






云布道师
图片压缩是阿里云对象存储图片处理业务中的一个重要算子,它在图片处理业务中占据了很大的比重。为了节省流量,降低传输延迟,主流的互联网应用的图像,通常会被转码成某种压缩格式后才会传输到终端设备上显示。自互联网诞生以来,为了满足用户的应用需求,图片格式一直处于不断的迭代演进中。
引言
早期的图片格式的演进是为了满足各种不同的互联网应用的需求(比如 GIF 是为了支持动图、JPEG2000 是便于图片的渐进显示)。PNG 和 JPEG 等早期的压缩格式标准只由图片所持有,对压缩效率的追求没有那么极致,压缩算法较为简单。随着多媒体在互联网上的爆炸式增长,用户越发迫切地追求极致的压缩效率,2010 年业界开始使用基于 VP8 的视频压缩标准来压缩图片,由此产生了 WEBP 格式,从此基于HEVC 视频标准的 BPG、HEIC 和基于 AV1 视频标准的 AVIF 压缩格式不断推陈出新,直到今天基于 AV2 和 VVC 的压缩格式仍然在酝酿中。下图列举了各种压缩格式相对于 JPEG 格式的体积比较:
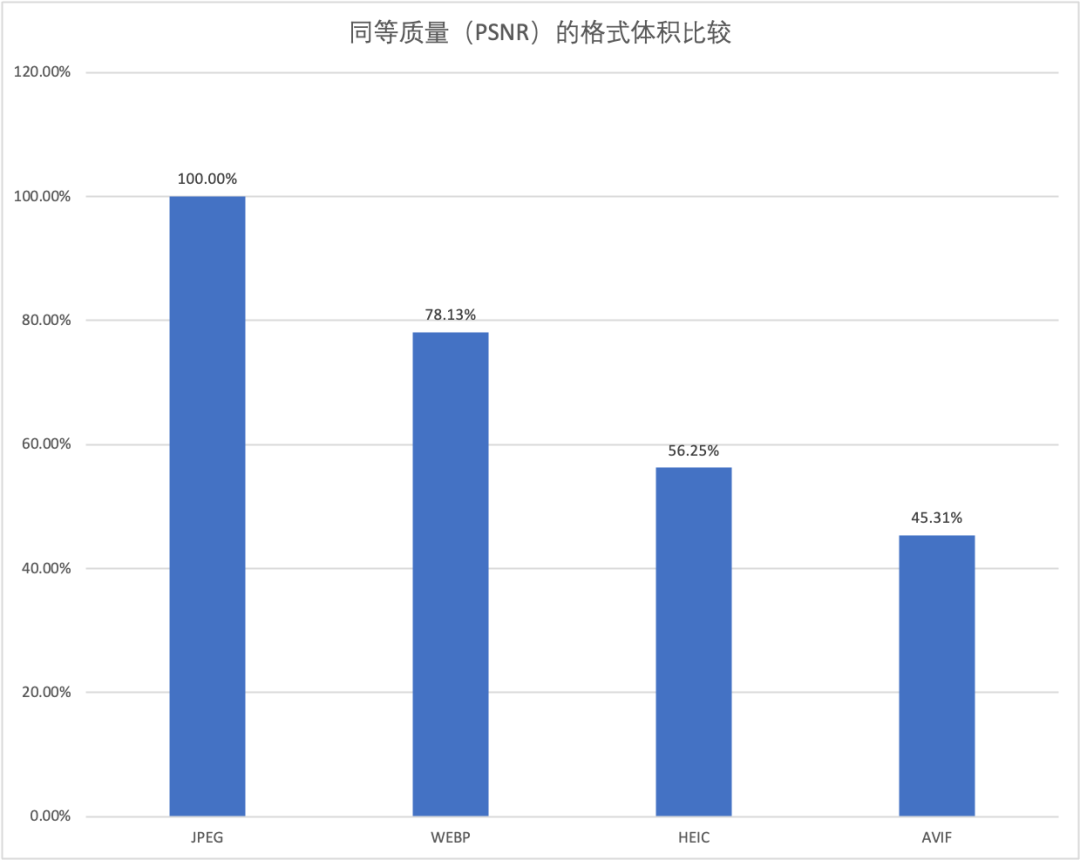
图1 不同格式的图像的体积比较
从上图中可以看出每一代格式较前一代有 20% 以上的压缩效率提升,但是伴随而来的是编码计算复杂度的指数级别提升,下图列举了各个格式相对于 JPEG 压缩格式的编码复杂度情况:
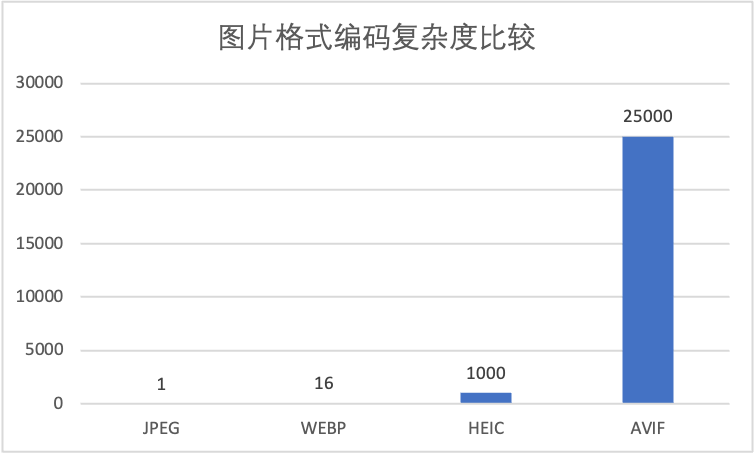
图2 不同格式的图像的编码时间复杂度比较
为了满足用户对于实时高质量压缩的需求,智能存储图片服务团队近年来依次支持了基于 FPGA 硬件的 WEBP、HEIC 和 AVIF 的转码服务,使得用户在使用算力要求极高的高级压缩格式的同时,仍然能维持较低的成本和延迟。
我们的用户对于图片压缩效率的追求是永无止境的,通常情况下,采用更先进的压缩标准能够获得压缩率的线性提升,但是为此我们需要付出指数级别的算力代价。除此之外,一个标准从提案到定稿到整个生态的良好支持最低也需要数年的时间。因此,图片压缩效率的提升不能只局限和依赖于压缩标准本身的技术提升,必须结合实际应用,另辟蹊径。在诸多标准之外可以提升图片压缩主观质量的技术中,考虑人眼视觉特性,研究面向人眼感知主观评价的图像压缩优化是一个重要主流可行的研究方向。该方向研究主要包括选择合适的更加面向主观感知的图片压缩质量评价指标以及有效的图片压缩预处理算法。下面分别对这两者进行概述介绍。
图像压缩质量的评价标准
