







一、从前馈神经网络到CNN
前馈神经网络(Feedforward Neural Networks)是最基础的神经网络模型,也被称为多层感知机(MLP)。
它由多个神经元组成,每个神经元与前一层的所有神经元相连,形成一个“全连接”的结构。每个神经元会对其输入数据进行线性变换(通过权重矩阵),然后通过一个非线性函数(如ReLU或Sigmoid)进行激活。这就是前馈神经网络的基本操作。
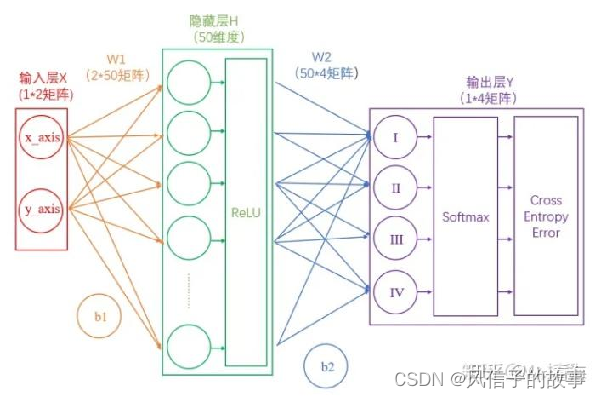
然而前馈神经网络也会产生问题:如果加深网络层,全连接神经网络随着隐藏层和隐藏节点的增加,参数的增加量是十分巨大的。正是因为这些大量的参数,使得神经网络模型有着极强的学习能力,导致计算困难。
很大程度上,是CNN的基本组成部分与前馈神经网络有很紧密的关联,甚至可以说,CNN就是一种特殊的前馈神经网络。
这两者的主要区别在于,CNN在前馈神经网络的基础上加入了卷积层和池化层(下边会讲到),以便更好地处理图像等具有空间结构的数据。

CNN在前馈神经网络的基础上加入了卷积层和池化层
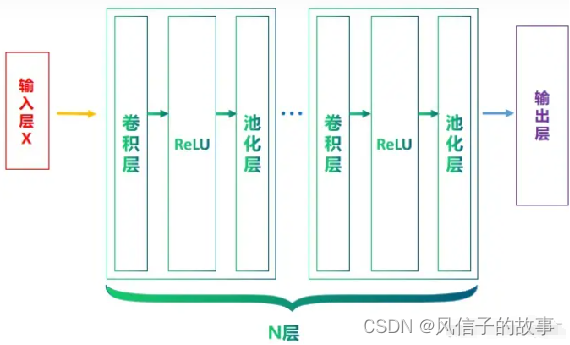
所谓深度学习,不就是层数比较多的神经网络嘛,那为什么不能使用一种几十层的前馈神经网络,而要设计一个所谓的卷积神经网络呢?接下来我们来学习卷积神经网络模型。
二、卷积神经网络(CNN)介绍
卷积神经网络(CNN)是一种高效的深度学习架构,用于图像和视频识别、分类等任务。CNN通过局部连接、权重共享和自动特征提取等特点减少模型复杂度并提高计算效率。它在商业领域有广泛应用,如图像识别、医学图像分析、人脸识别等。Python中的深度学习框架如TensorFlow、Keras等.
CNN的网络结构分为3部分:输入层,隐藏层与输出层。CNN的输入层是直接输入二维图像信息,这一点与传统的神经网络输入层需要输入一维向量有所不同。
隐藏层由三种网络构成 —— 卷积层(包含激活函数),池化层,全连接层。
卷积层:主要作用是提取特征,使用滤波器(卷积核),通过设定步长、深度等参数,对输入进行不同层次的特征提取。滤波器中的参数可以通过反向传播算法进行学习。
激活函数层:主要是将卷积层的输出做一个非线性映射。常见的激活函数包括sigmoid,tanh,Relu等
池化层:对卷积层提取的特征进行降维,主要是用于参数量压缩。可以减轻过拟合情况。常见的有平均池化和最大池化,不包含需要学习的参数。
全连接层:主要是指两层网络,所有神经元之间都有权重连接。常见用于网络的最后一层,用于计算类别得分。
输出层:输出层位于全连接层之后,对从全连接层得到的特征进行分类输出。
1、卷积层
卷积本质来说就是通过卷积核滑动遍历一幅图像像素矩阵,其权重w与对应位置像素相乘再相加的操作。这里就涉及到几个概念:卷积核、步长、填充。
举个例子说明:比如有一张猫的图像,这里猫眼睛、猫脚、猫尾巴之间的距离是很大的,看猫眼睛的时候并不会影响到猫尾巴,所以图像具有局部相关性,在特征提取的时候专门设计找猫眼睛的卷积核在这个图像中找猫眼睛,专门找猫脚的卷积核来找猫脚,专门找猫尾巴的卷积核来找猫尾巴。

