






云布道师

为了更好地方便各位开发者和用户了解并应用 ECS 倚天实例,由阿里云弹性计算联合基础软件团队 & 平头哥 & 安谋科技(arm),共同发起了【倚天实例迁移课程】,本系列课程共计 10 节课程,共分为基础篇、架构迁移篇和性能优化篇三大篇章,从不同角度为用户带来更加丰富和专业的讲解。
2023 年 9 月 14 日,系列课程第八节《基于ECS倚天实例的大数据加速最佳实践》正式播出,阿里云弹性计算大数据优化负责人李腾飞主讲,内容涵盖倚天大数据场景迁移适配、倚天大数据性能加速实践和倚天大数据场景落地实践。
本期节目在阿里云官网、阿里云钉钉视频号、InfoQ 官网、阿里云开发者微信视频号、阿里云创新中心直播平台&微信视频号同步播出,同时可以点击【https://developer.aliyun.com/topic/ecs-yitian】进入【倚天实例迁移课程官网】了解更多内容。
以下内容根据李腾飞演讲内容整理而成,供阅览:

基于ECS倚天实例的大数据场景迁移适配
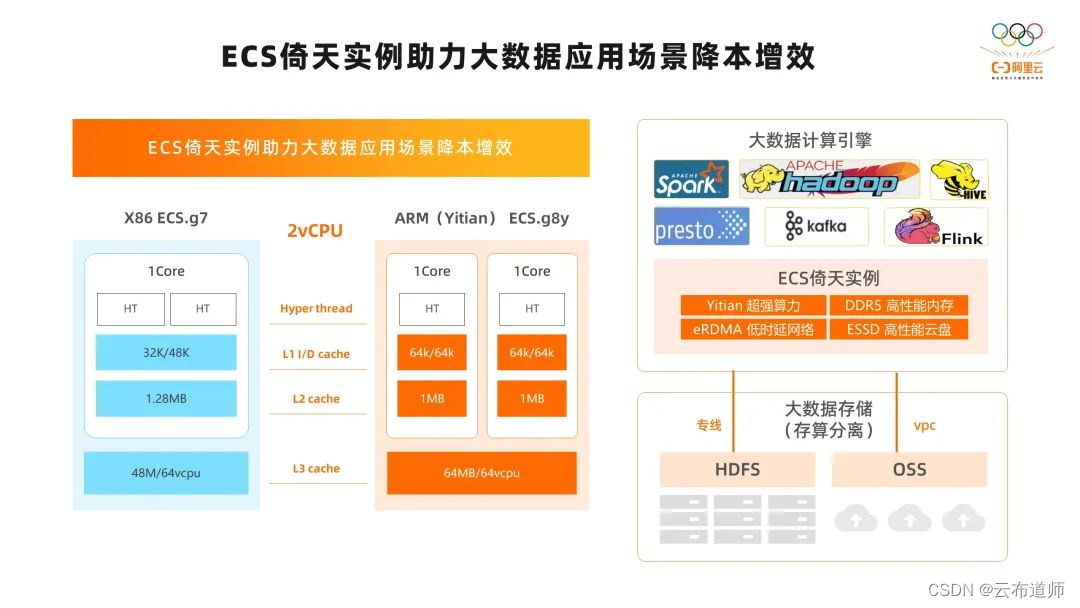
首先,来看一下在大数据场景,如何使用 ECS 倚天实例。从上图中,可以看到在大数据存算分离的场景中,我们一般会使用远端 HDFS 集群或者 OSS 对象存储作为存储集群,通过专线或者 VPC 网络来连接计算集群。在计算集群中,我们可以使用 ECS 倚天实例作为计算节点,在上面运行大数据的一些组件,比如 Spark、Hive、Flink、Presto、Kafka 等等,这样我们可以获得很好的性能和性价比。
下面我们具体分析一下 ECS 倚天实例的优势。
第一,ECS 实例是基于倚天 CPU 的,倚天 CPU 是 ARM 架构的,相比 X86 平台它提供的是物理核,没有 HT,能够提供比较强的算力。特别是在 CPU 负载比较高的情况下,依然能够保持性能的稳定和线性增长,这对于大数据场景来说,不管是离线还是在线业务,它能够保持 CPU 利用率非常高,这是一个很好的优势。后面我们在分享 Spark、Flink 的性能的时候也会讲到,同时相比 X86 平台,倚天有 20% 以上的大幅度性能提升。
第二,ECS 倚天实例基于 DDR5 的高性能内存,在实际使用过程中,能够提供比较高的内存带宽和比较低的内存时延。也可以根据业务不同的需要来使用不同规格的 ECS 实例,来匹配内存容量的需求。对于大数据基于内存计算的框架,比如 Spark、Presto、Flink 可以发挥出很好的性能优势。
第三,ECS 倚天实例相比 X86 平台的 g7 实例,L1/L2/L3 的 cache 大一些,这样可以在大数据计算的场景中提升性能。
第四,ECS 倚天实例搭载阿里云最新的 CIPU 计算架构,能够提供超低延时的eRDMA 网络和高性能 ESSD 云盘,对于大数据业务网络和磁盘 IO 压力较大的场景,比如数据的 shuffle 和 HDFS 文件的读写,都可以提供稳定、高性能的保障。