尽管 JPEG、WEBP、HEIC 和 AVIF 也具有无损压缩的能力,但是为了追求更高的压缩效率,大多数互联网应用采用有损压缩的配置,有损图像压缩格式的图像解码后跟原始输入图像不能每个像素值都相同,因此必然造成一定的质量损失,目前主流的质量损失的评价主要有 PSNR、SSIM、MS-SSIM 和 VMAF
PSNR
峰值信噪比(Peak Signal to Noise Ratio),它常简单地透过均方误差(MSE)进行定义。两个 m×n 单色图像 I 和K, I 为原始图像,K 为 I 压缩后的图像,那么它们的均方误差定义为:
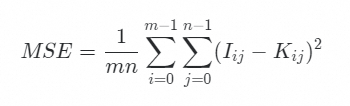
对于 8 比特的颜色分量,PSNR 定义为:
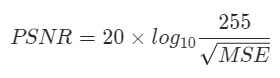
由上面的计算过程可以看出 PSNR 的计算仅仅考虑的是平均每个像素点的误差。PSNR 直观地表达了信号强度与噪声强度的比值,数值越大通常意味着失真越小,图像质量越高。然而,PSNR 作为客观评价指标,往往与人眼主观感知存在偏差,尤其是在高压缩率下,即使 PSNR 值较低,人眼可能仍无法察觉到明显的质量差异
SSIM
结构相似性指标(英语:structural similarity index,SSIM index),对于一幅图像,每个点的 SSIM 值计算公式如下:
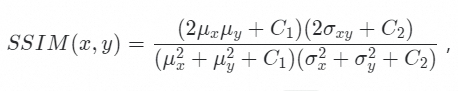
其中及
、
和
分别为 x 和 y 的平均值和标准差,
为 x 和 y 的协方差,C1 和 C2 为常量。
在计算两张图像的结构相似性指标时,会开一个局部性的视窗,一般为 N × N的小区块,计算出视窗内信号的结构相似性指标,每次以像素为单位移动视窗,直到整张图像每个位置的局部结构相似性指标都计算完毕。将全部的局部结构相似性指标平均起来即为两张图像的结构相似性指标。
SSIM 通过考虑图像的局部特征相关性,提供了一个更接近人眼视觉感知的质量评价
MS-SSIM
多尺度结构相似性指数(Multi-Scale Structural Similarity Index)是 SSIM 的扩展,它在计算相似度时引入了多个空间分辨率,从而更好地模拟人眼在不同尺度下的视觉特性。MS-SSIM 先对图像进行高斯金字塔分解,然后在每个尺度上计算 SSIM值,并最终通过加权平均得到整体的相似度得分。这种方法提高了对图像质量评价的精度,尤其是在评估包含多种频率特征的图像时
VMAF