(1)卷积核(Kernel)
卷积核也称作滤波器,是用来滑动的窗口,卷积核尺寸通常为3×3×c,3×3是卷积核的大小,c是卷积核的通道数。注意,这里的c和这层的输出的通道是一样的,比如224×224×3的图像,用3×3×c的卷积,那么这里的c就是3。卷积核的每个小方格上都有一个权重w,这些权重是可学习参数,训练就是要找到最优的参数.
接下来我们以灰度图像为例(通道c=1):
左边矩阵容易被理解为一张图片,中间的这个被理解为卷积核,右边的图片我们可以理解为另一张图片。
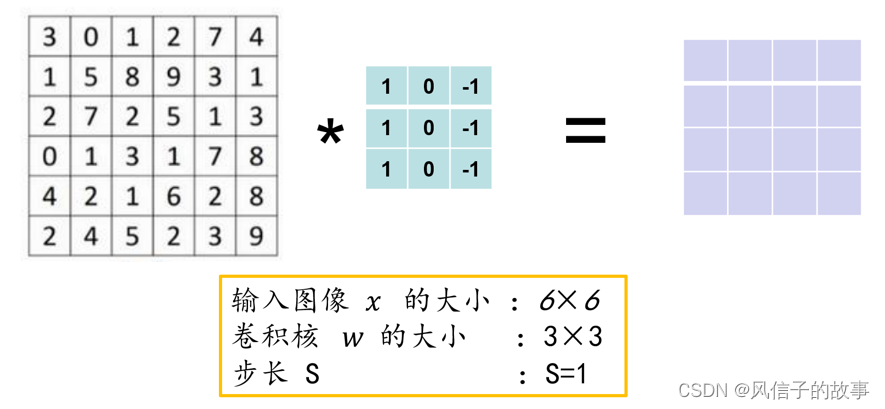
第一步计算:

第二步计算:

第一行计算完成:
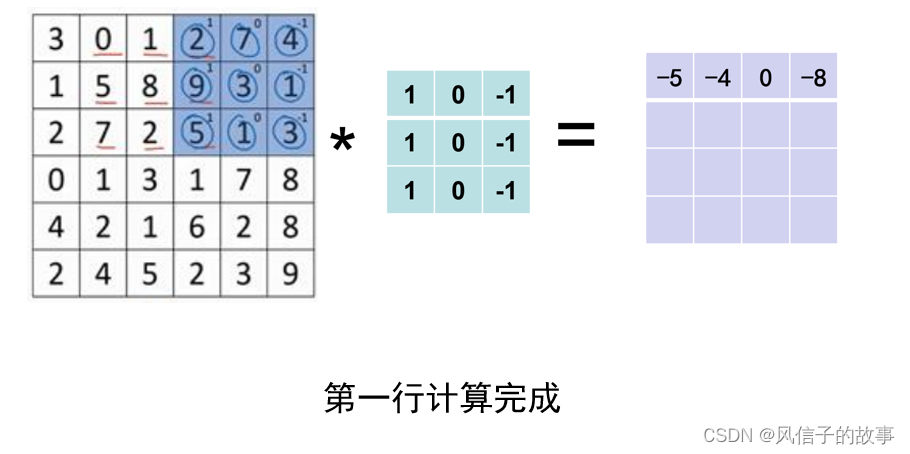
接下来为了得到下一行的元素,现在把蓝色块下移:
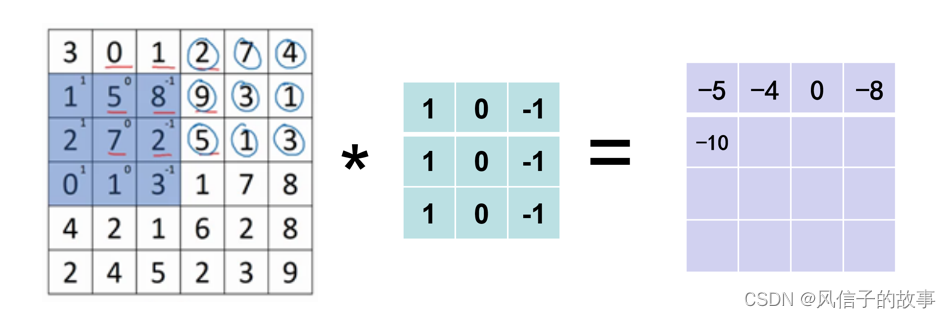
最后我们得到一个卷积计算结果为:


下图展示了使用两个三通道滤波器从三通道(RGB)图像中生成两个卷积输出的详细过程。
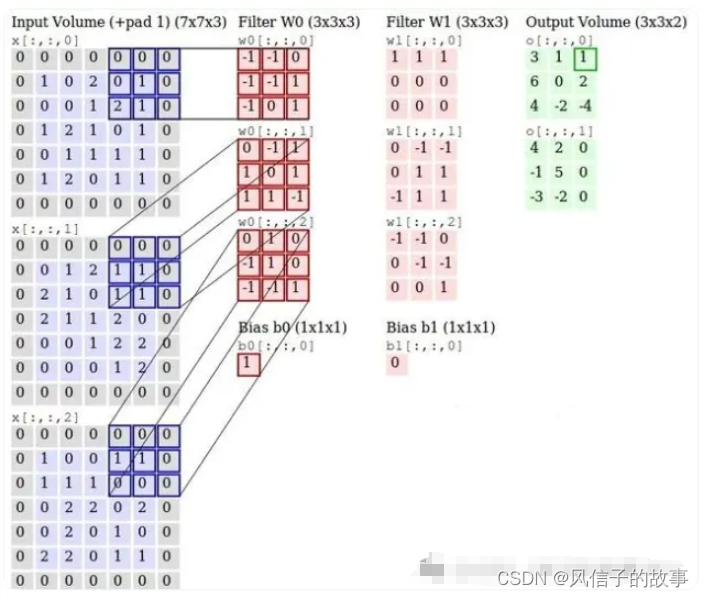
以上就是三维卷积计算方法。这里面体现了局部连接和权值共享:每层神经元只和上一层部分神经元相连(卷积计算规则),且filter的权值对于上一层所有神经元都是一样的。对于包含两个3*3*3的fitler的卷积层来说,其参数数量仅有(3*3*3+1)*2=56个,且参数数量与上一层神经元个数无关。与全连接神经网络相比,其参数数量大大减少了。
2、步长
步长(stride)是卷积操作中的一个重要参数,它决定了卷积核在输入数据上移动的间隔。步长的选择直接影响卷积操作后输出特征图的大小和信息保留程度,是神经网络卷积操作的关键参数。步长的大小可以是正整数,通常为1、2、3等。
3、填充(padding)
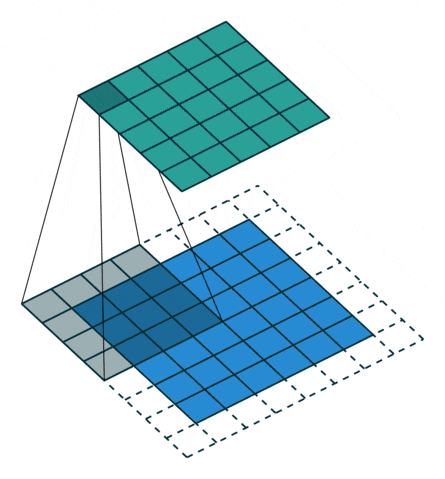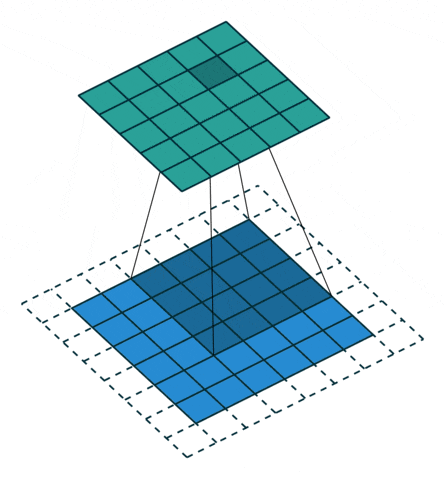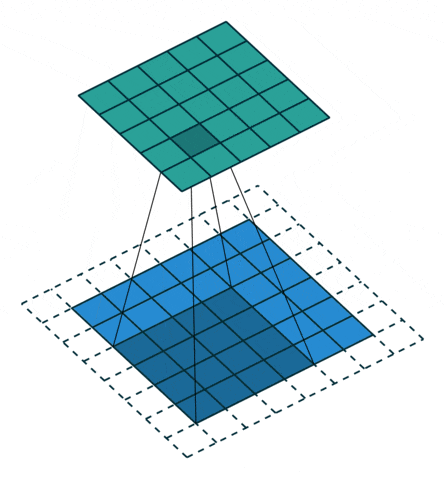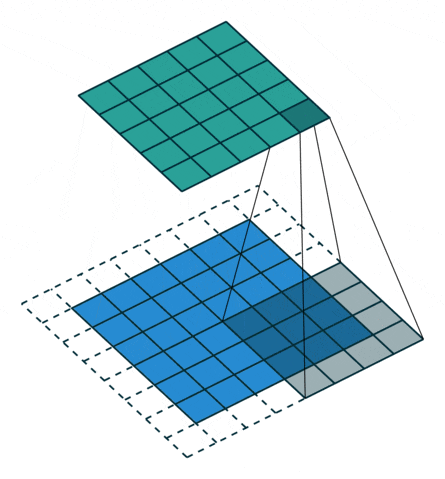
在标准卷积中,存在两问题:(1)每次卷积都会缩小图像的尺寸,图像会失去原来的形状;(2)在滑动时位于中间的像素会被重复滑动到,而位于边缘的像素就只被滑动一次,这意味着卷积过程丢掉了图像边缘的许多信息,因此,要解决这些问题,可以使用padding零填充,这样,在滑动时的卷积核可以允许原始边缘像素位于其中心,边缘有值的像素也能被计算到。如下图是padding=1的零填充。

图像填充操作
图像填充后卷积操作图
图像经过卷积得到的特征图大小是由卷积核大小、步长、padding共同决定的,其计算公式为 :

