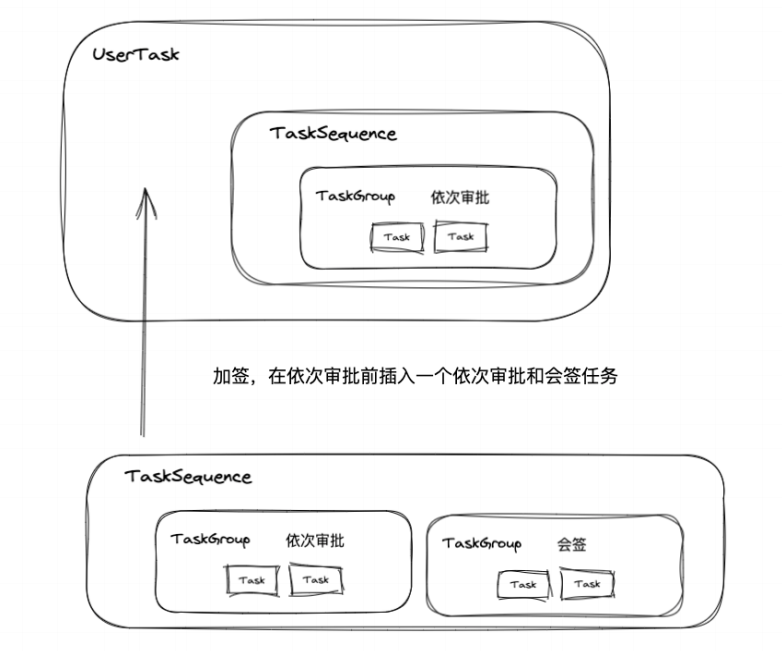
 总结
总结
userTask 包含多个任务序列(TaskSequence), 每个任务序列包含多个任务组(TaskGroup),每个任务组又包含多个任务。
激活类型(ActivateType):决定了任务组中的任务是一起产生(ALL),还是逐个产生(ONE_BY_ONE)。
结束条件(FinishRule):任务组达到结束条件后,即使有任务没有结束也会被强制结束。会签/或签就是利用这个实现的。
其实 PMC 对会或签的实现没有严格遵守 BPMN 的规范。符合规范的实现可以参考Activiti中的会或签与依次审批实现。
PMC 中的规则引擎-ServiceRequest

在 PMC 的 BPMN xml 配置中,经常会看到类似的 alipmc:rule 标记。
 seqenceFlow 中的分条件:
seqenceFlow 中的分条件:
<sequenceFlow id="line-random-sid-startevent-e19c_12a0" sourceRef="sidstartevent" targetRef="e19c_12a0">
<extensionelements>
<alipmc:condition>
<alipmc:rule id="Groovy">
<alipmc:parameters>
<alipmc:parameter name="">true</alipmc:parameter>
</alipmc:parameters>
</alipmc:rule>
</alipmc:condition>
</extensionelements>
</sequenceFlow>
 审批人配置:
审批人配置:
<alipmc:actionerrule>
<alipmc:rule id="OfficialRuleConf">
<alipmc:parameters>
<alipmc:parameter name="">{"workNo":"111","userName":"⼩明"}
</alipmc:parameter>
</alipmc:parameters>
</alipmc:rule>
</alipmc:actionerrule>
alipmc:rule 的本质就是一个策略分发,含义就是用配置的 parameters 去调用相应id的规则。比如Groovy就是计算Groovy 脚本的值, OfficialRuleConf 就是根据这段 json 获取审批人。
这些 id 都是在 PMC 的配置文件里配置好的,你会发现它又包括两个部分:
<entry key="Groovy">
<bean class="xxx.ServiceRequestRelation">
<constructor-arg value="GROOVY" />
<constructor-arg value="groovyServiceRequestHandler" />
</bean>
</entry>
这个两个值都是用来从工厂中取 bean 的 ID。第一个 bean( Groovy )是一个序列化器,是用来根据parameters 序列化出一个 ServiceRequest 的子类,第二个 bean( groovyServiceRequestHandler ) 则是执行器,会在规则执行的时候把序列化出的 ServiceRequest 传递给它执行。
后来为了支持更加复杂的且或条件,通过多个规则获取多个审批人等等需求,我们在下面的 json 参数里又增加了一层策略分发:
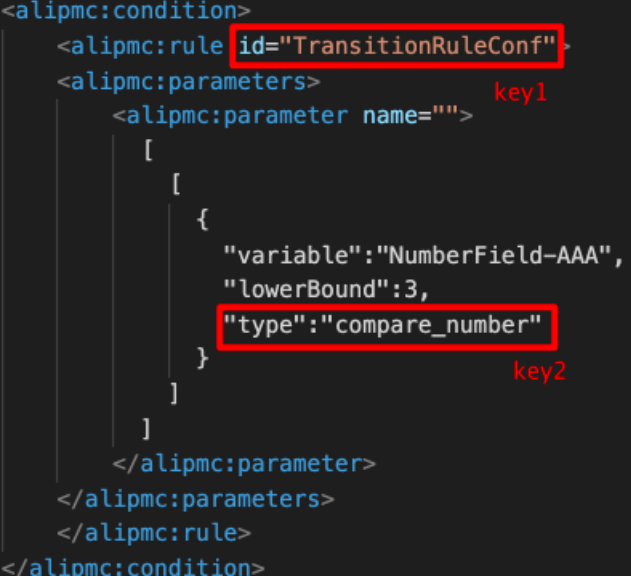
分支条件 TransitionRuleConf 中的 parameter 里的两层数组里,内层数组是且,外层数组是或,假设 json是 [[{rule1}, {rule2}], [{rule3}]] ,那么这个条件的含义就是 (rule1 && rule2) || rule3 。上图中type 为 compare_number 的规则就是将流程变量 NumberField-AAA 与 3 比较大小。
正是因为做了这么多层策略分发,所有 PMC 规则部分的代码才经常被人评价为 “绕”。不过理解了之后会发现其实很简单。
钉钉审批流与 PMC 工作流的转换