第五,在成本方面,ECS 倚天实例相比同等算力的 X86 实例,有接近 30% 的成本优势。
从上面的分析,我们可以看出,ECS 倚天实例在大数据场景确实有很好的性能和性价比优势,可以帮助客户实现大数据场景降本增效的目标。
接下来看一下,我们怎样才能把我们的大数据业务在倚天实例上跑起来?其实随着 ARM 生态的不断发展,到今天为止,大部分主流的大数据平台的组件都可以在 ECS 倚天实例上做到比较好的适配,并且能够做到比较平滑的从 X86 平台到 ARM 平台的迁移。
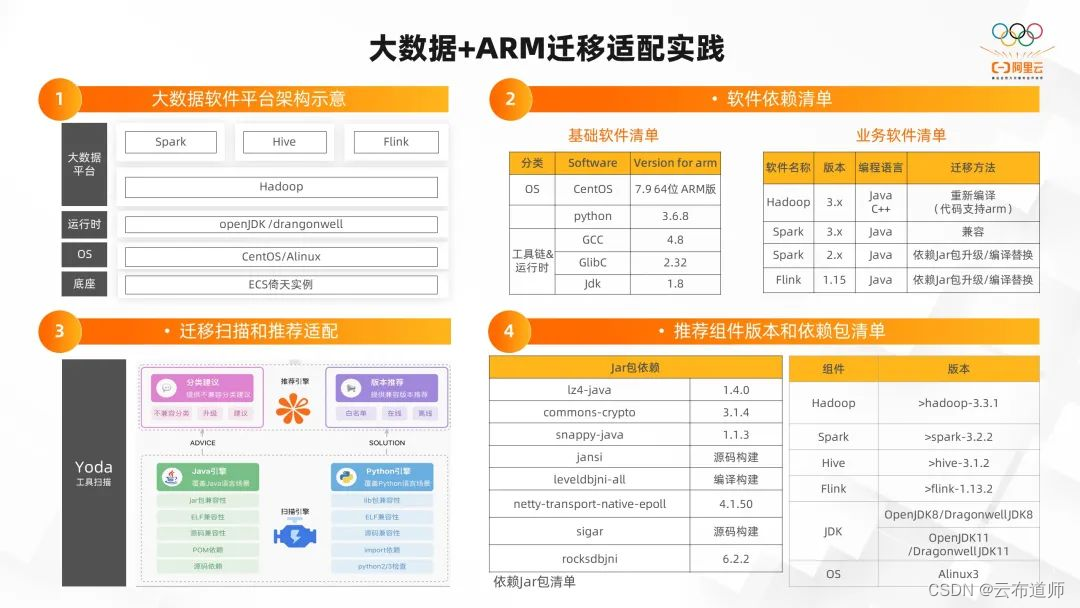
我们基于内外部的实践经验,给大家介绍一下大数据在 ARM 的迁移适配实践。从图一可以看到,是一个比较典型的基于 ECS 倚天实例底座的大数据平台。在 OS 层面可以使用 CentOS,也可以使用阿里云自研的Alinux的ARM版本来获得更高性能、性价比、稳定性的收益。在 Java 运行时层面,也可以使用 Open JDK,或者阿里自研的 Dragonwell 引擎来获得更好的性能和稳定性的收益。在平台层面,我们基于主流有的 Hadoop、Spark、Hive、Flink 版本构建分布式离线及实时计算、存储、调度引擎。
在这样的大数据软件平台架构下,对于基础的软件和大数据的业务软件都会有一些基础的依赖。举个例子,基础软件使用 CentOS 7.9 版本,Python 3.6.8,JDK 1.8,还有 GCC 和 JDC 的一些版本。
在大数据业务的软件里,比如 Hadoop3.3 社区版本已经官方支持了 ARM,所以我们直接在社区下载 ARM 版本就可以直接使用。还有一些比较低的版本,我们需要重新编译代码,或者将不兼容的 Jar 包进行替换。这里主要是因为 Spark、FLink 版本里的 Jar 包,包含一些 Native 的 so 包,这些里面可能有不兼容倚天 ARM 的代码。
如果我们在实际迁移的过程中,不清楚自己的软件版本以及 Jar 包是否兼容倚天 ARM,阿里云在实践的过程中,也积累了一些代码扫描、分析的工具。PTG 团队有一个叫做 Yoda 的工具,可以帮助客户分析组件的代码中有哪些是不兼容 ARM 的包和代码。我们可以对它进行扫描,并给出分析和建议。
通过分析建议以后从具体的实践来看,需要替换 Jar 包的是有 Native 的 so 包的,比如 LevelDB、Netty、RocksDB 的一些包。这里面有一些是可以通过升级版本来替换,有一些需要针对源码做重新的编译构建。
如果我们在实际的迁移过程中,大数据组件的版本可以做升级或者替换,我们也有一些推荐使用的组件版本。比如 Hadoop 推荐 3.3 以上,Spark 推荐 3.2以上,Hive 推荐 3.1 以上,Flink 推荐 1.13 以上,JDK 推荐 openjdk11 或者 dragonwell11,这样能带来更好的性能收益。OS 层面我们推荐使用阿里云的 Alinux3,这样能将已经做好 ARM 适配的版本和工作在迁移的过程中省略掉,让大数据在 ARM 迁移的过程中更加平滑。