视频多方法评估融合(Video Multi-method Assessment Fusion)【1】最初由 Netflix 开发,用于视频质量评估,但同样适用于静态图像。VMAF 综合考虑了多种图像质量特征,如细节保留、块效应、模糊度和色彩保真度,通过机器学习模型对这些特征进行加权融合,以预测人眼对图像质量的主观评分。VMAF 分数通常介于 0 到 100 之间,分数越高表示质量越好,该模型经过大规模主观实验数据训练,能更准确反映人类视觉系统的感知质量。VMAF 的计算流程如下:
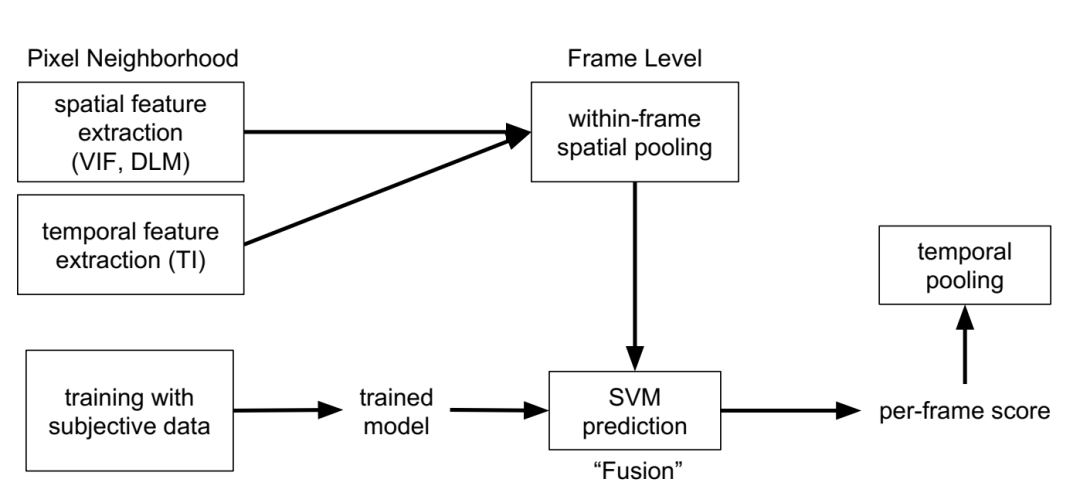
图3 VMAF 的计算流程
综上所述,随着技术的发展和人们对图像质量要求的提高,评价标准逐渐从单一的客观指标如 PSNR 过渡到了更能体现人眼视觉感受的主观相关指标,如 SSIM、MS-SSIM 和 VMAF。这些进步不仅推动了图像压缩技术的优化,也为实现更高效、更贴近用户感知的图像处理提供了理论基础。未来,结合深度学习等先进技术的新型评价体系有望进一步提升图像压缩质量评估的准确性和实用性。
面向人眼感知的图像编码算法
首先,研究发现,传统图片压缩评价下,图片压缩后的主观效果与客观指标会出现差异。比如,对于 kodak 数据集【2】的 kodim13.png 和 kodim04.png,分别采用如下相同的质量参数进行 webp 压缩:
cwebp -q 40 kodim13.png -o kodim13-q40.webpcwebp -q 40 kodim04.png -o kodim04-q40.webp
压缩结果表明,其 kodim13-q40 和 kodim04-q40 的 PSNR 分别为 33.36dB 和36.54dB。从 PSNR 上来看,显然,kodim04 的压缩质量是更高的,然而,当我们观察实际压缩后的图像,进行对比如下所示:

图4 左:kodim13.png 右:kodim13-q40.webp

图5 左:kodim04.png 右:kodim04-q40.webp
可以看到,我们不是太容易区分 kodim13 压缩前后的质量差异,但是对于kodim04 我们能很容易看出压缩后的帽子上的方格模糊了,有一些头发也消失了,同时人脸以及肩膀上出现了明显的磨皮效果。所以对于 kodim13 来讲,使用 quality 为 40 的参数已经足够,但是对 kodim04 需要提高 quality 参数。
所以,可见传统客观图片压缩技术难免会对有的图片压缩得到过高的客观质量,但并不一定会提升主观质量且可能导致压缩率更低(更大的 PSNR 通常意味着压缩后的图片文件更大)。除此之外,传统的客观图片压缩技术没有充分考虑到人眼观察图片的视觉感知特性,即无法根据图片内容自适应地对不同图片、不同区域获取符合人眼感知质量的压缩性能。