2、池化层 (Pooling )
随着模型网络不断加深,卷积核越来越多,要训练的参数还是很多,而且直接拿卷积核提取的特征直接训练也容易出现过拟合的现象。CNN使用的另一个有效的工具被称为“池化(Pooling)”出现并解决了上面这些问题,为了有效地减少计算量,池化就是将输入图像进行缩小,减少像素信息,只保留重要信息;为了有效地解决过拟合问题,池化可以减少数据,但特征的统计属性仍能够描述图像,而由于降低了数据维度,可以有效地避免过拟合。
池化的定义:对不同位置区域提取出有代表性的特征(进行聚合统计,例如最大值、平均值等),这种聚合的操作就叫做 池化,池化的过程通常也被称为 特征映射 的过程(特征降维)。听起来很高深,其实简单地说就是下采样。
池化主要有两种, 最大值池化(Max Pooling)和 平均值池化(Average pooling),最大池化是对局部窗口的值取最大,平均池化是对局部窗口的值取平均。

详细的池化过如下:
池化核的大小:3×3
池化步长:1
池化类型 : 最大值池化(Max Pooling)

池化层的主要作用就是对非线性激活函数后的结果进行降采样,以减少参数的数量,避免过拟合,并提高模型的处理速度。
3、Flatten层&全连接层(Full Connected Layer)
Flatten:将最后的二维特征图打平成一维。
全连接层:对提取的特征进行非线性组合以得到输出。
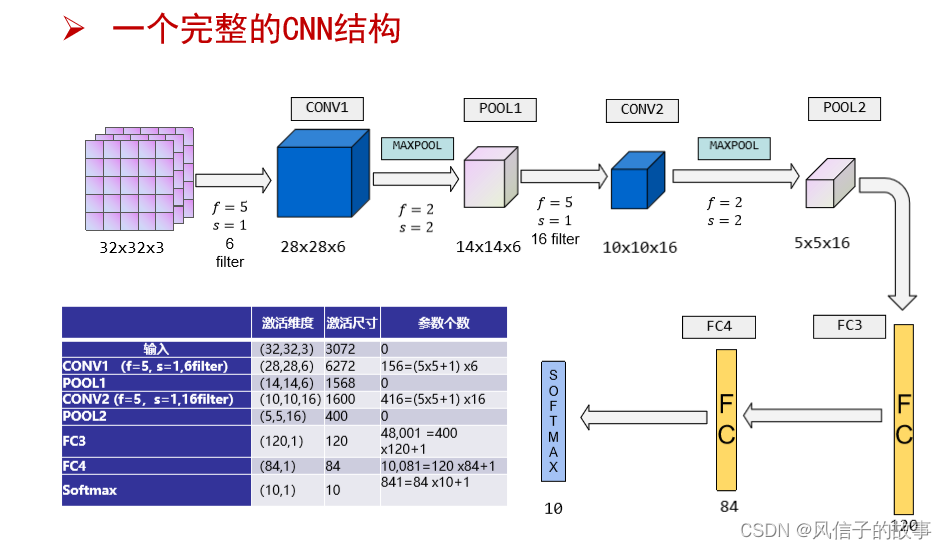
到这一步,其实我们的一个完整的“卷积部分”就算完成了,如果想要叠加层数,一般也是叠加“Conv-MaxPooing",通过不断的设计卷积核的尺寸,数量,提取更多的特征,最后识别不同类别的物体。做完Max Pooling后,我们就会把这些数据“拍平”,丢到Flatten层,然后把Flatten层的output放到full connected Layer里,采用softmax对其进行分类。
一个完整的CNN结构
4、CNN网络的实战
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision import datasets #torchvision计算机视觉库
from torch.utils.data import DataLoader
import torch.nn.functional as f #使用functional中的ReLu激活函数
import torch.optim as optim
import matplotlib.pyplot as plt
# 准备数据集
batch_size = 64
#神经网络希望输入的数值较小,最好在0-1之间,所以需要先将原始图像(0-255的灰度值)转化为图像张量(值为0-1)
#仅有灰度值->单通道 RGB -> 三通道 读入的图像张量一般为W*H*C (宽、高、通道数) 在pytorch中要转化为C*W*H
transform = transforms.Compose([
#将数据转化为图像张量
transforms.ToTensor(),
# 进行归一化处理,切换到0-1分布 (均值, 标准差)
transforms.Normalize(mean=[0.1307,],std=[0.3081,])
])
train_dataset = datasets.MNIST(root="../mnist_data/",train=True,transform=transform,download=True)
test_dataset = datasets.MNIST(root="../mnist_data/",train=False,transform=transform,download=True)
"""
for step,(b_x,b_y) in enumerate (train_dataset):
if step>0:
break
batch_x=b_x.squeeze(1).numpy();#将思维张量移除第一维度,并转化为numpy数组
batch_y=b_y.numpy()
class_label=train_dataset.classes;
print(class_label.classes)
"""
#将自定义的dataset根据batch size的大小、是否shuffle等选项封装成一个batch size大小的tensor,后续就只需要在包装成variable即可作为模型的输入进行训练。
train_dataloader = DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)
test_dataloader = DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=True)
# 网络模型
class Model(nn.Module):
#构造函数,用于初始化对象的属性
def __init__(self):
super(Model, self).__init__()