神龙大数据应用加速套件的介绍
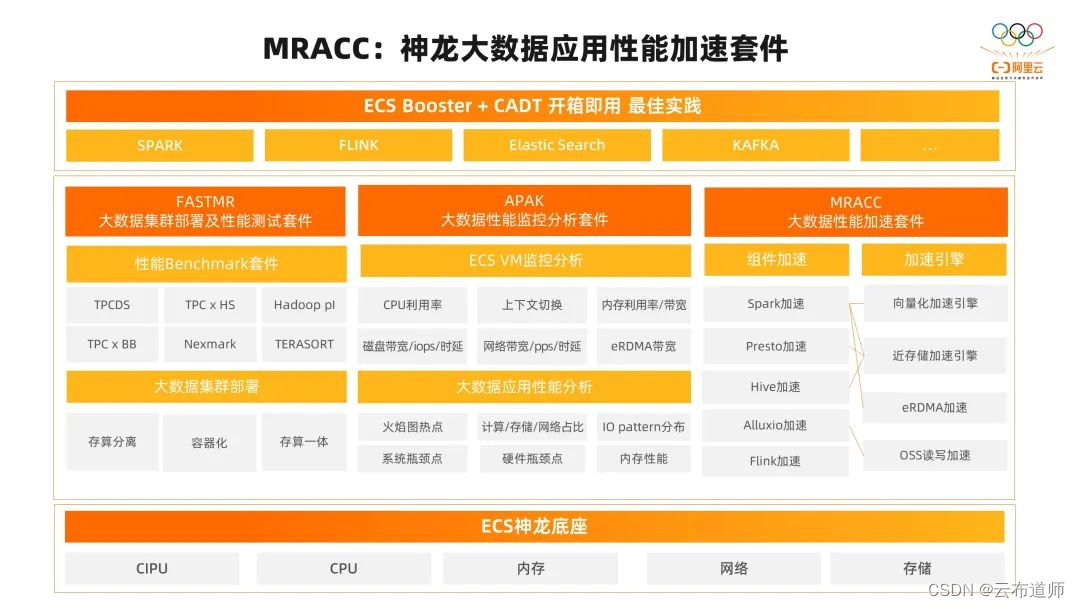
首先,介绍一下神龙大数据应用性能加速套件,它是我们专门为基于 ECS 倚天实例的大数据场景打造的。为了让使用 ECS 倚天实例的客户在大数据场景下能够快速地获得更高的性能和性价比体验,我们基于 ECS Booster+CADT 打造了一个开箱即用的最佳实践,目前我们支持 Spark、Flink、ElasticSearch、Kafka。
目前,神龙大数据应用加速套件主要包括三个主体部分。
第一,FASTMR,大数据集群部署及性能测试套件,它主要在大数据场景评测 ECS 倚天实例的性能。在大数据集群部署中,我们支持存算分离的、容器化的、存算一体的架构的一键化部署。
在性能的 Benchmark 套件中支持 TPCDS 这种决策支持类 SQL 分析的Benchmark,它也是大数据目前评测的比较主流的 Benchmark;支持 TPCx-HS 这种针对整体大数据组件的 IO 和系统性能的评测;支持 Hadoop pi 这种针对计算性能的评测;支持 TPCx-BB 这种针对 SQL 分析和机器学习相关的性能评测;支持 Nexmark 这种针对 Flink 吞吐能力的评测等等。让我们比较方便的通过 FASTMR 在倚天上进行大数据集群的各种 Benchmark 的性能评测。
第二,APAK,大数据性能监控分析套件,它主要为了方便进行后面的性能调优,在大数据业务运行中,不管是在倚天 ECS 的 VM 层面,还有大数据应用的层面,都需要进行指标的监控和分析。
在 VM 层面,我们主要针对 CPU 的一些指标,比如 CPU 的利用率,包括sys、user、iowait 等指标;CPU 上下文切换;内存的指标,包括内存的使用率、内存带宽;磁盘的指标,包括带宽、IOPS、时延;网络的指标,包括带宽、PPS、时延的指标。还有我们比较个性化的针对 eRDMA 的带宽的监测。
针对大数据应用层面,为了能够看到大数据业务运行中的性能表现,我们支持包括火焰图热点分析,看一下在运行过程中的热点函数;在 E2E 性能评测中,计算、存储、网络在整个过程中的时间占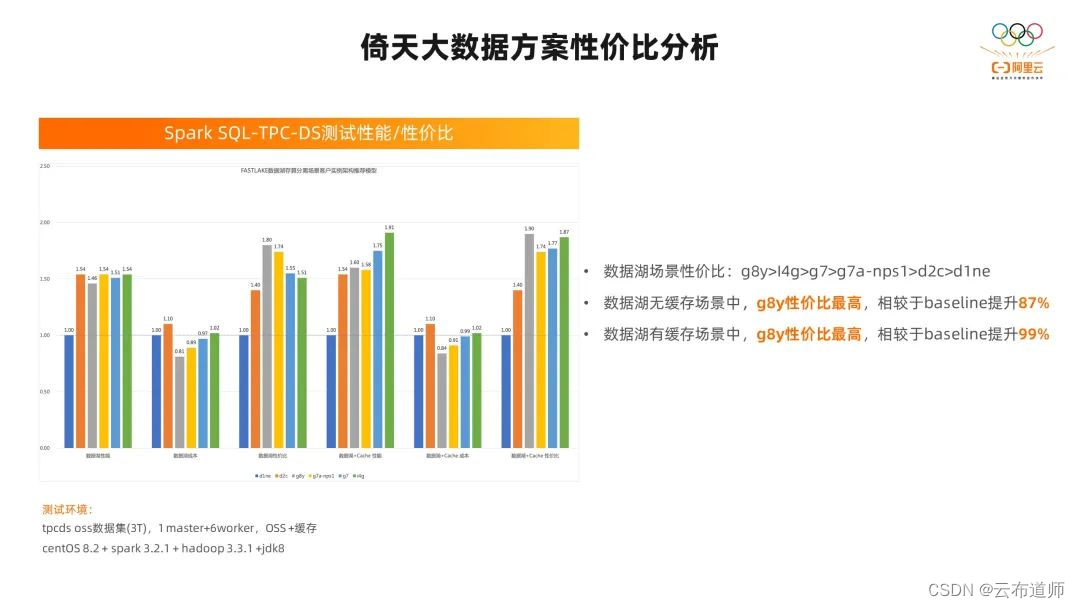
比;IO Pattern 分布,看任务运行过程中 IO 的模型;还有系统瓶颈点、硬件瓶颈点的自动化分析,内存性能的监控分析。
第三,MRACC,大数据性能加速套件,它主要为了加速常用的大数据组件。我们针对 Spark、Presto、Hive、Alluxio、Flink 等组件做了一些插件化的引擎;针对 Spark 做了向量化加速的引擎;针对 Spark、Presto、Hive 做了近存储加速的引擎,去降低网络带宽的影响;针对 Spark 的 Shuffle 做了 eRDMA 的加速;针对 Alluxio 做了 OSS 读写的加速。这些引擎都是以客户无感的插件化的形式提供出来的,在很多场景里也都拿到了很好的性能收益。