因此,我们通过分析图像的内容,考虑到人眼视觉感知特性,研究面向人眼主观的质量调节,以提升图片压缩的主观质量和压缩性能。为达到该目标,我们采用两种方法对图片压缩进行优化。第一,是选择合适的编码压缩参数,通过基于感知的自适应量化调节技术,在保证压缩率的前提下,产生人眼主观质量更优的压缩图像。第二,研究基于主观的图片预处理算法,包括图片增强等,在保证主观质量尽量不受损失的前提下,可以进一步提高图像的压缩率。如下图所示,简述了图片主观优化编码的过程。即原始图像先会进入图像分析模块,分析模块根据用户的输入参数产生图像增强(用户可选择跳过图像增强)的输入参数和图像编码模块的输入参数,最后图像编码模块将增强后的图像按照图像分析产生的参数进行压缩编码生成最终的压缩后的图像。
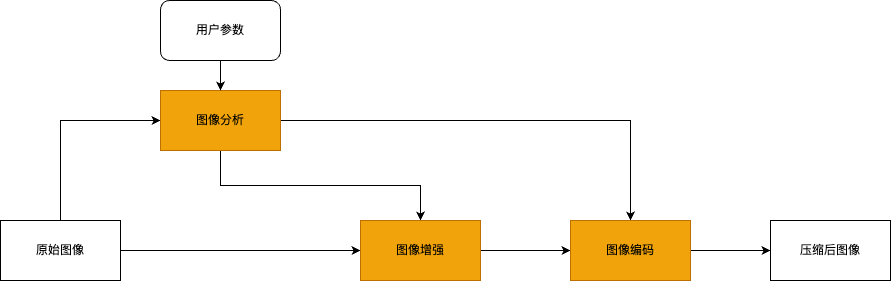
图6 主观质量调节算法流程
下面分别介绍这两个不同模块的算子算法原理及效果。
基于感知的自适应量化调节图片编码
在一幅图像中,人眼对不同区域内容的压缩失真感知行为是不同的。在纹理比较丰富的地方,压缩失真不容易被感知,比如茂密的丛林、草地等;反之在简单或平坦的区域,如果出现压缩失真是很容易引起人眼察觉。可见,对整幅图像采用固定相同的压缩程度,可能不利于获取最好的主观编码性能。因此,我们研究基于感知的自适应量化条件算法,以根据图片不同区域内容,自适应的调整压缩强度,以获得更好的压缩主观质量。比如,对失真敏感区域使用较低的压缩率(QP)以保持更高的质量,而失真不大敏感的区域则可以使用较高的压缩率(QP)。
例如对于以下的输入图像 kodim10.png:

图7 人眼感兴趣区域输入图像
通过基于感知的自适应量化算子模块可以得到该图像的 QP MAP(越暗的部分表示越低的 QP):

图8 人眼感兴趣区域的 QP MAP
从该 QP MAP 上来看,图像分析调低了对人眼敏感的区域(例如船帆)的 QP,调高了对人眼不敏感区域(例如船体和海浪)的 QP。因而,从整体上有利于提升图片压缩后的人眼主观感知质量。
下图是开关人眼感兴趣区域压缩编码算法的效果比较图:

图9 左:主观优化关闭(20KB) 右:主观优化开启(18KB)
可以看出主观优化开启后的船帆上的细线更清晰了,并且编码后的图像要比关闭主观优化的图像小 10%左右。我们在大量的数据集上做了测试,平均的图像体积要比关闭主观优化的版本小 10%左右。该算法跟图像的内容有密切关系,不能保证所有的图像经过该算法的处理都能得到体积更小的图像,但是通常会对整体图片主观质量有所改善
基于感知的自适应质量增强图片编码
