






 文章介绍了如何利用门控循环神经网络(GRU)进行名字到国家的分类任务。首先,数据预处理包括对名字和国家进行编码,然后构建GRU模型,包含嵌入层和线性层。在训练过程中,使用Adam优化器,经过多轮训练,模型能在测试集上达到较高的准确率,证明了GRU在处理此类任务上的有效性。
文章介绍了如何利用门控循环神经网络(GRU)进行名字到国家的分类任务。首先,数据预处理包括对名字和国家进行编码,然后构建GRU模型,包含嵌入层和线性层。在训练过程中,使用Adam优化器,经过多轮训练,模型能在测试集上达到较高的准确率,证明了GRU在处理此类任务上的有效性。
GRU:门控循环神经网络对于LSTM有计算量上的优势,且能充分考虑上下文关系。不同于LSTM的四门控制GRU简化为更新门和重置门,其中更新门的作用是控制前一时间段的信息被当前时刻保留多少,重置门的作用是控制当前时刻的信息往下传递多少。
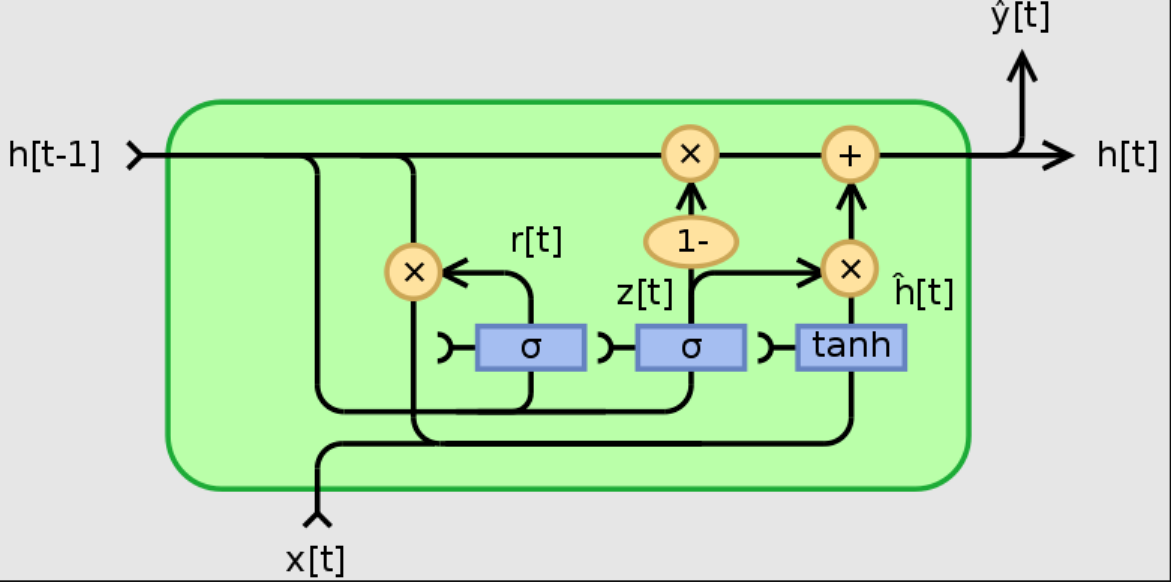
上图截取自paperwithcode,r[t]为重置门,z[t]为更新门

与循环神经网络一样,GRU的输出是最后一个时刻的隐藏层
待更新参数为wz,wr,wt,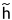 是候选hidden,受重置门限制,rt越大以往的信息被利用的越多,h是真正的hidden,z越大当前时刻的信息传递的越多,以往信息传递的越少。
是候选hidden,受重置门限制,rt越大以往的信息被利用的越多,h是真正的hidden,z越大当前时刻的信息传递的越多,以往信息传递的越少。
数据集:
链接:https://pan.baidu.com/s/1LFa8HK2tzoi2Z9BeBpbOIg?pwd=nzy2
提取码:nzy2
任务:
通过名字预测国家
padding:找到最长的字符串,其他不够这么长的都填充0
把国家转成分类索引
将数据集的名字和国家的索引对应上
编程思路都在注释里面了,可以直接看代码
# 具体实现
# 1.准备数据
'''
country_list: 按字母表顺序排列国家名
country_dict: 国家名对应编号
'''
# enumerate是遍历函数,左边list,右边编号从任何数开始都行
import gzip
import csv
from torch.utils.data import Dataset,DataLoader
from torch.nn.utils.rnn import pack_padded_sequence
import time
import math
class NameDataset(Dataset):
def __init__(self,train_set=True):
filename='names_train.csv.gz' if train_set else 'names_test.csv.gz'
with gzip.open('names_train.csv.gz','rt') as f:
reader=csv.reader(f)
rows=list(reader)
self.names=[row[0] for row in rows]
self.len=len(self.names)
self.countries=[row[1] for row in rows]
self.country_list=list(sorted(set(self.countries)))
self.country_dict=self.getCountryDict()
self.country_num=len(self.country_list)
def __getitem__(self,index):
return self.names[index],self.country_dict[self.countries[index]]
def __len__(self):
return self.len
def getCountryDict(self):
country_dict=dict()
for idx,country_name in enumerate(self.country_list,0):
country_dict[country_name]=idx
return country_dict
def getCoutriesNum(self):
return self.country_num
# 2.具体模型
'''
先过嵌入层,再过GRU,最后经过一个线性层得到想要的输出
input_size:字符的数量,字母表有多少元素
hidden_size:隐层维度,这些字符总共需要多少维数据表示
output_size:种类数
n_layer:用几层GRU
gru:门控循环神经网络
fc:线性层
'''
class RNNClassfier(torch.nn.Module):
def __init__(self,input_size,hidden_size,output_size,n_layers=1,bidirectional=True):
super(RNNClassfier,self).__init__()
self.hidden_size=hidden_size
self.n_layers=n_layers
self.n_directions=2 if bidirectional else 1
self.embedding=torch.nn.Embedding(input_size,hidden_size)
self.gru=torch.nn.GRU(hidden_size,hidden_size,n_layers,bidirectional=bidirectional)
self.fc=torch.nn.Linear(hidden_size*self.n_directions,output_size)
def _init_hidden(self,batch_size):
hidden=torch.zeros(self.n_layers*self.n_directions,batch_size,self.hidden_size)
return create_tensor(hidden)
def forward(self,input,seq_len):
#将输入做转置,每个向量从横着的变成竖着的
input=input.t()
batch_size=input.size(1)
hidden=self._init_hidden(batch_size)
embedding=self.embedding(input)