最下面的是 ECS 的神龙架构,它基于 CIPU、CPU、内存、网络、存储提供基础能力,整个性能加速套件也是在底座的基础上做的性能优化。
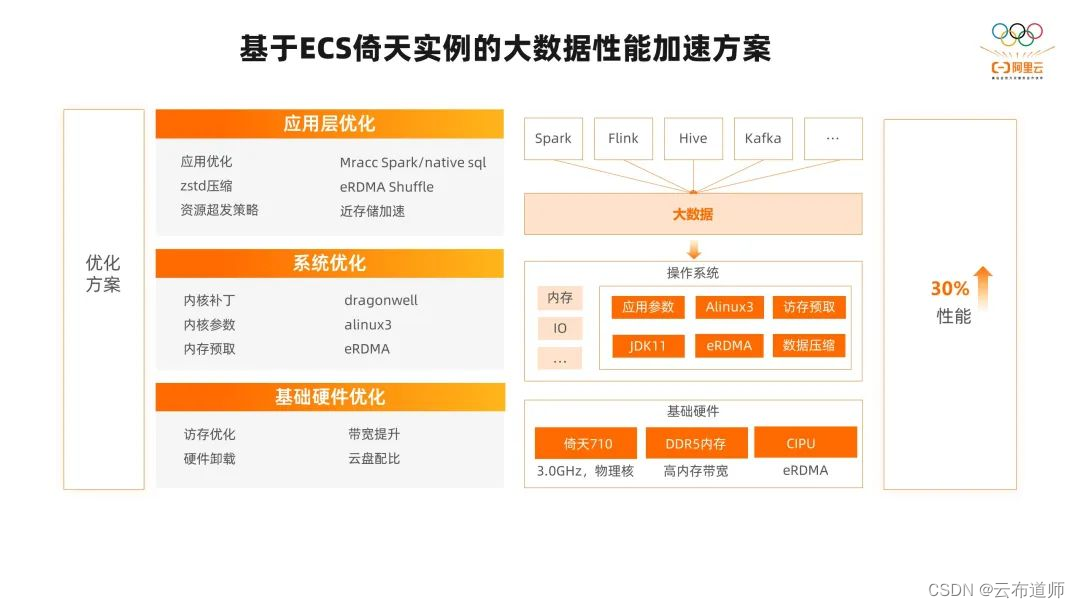
有了大数据性能加速套件以后,我们就能对具体的大数据场景和问题针对性地设计优化方案,来解决我们的性能问题了。
在应用层,我们可以通过 Spark 层面的应用优化,包括 Spark 的 Native 引擎,是我们针对 Spark SQL 模块做的算法优化和向量化优化,我们在实测过程中也能提升接近 2 倍以上的性能。比如在压缩层面可以做一些 zstd 的压缩优化,降低临时数据的存储容量,从而降低大数据场景下使用倚天实例过程中的云盘大小,提升性价比。
如果碰到专线的瓶颈或者 OSS 带宽瓶颈,我们可以引入近存储加速来解决问题。如果系统的资源利用率未完全利用,我们可以通过应用层的优化,比如参数的配置,资源超发策略的优化来提升 ECS 倚天实例整体的计算效率和资源的使用效率,充分利用 ECS 倚天实例 CPU 和内存的资源提升性能。
在系统层面,我们也做了很多优化,比如内核补丁、内核参数,内存预取、JDK 层面的优化。比如在过程中碰到 CPU sys 占比比较高的情况,我们可以在系统层和基础硬件层做一些优化,比如应用 ARM 的一个 E0PD 补丁,这样可以在做好安全防护的同时,降低系统调用的开销,将客户实测的性能提升 5%。
在中断比较高的场景,我们可以针对性做 IO 的优化,包括软中断的优化,线程切换的优化,rps、xps 网络 IO 的优化,在实测中我们可以提升 Spark 的性能。还有一些内存预取,包括文件缓存相关的优化也都能够带来不错的性能提升。
从 JVM 的角度,目前广泛使用的 1.8 版本,针对 ARM 的支持不是很完善,这会导致我们在倚天上的性能退化。因此 Dragonwell 也针对倚天做了一些稳定性的优化,包括 openjdk 以及一些新的版本,在 ARM 上的适配也会更好,这也是我们推荐使用的。
因为倚天 CPU 的 ARM 架构和 X86 指令级的架构差异还是比较大的,所以在系统 OS、JVM 层面、编译层面,能够做的优化也还是比较多的,在大数据场景带来的收益也不少。
在基础硬件层,ECS 倚天实例也在不停的演进中,包括从 CPU 的主频、内存的频率等都有提升的动作,这对于整个大数据场景也是非常有用的。如果碰到一些 IO 带宽的瓶颈,我们可以使用基于倚天的带宽增强型的实例,这样也能对我们的性能有一些提升。
从我们结合内外部客户实践的结果可以看到,大部分应用在经过我们的优化方案的组合以后、性能都能提升 30% 以上。
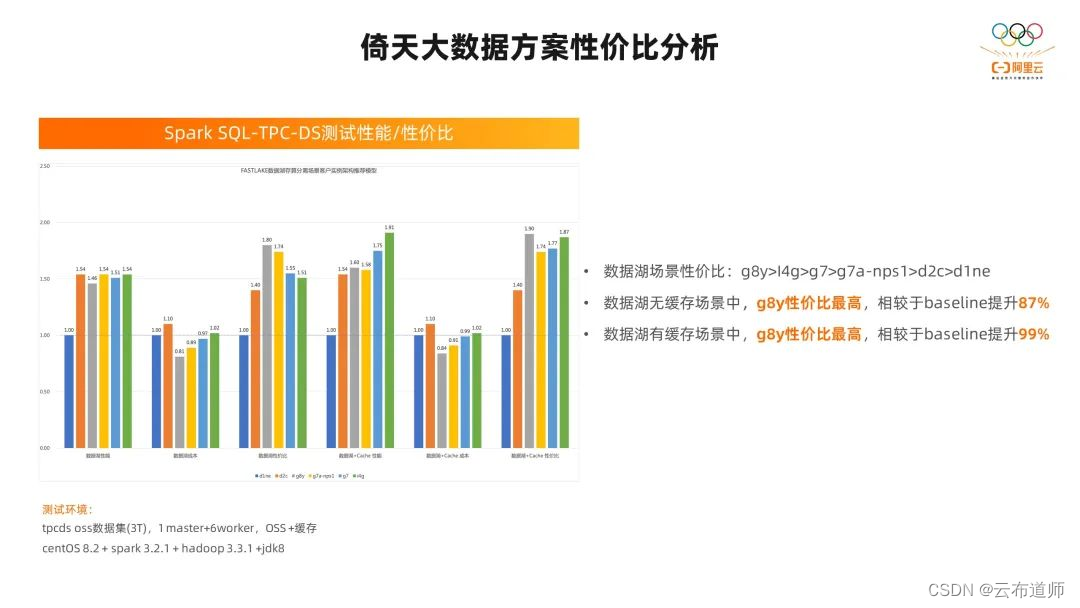