自适应质量压缩编码是通过分析图像的内容,根据人眼的主观敏感程度,智能选择合适的增强参数,对输入图像进行增强,同时调节编码器的量化参数,在保证图像主观质量的同时,能够使得压缩后体积进一步减小。经过在内部数据集上的评测,该算法在保持 VMAF 分不降低的前提下,可以实现码率 20%的节省。该算法在使用越高的 quality 参数时的效果越好,因此推荐在较高 quality 时使用。
下图是自适应质量压缩编码开启和关闭的效果对比的例子:

图10 左:未开启自适应(17.3KB)右:开启自适应(12.7KB)
通过对比我们可以看出,自适应质量压缩编码算法开启前后的图像质量并没有明显变化,但是图像体积明显缩小,即可以进一步提升图片压缩性能。
主观优化编码的调用方法
目前在图片服务的 AVIF 高级压缩产品中,我们已经开启主观优化编码算法公测,用户可以提工单联系图片服务团队针对相应 bucket 开通主观优化编码,开通后可通过在 url 中添加特定 x-oss-process 参数调用相应算法,demo 示例如下:
未来展望
一方面,随着互联网上图像格式技术的持续革新与蓬勃发展,智能存储图片服务团队致力于紧密跟随国际标准的演进步伐,不断集成并优化最前沿的压缩技术,以确保图像处理解决方案的领先地位和标准兼容性。这一举措旨在通过采用最新一代的图像编码标准,实现图像数据的高效存储与传输,同时最大化视觉质量,从而在技术层面上促进图像内容的高质量传播。
另一方面,针对用户需求的多元化与个性化趋势,我们将深化主观感知优化策略,通过创新升级的自适应编码算法,来精细化满足不同用户的特定需求。具体而言,我们将继续研究更加高效的面向人眼视觉感知的图片编码优化技术,包括但不限于 ROI (感兴趣区域、Region of Interest)编码技术、自适应滤波降噪、图片超分技术等。另外,随着图片应用需求越来越多和应用场景越来越复杂,除了这些技术之外,我们会研究其他结合应用技术,这包括但不限于开发针对性的保护机制,如采用先进的文本保真度增强技术以维护文字信息的清晰度,以及部署智能人脸识别与保护算法,来减少对人脸图像质量的影响,确保用户隐私与体验的双重优化。我们的目标是通过这些技术的融合应用,构建一个高度灵活且用户导向的图像处理平台,精准满足用户在不同应用场景下的独特诉求,进而推动数字媒体体验的全面升级。
【1】https://github.com/Netflix/vmaf
【2】https://www.kaggle.com/datasets/sherylmehta/kodak-dataset


















 1110
1110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}