







class Solution {
public:
vector<TreeNode*> splitBST(TreeNode* root, int V) {
vector<TreeNode *> res(2, NULL);
if(root == NULL) return res;
if(root->val > V){
res[1] = root;
auto res1 = splitBST(root->left, V);
root->left = res1[1];
res[0]=res1[0];
}else{
res[0] = root;
auto res1 = splitBST(root->right, V);
root->right = res1[0];
res[1] = res1[1];
}
return res;
}
};
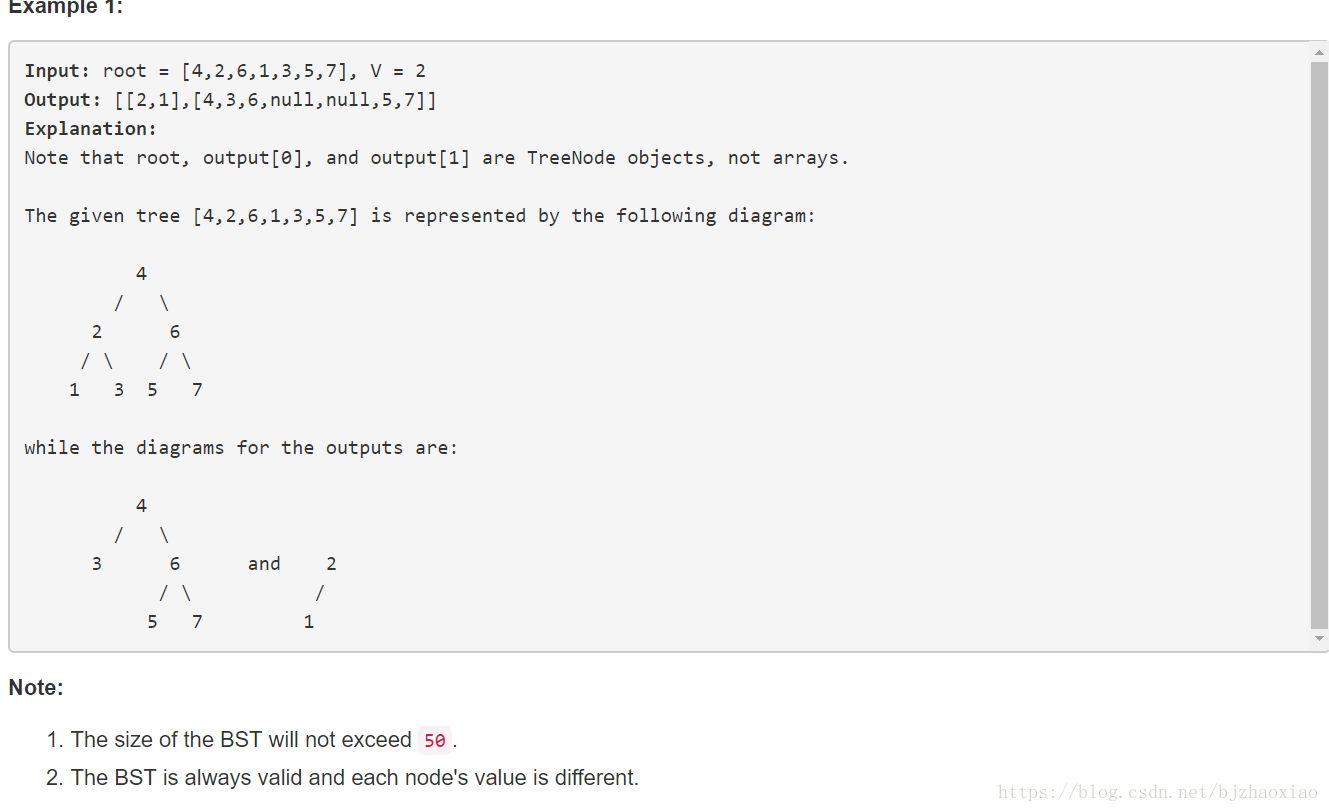
776. Split BST
最新推荐文章于 2021-04-09 08:40:45 发布















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