我们针对数据库存算分离的场景,做过一次性价比的评估模型。在模型的评测过程中,针对 TPC-DS3T 的性能和性价比做了测试,ECS 倚天实例 g8y 在所有评测性能的实例中性价比是最高的。在无缓存的场景里,它相对于 baseline性能提升了 87%;在有缓存的场景里,性能提升了 99%。
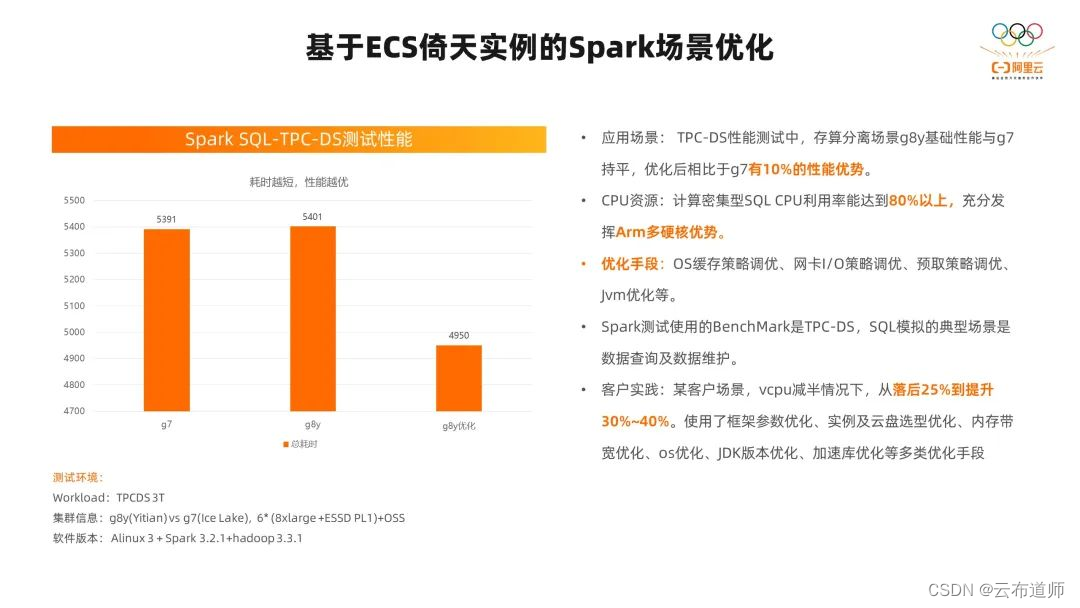
接下来我们在具体的场景中,看一看刚刚我们讲到的加速套件和优化手段的应用的情况。
在 Spark 场景,我们在 TPCDS 3T 的 1+6 的环境下测试了基础性能,我们在基础性能上,ECS 倚天实例基本上和 g7 实例是持平的。在测试过程中,我们发现计算密集型的 SQL,CPU 的利用率到达了 80% 以上,我们认为可以充分发挥倚天 ARM 架构的多硬核的优势。我们通过 OS 层面缓存策略的调优、网卡的调优、预取策略的调优,提升了 10% 以上的性能优势。
但我们也没有完全把刚刚讲到的所有优化手段都叠加在测试中,如果我们再叠加其他的优化手段,我们的性能还会有更高的性能表现。我们在客户的实践中应用了其他的优化手段,我们倚天 CPU 相比原 cpu 架构在核心数减少一半的情况下,从落后 25% 提升到了 30%~40%。
在这里我们使用了框架参数的优化,实例、云盘选型的优化,内存带宽的优化,OS 的优化,JDK 版本的优化,加速库的优化等等优化手段。可以看到,我们用的优化手段越多,ECS 倚天实例在 Spark 场景中的性能表现就会越好。
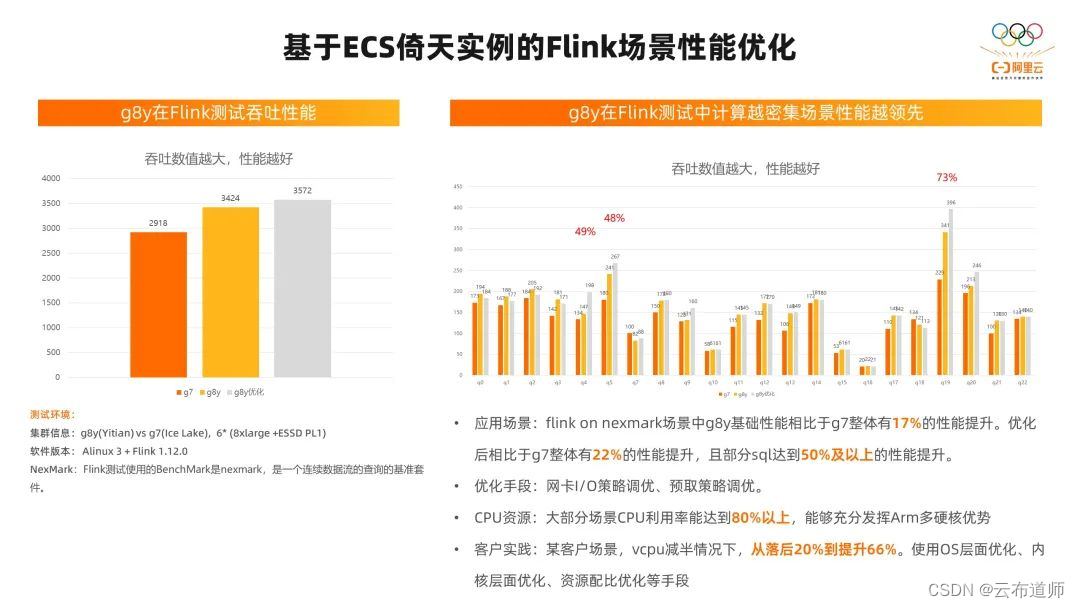
在 Flink 场景 nexmark 的测试中,我们使用了 6 个节点的集群。在这个场景的测试中,Flink 场景在基础性能里,相对 g7 已经有 17% 的性能提升了。通过网卡的 IO 策略的调优和预取策略的调优以后,相对 g7 就达到 22% 的性能提升了,且有一部分 SQL 达到了 50% 以上的性能提升。
在这个过程中,我们发现计算越密集的场景,性能就越好。在测试过程中,整个 CPU 的利用率能够达到 80% 以上。这里我们也和 Spark 一样,没有把所有的优化手段都用上。我们在其他的客户实践中,在核心数少一半的情况下,从落后 20% 提升到了 66%。我们在这里使用了 OS 层面的优化,内核层面的优化,资源配比的优化手段。
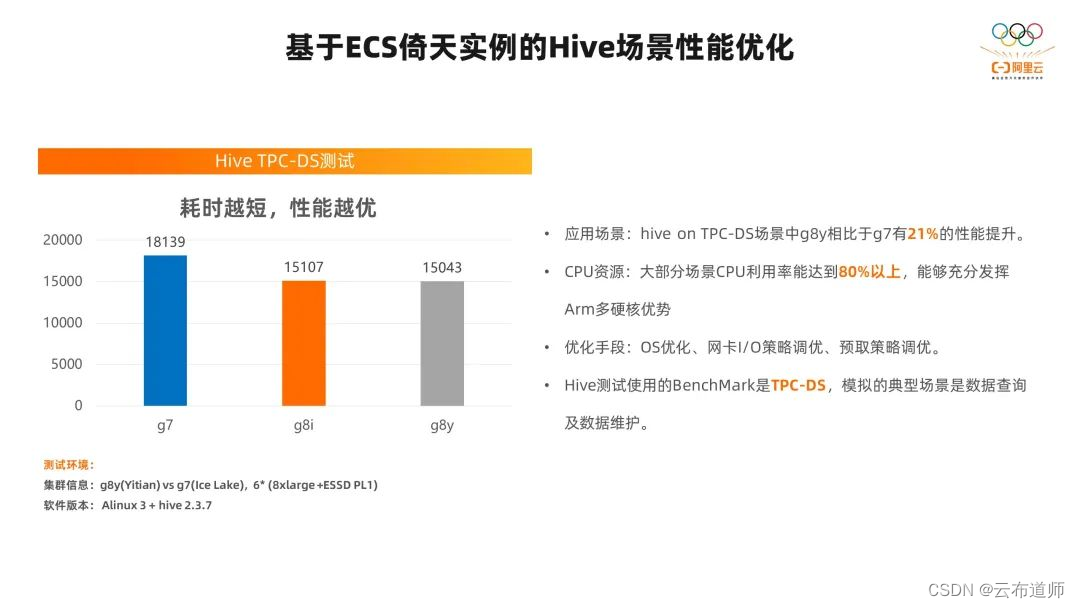
Hive 的场景优化也是一样,我们在 hive on TPC-DS 的测试中,我们发现 g8y 倚天实例相比于 g7 经有 21% 的性能提升。我们通过一些网卡的优化手段,大部分场景 CPU 利用率达到 80% 以上,基本和第八代 g8i 的性能持平。
通过刚刚讲的几个场景可以看到,在 Spark、Hive 的场景里,CPU 利用率都是非常高的,在 80% 以上。在这样的场景中,倚天有非常大的优势。我们通过一些简单的 OS 底层的、应用层完全无感的优化方法,就可以拿到相对于 X86 平台的很明显的性能收益。
