







前言
在网络上传输的数据总是以字节为单位,Java NIO使用ByteBuffer作为字节的容器,使用起来比较繁琐与复杂。Netty使用ByteBuf作为ByteBuffer的替代品,但又具备ByteBuffer的功能且功能更强大。
ByteBuf
ByteBuf将会是使用Netty框架开发网络程序中使用频率较高的工具之一;Netty的数据处理通常由ByteBuf与ByteBufHolder这两个组件完成。下面先来看看ByteBuf的一些优点:
- 通过内置的复合缓冲区类型实现了透明的零拷贝
- 容量可以按需要增长
- 在读与写两种模式之间切换不需要像ByteBuffer一样需要调用flip方法,读与写模式之间使用不同的索引
- 支持方法之间的链式调用
- 用户可以自定义扩展缓冲区类型
- 支持池化
- 支持引用计数
ByteBuf维护了两个不同的索引,一个是读索引(readIndex)一个是写索引(writeIndex),调用read开头的方法时readIndex将会增加,调用write开头方法时writeIndex将会增加。
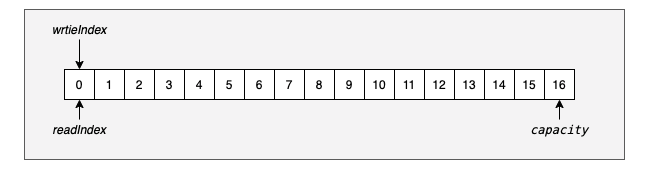
这是一个初始大小为16bit的ByteBuf中writeIndex、readIndex、capacity的使用情况,在ByteBuf中这三个变量的关系是0<=readIndex<=writeIndex<=capacity。
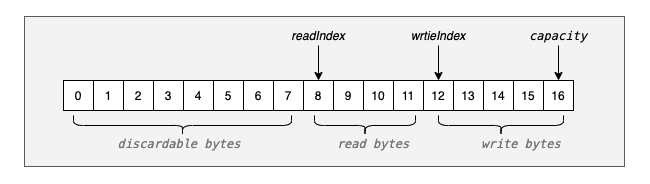
我们考虑下,如果readIndex==writeIndex时继续读取数据会出现什么情况?如果继续读将会读取到写入的数据,所以writeIndex-readIndex就相当时最大可读的字节数,在ByteBuf中readIndex ==writeIndex时再继续读就会出现IndexOutOfBoundsException异常,另外没有在图中体现的还有一个变量maxCapacity,代表ByteBuf的最大容量,当写操作超过这个值时将会提示一个异常,默认的限制是Interge.MAX_VALUE。在图中还有一个变量capacity,这个表示当前容量。
堆缓冲区、直接缓冲区与复合缓存冲区
ByteBuf分为两个缓存区模式:堆缓冲区与直接缓冲区;堆缓冲区中将缓冲的数据存放在JVM堆内存中,这种模式也被称为支持数组,内部使用byte[]存储数据,对于缓冲区的扩容使用System.arrayCopy操作,这个模式的优点在于可以在没有使用池化技术的情况下快速分配和释放内存,下面通过示例来看看如何使用:
//分配一个非池化的buffer
ByteBuf buf = Unpooled.buffer(16);
//通过hasArray方法判断Buf的类型是堆缓存区还是直接缓冲区
System.out.println(buf.hasArray() ? "ByteBuf is heap buf." : "ByteBuf is direct buf");
//获取堆缓冲区中的数据
byte[] array=buf.array();
如果是直接缓冲区在尝试调用buf.array()方法获取缓冲数组时会得到一个UnsuppertedOperationException的异常。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 475
475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