# 两个卷积层
self.conv1 = nn.Conv2d(1,10,kernel_size=5) #1为in_channels 10为out_channels,卷积核大小是5X5的
self.conv2 = nn.Conv2d(10,20,kernel_size=5)
# 池化层
self.pooling = nn.MaxPool2d(2)#2为最大池化窗口的大小
# 全连接层 320 = 20 * 4 * 4
self.fc = nn.Linear(320,10)
def forward(self,x):
# 先从x数据维度中得到batch_size
batch_size = x.size(0)
# 卷积层->池化层->激活函数
x = f.relu(self.pooling(self.conv1(x)))
x = f.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1) # 将数据展开,为输入全连接层做准备
x = self.fc(x)
return x
# x = f.relu(self.pooling(self.conv1(x)))
# x = f.relu(self.pooling(self.conv2(x)))
# x = x.view(x.size(0), -1)
# x = self.fc(x)
# return x
model = Model()
#在这里加入两行代码,将数据送入GPU中计算!!!
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device) #将模型的所有内容放入cuda中
# 优化器和损失函数
criterion = nn.CrossEntropyLoss()
#神经网络已经逐渐变大,需要设置冲量momentum=0.5
optimizer = optim.SGD(model.parameters(),lr = 0.01,momentum=0.5)
# 训练
epoch_list = []
def train(epoch):
running_loss = 0.0
epoch_list.append(epoch+1)
# for epoch in range(10):
for i, data in enumerate(train_dataloader, 0):
input, target = data
input, target = input.to(device),target.to(device)
y_pred = model(input) #前向传播
loss = criterion(y_pred, target) #计算损失
# print(i+1,epoch+1,loss.item())
optimizer.zero_grad()
loss.backward() #反向传播,计算梯度
optimizer.step() #更新权重
running_loss += loss.item()
if i % 300 == 299:
print("{} {} loss:{:.3f}".format(epoch + 1, i + 1, running_loss / 300))
running_loss = 0.0
# 测试
accuracy_list = []
def test():
total = 0
correct = 0
#表明当前计算不需要反向传播,使用之后,强制后边的内容不进行计算图的构建
with torch.no_grad():
for i,data in enumerate(test_dataloader,0):
input,target = data
input, target = input.to(device), target.to(device)
y_pred = model(input)
predicted = torch.argmax(y_pred.data,dim=1) #找打最大概率的类别
total += target.size(0)
correct += (predicted==target).sum().item()
accuracy = correct/total
accuracy_list.append(accuracy)
print("Accuracy on test set:{:.2f} %".format(100*correct/total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
#画图
plt.plot(epoch_list,accuracy_list)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.grid()
plt.show()如果大家对神经网络知识感兴趣可以关注我的微信公众号,里面会分享一些知识干货。
















 568
568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