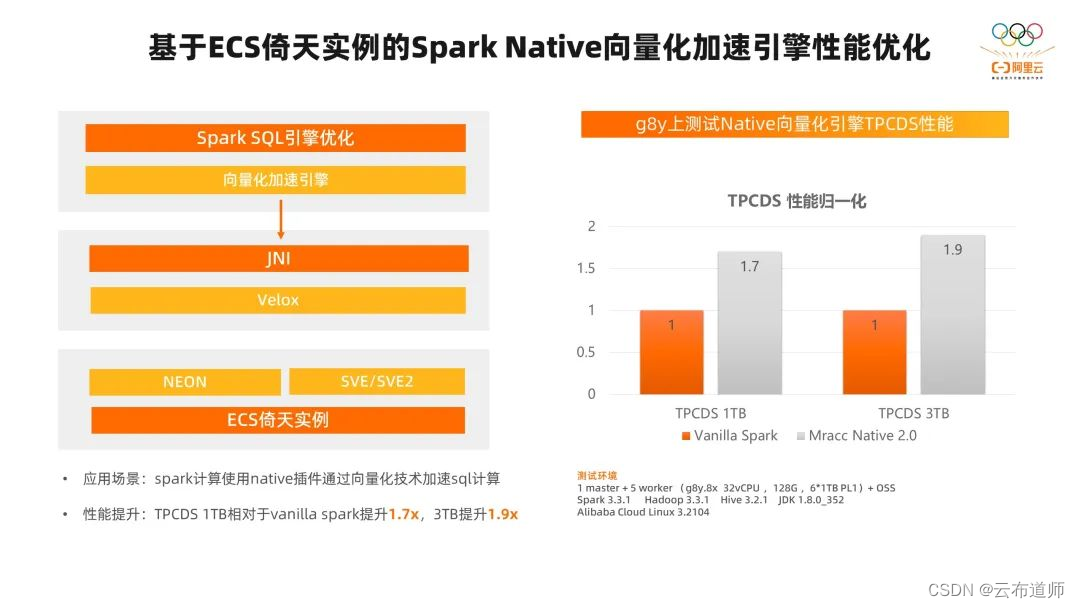
当然,为了更好的发挥倚天的性能优势,我们在大数据场景也针对应用层做了很多的性能优化。比如在 Spark SQL 场景,向量化加速也是非常流行的技术,databricks 也在做服务层的向量化加速。
我们针对 Spark SQL 场景基于 ECS 的 NEON 和 SVE/SVE2 的指令集适配了 Velox 的向量化引擎。我们针对 Spark SQL 引擎做了向量化的改造,在整个向量化的 SQL 引擎的测试中,我们在 TPCDS 的 1TB 测试集中,相对于原始的 Spark 提升了 1.7 倍,在 3TB 的测试中提升的 1.9 倍。
对于愿意尝试用 Native 引擎的客户来说,我们只需要把 Native 引擎在倚天 ARM 的架构上做一次编译,然后在配置文件里修改几行代码,就可以把整个引擎使能起来了,对于业务程序其实是可以做到零改造的。
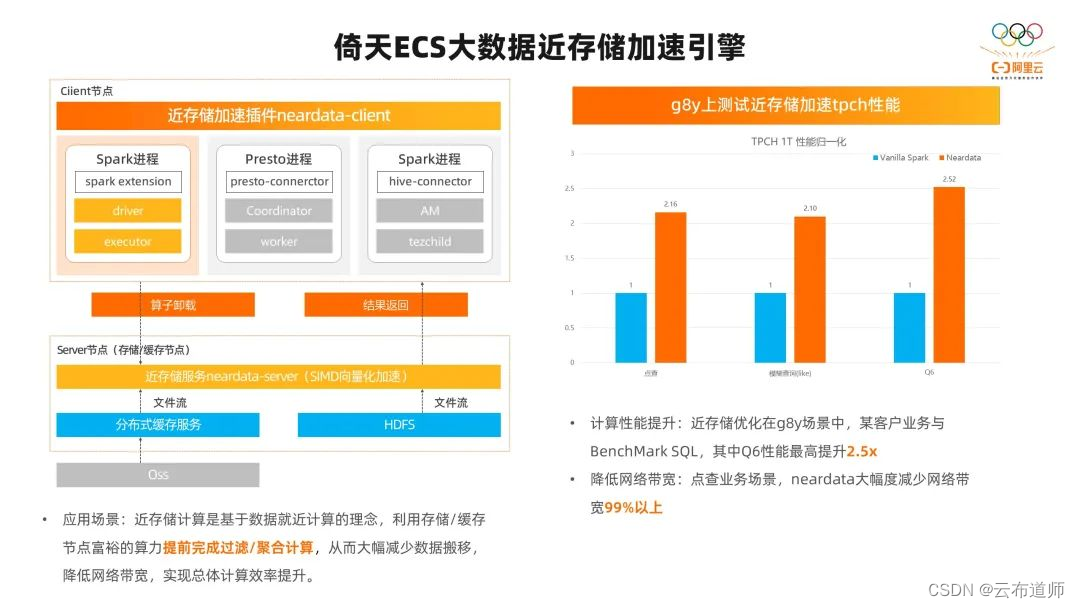
还有一种是前面提到的近存储加速的方案,在解决存算分离的架构中,我们一般会使用 OSS 或者远程的 HDFS 来存储数据,但计算集群和存储集群之间就会存在大量的数据交互和搬移。随着集群规模的扩大,两者之间的网络带宽就会逐渐成为瓶颈点。而且我们已经在一些客户的真实场景中碰到了这种问题。
而我们开发的近存储计算就是针对这个问题做的解决方案。它的原理是基于数据就近计算的理念,把计算搬到存储集群一部分,利用存储和缓存节点富余的算力提前完成过滤和聚合的计算。这样我们可以大幅度的减少数据的搬移,从而降低计算集群和存储集群之间的网络带宽的使用,实现整体的效率提升。
在这个架构图上大家可以看到,我们已经支持 Spark、Presto、Hive 的客户端,可以通过插件化的形式提供给客户来使用。我们把 Spark、Presto、Hive 的算子卸载到近存储服务端上。
在近存储服务端这里,我们也做了一些向量化的加速,和刚刚讲到的 Spark 向量化加速引擎里用到的 Velox 进行了整合,充分发挥 ARM 的 simd 指令集的优势进行高效的数据过滤和聚合的操作。在这样的架构中,我们在 tpch 1T 的测试中,在点查场景中,性能提升了 2.16 倍,在模糊查询的场景中,提升了2.1 倍,在 Q6 的 E2E 测试中,提升了 2.5 倍。在网络带宽减少的数据上,我们在点查场景降低了 99%。
近存储要使用起来也非常简单。首先需要在存储或者缓存节点上部署我们的存储服务。客户端只需要把插件通过配置文件的方式,配置到 Spark、Presto、Hive 的计算引擎里去,客户的 SQL 和客户的业务代码是不需要改造的。
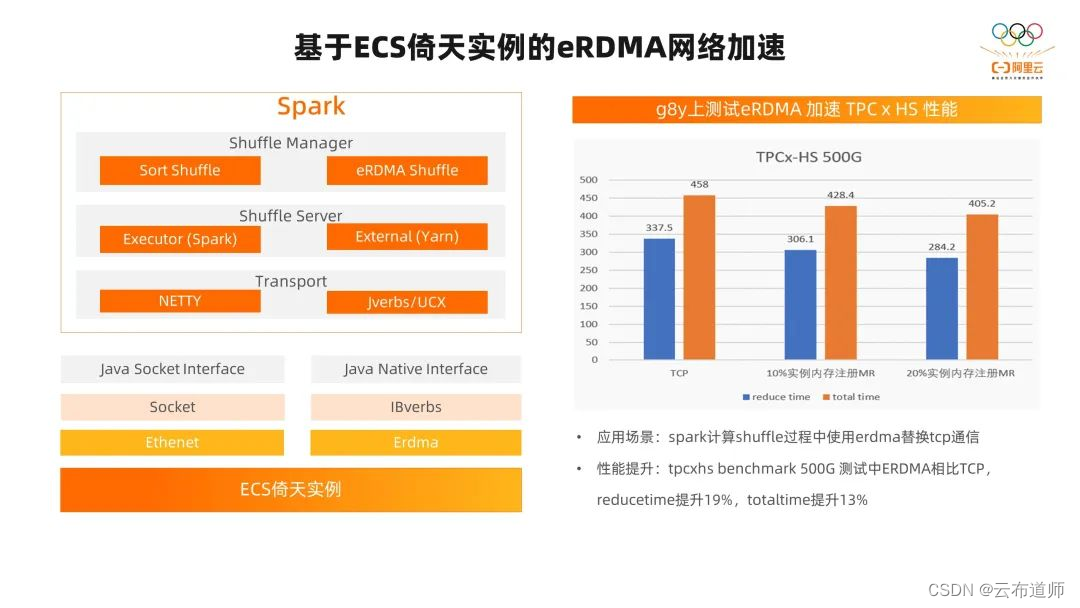
