







读取CSV文件为DataFrame对象
-
使用read_csv()方法读取csv数据成为DataFrame对象:
import pandas as pd # pd.read_csv('路径')读取csv文件 data = pd.read_csv('../data/nobel_prizes.csv') # 打印数据 print(data) # DataFrame的head()方法 获取前5条数据 data.head()
-
发现数据有id读出的数据还是生成了索引,所以读取的时候以id为索引:
# index_col='以xx字段为索引' data = pd.read_csv('../data/nobel_prizes.csv',index_col='id')
-
获取到DataFrame中的一条Series数据:
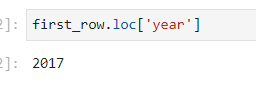
同样Series可以使用loc属性获取到key的value值# loc属性 data.loc[索引值] first_row = data.loc[941] first_row.loc['year']
Series和Dataframe的常用属性
- index和values属性
# 获取Key索引
Series.index
# 获取value值
Series.values

- size属性
# 获取数据中元素的数量
first_row.size
- shape属性
# 获取数据的维度
first_row.shape
data.shape

- T属性,反转矩阵
一维数组反转了矩阵还是一样
data.T
first_row.T


- 根据下标取子集
data.iloc[下标]

常用属性:
| 属性 | 说明 |
| loc | 使用索引值取子集 |
| iloc | 使用索引位置取子集 |
| dtype或dtypes | Series内容的类型 |
| T | Series的转置矩阵 |
| shape | 数据的维数 |
| size | Series中元素的数量 |
| values | Series的值 |
Series和Dataframe的常用方法
- mean()方法 获取平均值
# 获取到data数据中share这一列 获奖人数
share = data['share']
# 获取到这一列的平均值
share.mean()
- max() 获取最大值
share.max()
- min() 获取最小值
share.min()
- std() 计算标准差
share.std()
numpy中标准差(方差的平方根)和方差的计算:
数组的所有元素都减去平均值再开平方加起来算出平均值的平方根就是标准差

-
value_counts()获取不同值的数量

-
count()返回一列中非空的值的数量,如果是DataFrame对象使用count()会返回所有列的非空值的数量

- describe()打印描述信息

常用的方法:
| 方法 | 说明 |
| append | 连接两个或多个Series |
| corr | 计算与另一个Series的相关系数 |
| cov | 计算与另一个Series的协方差 |
| describe | 计算常见统计量 |
| drop_duplicates | 返回去重之后的Series |
| equals | 判断两个Series是否相同 |
| hist | 绘制直方图 |
| isin | Series中是否包含某些值 |
| min | 返回最小值 |
| max | 返回最大值 |
| mean | 返回算术平均值 |
| median | 返回中位数 |
| mode | 返回众数 |
| quantile | 返回指定位置的分位数 |
| replace | 用指定值代替Series中的值 |
| sample | 返回Series的随机采样值 |
| sort_values | 对值进行排序 |
| to_frame | 把Series转换为DataFrame |
| unique | 去重返回数组 |















 1349
1349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









