







1.时间复杂度
(1)时间复杂度分析统计的不是算法运行时间,而是算法运行时间随着数据量变大时的增长趋势。
2.函数渐进上界
def algorithm(n: int):
a = 1 # +1
a = a + 1 # +1
a = a * 2 # +1
# 循环 n 次
for i in range(n): # +1
print(0) # +1在上述代码中,疑惑的点是a=a*2,在上文中不是有说明乘法时,其时间复杂度为10*n吗,为什么在这里变成1n了???
我们将线性阶的时间复杂度记为 𝑂(𝑛) ,这个数学符号称为大 𝑂 记号(big-𝑂 notation),表示函数 𝑇(𝑛) 的渐近上界(asymptotic upper bound)。
若存在正实数 𝑐 和实数 𝑛0 ,使得对于所有的 𝑛>𝑛0 ,均有 𝑇(𝑛)≤𝑐⋅𝑓(𝑛) ,则可认为 𝑓(𝑛) 给出了 𝑇(𝑛) 的一个渐近上界,记为 𝑇(𝑛)=𝑂(𝑓(𝑛)) 。---------不理解
3.时间复杂度求解
T(n)是操作数量,f(n)是渐进上界。f(n)的求解中,第一步是T(n)的确定,第二部是根据忽略系数和常数项的影响后的最高阶的项来决定。--------(有点绕)
总结一下:
- 忽略 𝑇(𝑛) 中的常数项。因为它们都与 𝑛 无关,所以对时间复杂度不产生影响。
- 省略所有系数。例如,循环 2𝑛 次、5𝑛+1 次等,都可以简化记为 𝑛 次,因为 𝑛 前面的系数对时间复杂度没有影响。
- 循环嵌套时使用乘法。总操作数量等于外层循环和内层循环操作数量之积,每一层循环依然可以分别套用第
1.点和第2.点的技巧。
两种T(n)确定方法对比:
(1)之前的方法----T(n)=12n^2+44n+8(这个算的不对!!!!)
正确的是T(n)=2n(n+1)+(5n+1)+2
def algorithm(n: int):
a = 1 # +1
a = a + n # +1
# 30n+6
for i in range(5 * n + 1): # 1
print(0) # 5
# (6(n+1)+1)*2n = 12n^2+14n
for i in range(2 * n): # 1
for j in range(n + 1): # 1
print(0) # 5(2)根据3条准则后的方法-----T(n)=n^2+n
def algorithm(n: int):
a = 1 # +0(技巧 1)
a = a + n # +0(技巧 1)----这里我不懂为什么是+0,而不是n,是因为将n看为常数项了吗?
# +n(技巧 2,不管循环多少n次,都记为n)
for i in range(5 * n + 1):
print(0)
# +n*n(技巧 3,嵌套循环就相乘,n*n)
for i in range(2 * n):
for j in range(n + 1):
print(0)通过T(n)中最高阶的项来决定,在本案例中时间复杂度为O(n^2)
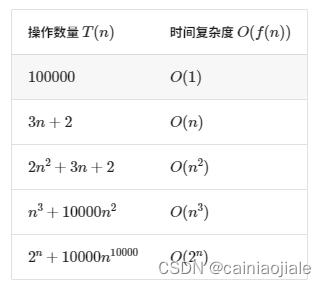
4.常见类型的时间复杂度
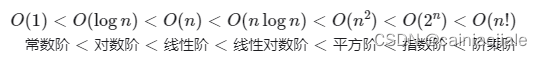
(1)常数阶:在for循环中,如果范围为常数,仍为常数阶。---range(1000)
(2)线性阶通常出现在单层循环中,循环range(n)。
遍历数组和遍历链表等操作的时间复杂度均为 𝑂(𝑛) ,其中 𝑛 为数组或链表的长度
(3)平方阶 𝑂(𝑛2):平方阶通常出现在嵌套循环中,外层循环和内层循环的时间复杂度都为 𝑂(𝑛) ,因此总体的时间复杂度为 𝑂(𝑛2)
(4)指数阶 𝑂(2^𝑛):生物学的“细胞分裂”是指数阶增长的典型例子-------【递归】
(5)对数阶 𝑂(log𝑛):对数阶反映了“每轮缩减到一半”的情况------与上一个相反(递归中也有)
对数阶常出现于基于分治策略的算法中,体现了“一分为多”和“化繁为简”的算法思想。它增长缓慢,是仅次于常数阶的理想的时间复杂度。
(6)线性对数阶 𝑂(𝑛log𝑛):线性对数阶常出现于嵌套循环中,两层循环的时间复杂度分别为 𝑂(log𝑛) 和O(n)
主流排序算法的时间复杂度通常为 𝑂(𝑛log𝑛) ,例如快速排序、归并排序、堆排序等。
(7)阶乘阶 𝑂(𝑛!):给定 𝑛 个互不重复的元素,求其所有可能的排列方案。阶乘通常使用递归实现。
5.最差、最佳、平均时间复杂度
“最差时间复杂度”对应函数渐近上界,使用大 𝑂 记号表示。相应地,“最佳时间复杂度”对应函数渐近下界,用 Ω 记号表示;平均时间复杂度可以体现算法在随机输入数据下的运行效率,用 Θ 记号来表示。















 1450
1450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