然后我们再看一下的 eRDMA 网络加速。前面我们提到 ECS 倚天实例搭载的是阿里云最新的 CIPU 计算架构,所以它能够提供 eRDMA 的能力。我们在 Spark Shuffle 的场景中,做了适配和优化,增加了 eRDMA Shuffle 的 Manager,并适配了 Spark Shuffle 和 Yarn 的 ECS 服务。
通信层我们通过 Jverbs 和 UCX 方案去适配兼容 eRDMA 的能力。将 Shuffle 整个过程中的网络从 TCP 替换为 eRDMA。在这里测试的 TPCx-HS 的 source 的 Benchmark 中,我们调整了一下 RDMA 的 memory region。在不同的情况下,在 reduce 阶段获取远端数据的过程中,提升了 19%。在 E2E 的测试中,提升了 13%。
倚天大数据场景落地实践
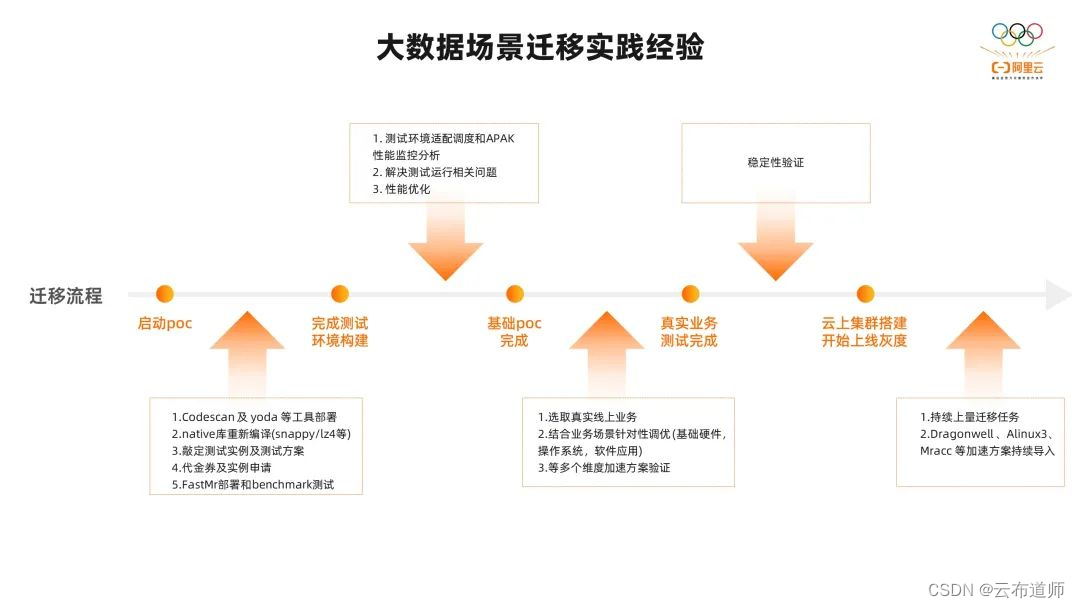
场景的客户迁移实践经验,总结了一下比较典型的大数据迁移的流程,大概包含五个步骤:
首先启动 POC,我们需要进行迁移适配的工作,包括对技术软件和应用软件兼容的扫描。对于不兼容的代码,我们需要重新编译或者 Jar 包的升级。在这个过程中,我们可以去设计测试的实例、测试的用例和测试方案。在这个基础上我们完成整个 POC 测试环境的构建,这里可以使用前面性能加速套件里面提到的 FASTMR 一键构建,并开始性能优化和加速导入,来得到最佳的性能。
这里我们可以将性能加速套件里提到的 APAK 监控和分析的工具进行部署,找到系统的瓶颈点,针对性的做一些优化方案。在 POC 结束以后,我们可以选取客户的一些真实的线上业务进行测试,针对业务自有的特点进行验证。也可以在这个过程中针对性的做一些优化,比如基础硬件的优化、OS 的优化、应用层的优化等角度验证一下优化方案的有效性。
在业务运行的稳定性验证以后,我们就可以开始真正的进行线上集群的构建和线上业务的灰度测试了。在持续上量的过程中,我们还可以不断地调整我们的优化方案,包括我们比较有特色的 JDK、OS、Spark 等等组件的引入和大数据业务的兼容适配。

在这个迁移的过程中,有一块业务的代码迁移是刚刚上面没有提到的,UDF 的迁移适配。这里补充一下,我们以阿里云 ODPS 的迁移实践经验为例,UDF 的任务在很多大数据客户的平台里面占比还是比较大的。这一类的任务的情况比较复杂,因为它的依赖也比较多。
针对这些 UDF 的任务我们需要进行分类的检测,再给出不同的迁移建议。我们把这个任务大概分成了五类:
第一类,完全兼容(jar/tar包)。我们建议直接进行验证,在倚天上跑一下,确定它的兼容性。
第二类,jar 包不兼容,开源 jar 版本升级。我们建议升级对应的 maven 仓库中兼容 ARM 版本的,并引入对应的 so。
第三类,jar 包不兼容,开源 jar 版本升级+开源库编译。我们建议升级 maven 仓库中兼容 arm 版本的,并引入对应的 so,然后重新编译开源代码仓库,提供兼容 arm 的 so。