在前文中其实已经将了不少钉钉审批对 PMC 的应用了,这里主要说说钉钉审批流是怎么转换成 PMC 的工作流配置的。
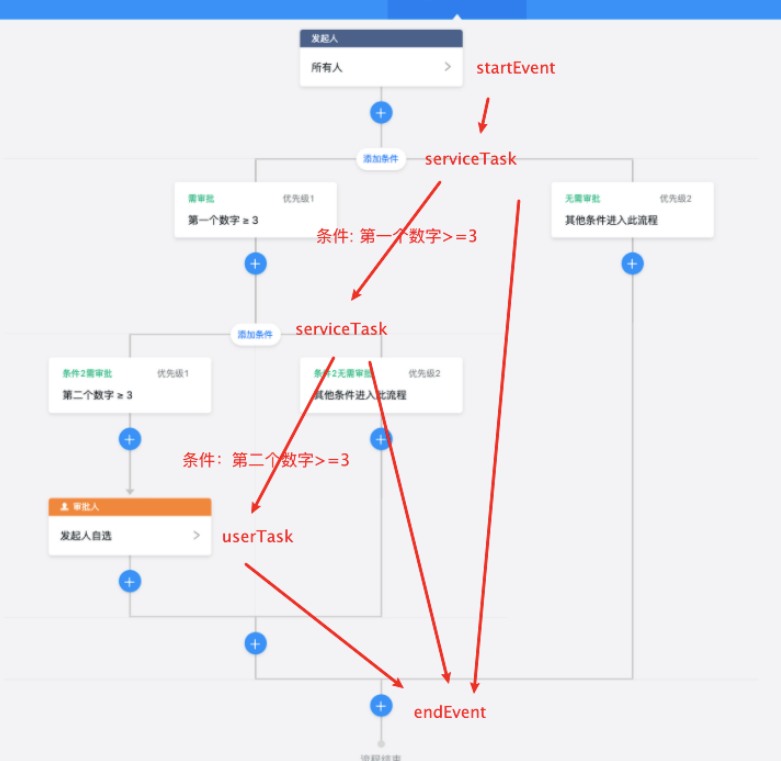
我们会对针对每个分条件生成意个什么都不干的 serviceTask 节点,然后用这个节点去连接后续节点,把分条件的定义写在 sequenceFlow 定义上面。其实这里分条件的 serviceTask 就是起到一个排他网关的作用。貌似审批现在的方案会额外导致一次调度,是不是换成排他网关更加合理⼀点呢?
 审批拒绝
审批拒绝
一旦审批人点击了拒绝,整个流程就会立即结束。一种解决方案是给每个审批人节点生成一个到 endEvent 的连线,那样的话未免有些笨重。我们的做法是在每一个 userTask 向后的连线中,添加意个 lastResult('agree')的条件,这样当审批拒绝时,整个流程就没有通路可走了,流程自然也就结束了。

 自动通过
自动通过
钉钉审批还支持在一定条件下的自动通过:
这个是利用 PMC 提供的 afterfilters 功能,可以在节点插入一个后置拦截器,我们在其中筛选出节点中产生的可以自动通过的 task,自动将其通过。
afterfilters 也是写在流程配置中的:
<alipmc:afterfilters>
<alipmc:listrule>
<alipmc:rule id="AutoCompleteFilter">
<alipmc:parameters>
<alipmc:parameter name="">
{
"name":"task_auto_execute",
"type":"task_auto_execute",
"content":{
<!-- ⾃动执⾏的相关配置,此处省略 -->>
}
}
</alipmc:parameter>
</alipmc:parameters>
</alipmc:rule>
</alipmc:listrule>
</alipmc:afterfilters>
alipmc:rule 也就是前文中所说的规则引擎了,他会通过 AutoCompleteFilter 找到相关的 bean 并且调用。(完)

你可能还想看
1. 机器学习落地的五个阶段
2. 大数据实时加工服务的设计及实践
3. 从操作系统层面分析Java IO演进之路
4. 从运维和SRE角度看监控分析平台建设
5. 如何做好一场技术演讲?
END

每日收获前沿技术与科技洞见
投稿及合作请联系邮箱:lingyunshike@163.com















 887
887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