第四类,python 库不兼容,重新编译对应的 python 库。我们建议重新编译对应的 python 库,或者搜寻编译好的 python aarch64 的依赖库安装包,通过安装获取对应的 so。
第五类,so 不兼容,无开源代码,业务方重新编译。我们建议推动业务方重新编译,在倚天实例上重新进行兼容性的验证。
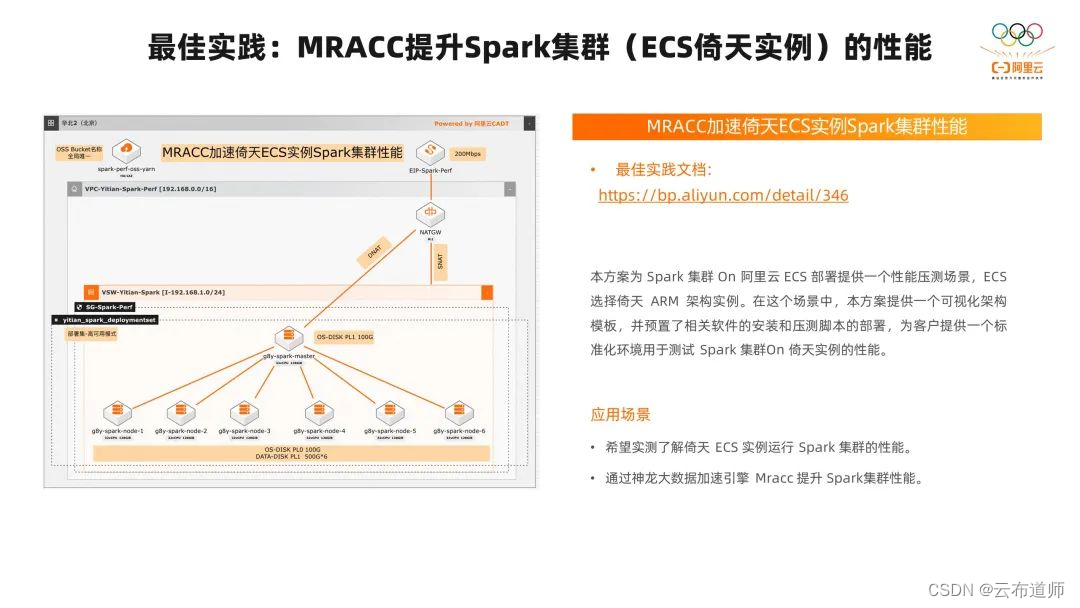
我们前面已经把大数据场景里在 ECS 倚天实例的迁移适配、性能优化、UDF 适配的工作都简单介绍了一遍,看起来还是比较简单的,可以做到比较平滑的迁移。但为了让用户能够更好的开箱启用,体验到刚刚讲到的适配和优化的成果。我们基于 ECS Boost 和 CADT 开发了 MRACC 加速和 ECS 实例 Spark 集群性能的最佳实践。
大家可以通过 http://bp.aliyun.com/detail/346 链接,看到一键就能拉起我们向左边图里介绍的 1 个 master+6个worker 的 Spark 集群。这里面我们也会把前面讲到的适配和推荐的版本以及性能优化的 OS 层面的优化、JDK 的优化、应用层面的优化、应用参数的优化,形成一个整体的优化方案。我们一键就能把这个集群开起来,运行里面提供的 TPCDS 的 benchmark 测试,快速拿到基于 ECS 倚天实例的大数据场景下 Spark 的最佳性能。
也可以根据这个性能结果和 X86 平台进行对比,这样我们就可以将整个迁移流程缩短到小时级别。我们也真实的希望客户通过这种方式快速了解 ECS 倚天实例在大数据场景 Spark 的性能的最佳体验,也可以通过这个来了解到神龙大数据加速引擎MRACC 在 Spark 提升的性能的最佳体验。
整个方案是可视化的架构模板,操作起来也是比较方便的,这里就不带大家操作了。大家可以通过文档上的链接进去,里面有一个比较详细的操作文档,可以根据这个文档进行实践。
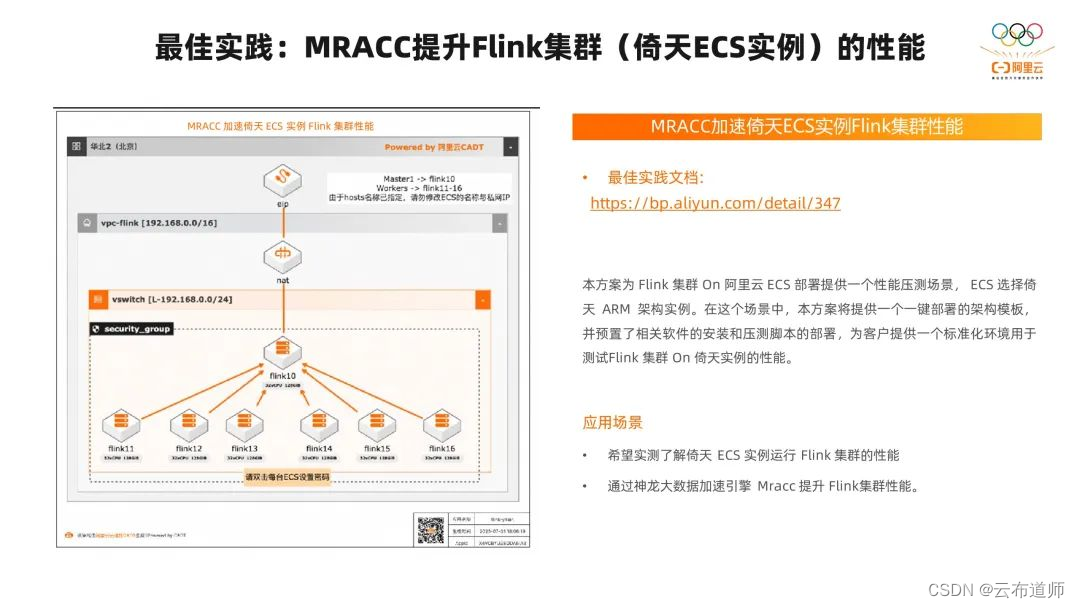
和 Spark 类似,我们也开发了一个 MRACC 加速 ECS 倚天实例 Flink 集群性能的最佳实践。根据这个文档我们也可以一键拉起一个 1+6 的 Flink 的集群,并在里面运行 nexmark 的测试。同样我们也会在这里面与预置前面讲到的性能优化的点,客户可以一键拉起以后开箱即用,快速的验证 MRACC 加速倚天 ECS 实例 Flink 集群性能。
和 Spark、FLink 类似,我们也有针对其他的大数据组件的最佳实践,比如 Kafka、ES,欢迎大家试用。以上就是本次课程的全部内容,想要关注更多【倚天实例迁移课程】直播的同学可以扫描下方二维码进入活动官网了解更多资讯!



















 881
881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