# padding_pack:只把非零的序列拿出来,把填充的数据去掉
gru_input=pack_padded_sequence(embedding,seq_len)
output,hidden=self.gru(gru_input,hidden)
if self.n_directions==2:
hidden_cat=torch.cat([hidden[-1],hidden[-2]],dim=1)
else:
hidden_cat=hidden[-1]
fc_output=self.fc(hidden_cat)
return fc_output
# 几个工具函数:
# 将张量挂在gpu上
def create_tensor(tensor):
device=torch.device("cpu")
tensor=tensor.to(device)
return tensor
# 展示训练时间 math.floor()浮点数向下取整
def time_since(since):
s=time.time()
m=math.floor(s/60)
s-=m*60
return '%dm %ds'%(m,s)
# 将名字转化成列表,ord函数的作用是返回字符的ASCII值
def name2list(name):
arr=[ord(c) for c in name]
return arr,len(arr)
#将输入转化成神经网络可以训练的张量
'''
seq_tensor:填充好的按照由长到短排序的张量
seq_lengths:每个向量的实际长度
countries:国家编码
'''
def make_tensors(names,countries):
seq_len=[name2list(name) for name in names]
name_seq=[s1[0] for s1 in seq_len]
seq_lengths=torch.LongTensor([s1[1] for s1 in seq_len])
countries=countries.long()
# padding
seq_tensor=torch.zeros(len(name_seq),seq_lengths.max()).long()
for idx,(seq,seq_l) in enumerate(zip(name_seq,seq_lengths),0):
seq_tensor[idx,:seq_l]=torch.LongTensor(seq)
#sort by length
seq_lengths,perm_idx=seq_lengths.sort(dim=0,descending=True)
seq_tensor=seq_tensor[perm_idx]
countries=countries[perm_idx]
return (create_tensor(seq_tensor),
create_tensor(seq_lengths),
create_tensor(countries))
'''
3.训练测试模型
(1) compute output
(2) compute loss
(3) zero grad
(4) backward
(5) update w
'''
def trainModel():
total_loss=0
for i,(names,countries) in enumerate(trainloader,1):
#print(type(make_tensors(names,countries)))
inputs,seq_lenghs,target=make_tensors(names,countries)
output=classifier(inputs,seq_lenghs)
loss=criterion(output,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss+=loss.item()
if i%10 == 0:
print(f'[{time_since(start)}] Epoch {epoch}',end='')
print(f'[{i*len(inputs)}/{len(trainset)}]')
print(f'loss={total_loss/(i*len(inputs))}')
return total_loss
def testModel():
correct=0
total=len(testset)
print("evaluating trained model ...")
with torch.no_grad():
for i,(names,countries) in enumerate(testloader,1):
inputs,seq_lengths,target=make_tensors(names,countries)
output=classifier(inputs,seq_lengths)
#max函数:dim表示在哪个维度上取数,keepdim表示是否保持原维度
#返回一个元组,0:最大值; 1:最大值对应的下标
pred=output.max(dim=1,keepdim=True)[1]
#pred.eq 计算一共预测对了多少
correct += pred.eq(target.view_as(pred)).sum().item()
percent='%.2f' % (100*correct/total)
# python中将单引号前面加个f就可以在花括号中插入内容
print(f'Test set:Accuracy {correct}/{total} {percent}%')
return correct/total
# 参数设置
HIDDEN_SIZE=100
BATCH_SIZE=256
N_LAYER=2
N_EPOCHS=100
N_CHARS=128
N_COUNREY=18
trainset=NameDataset(train_set=True)
trainloader=DataLoader(trainset,batch_size=BATCH_SIZE,shuffle=True)
testset=NameDataset(train_set=False)
testloader=DataLoader(testset,batch_size=BATCH_SIZE,shuffle=False)
#主函数
if __name__=='__main__':
classifier=RNNClassfier(N_CHARS,HIDDEN_SIZE,N_COUNREY,N_LAYER)
device=torch.device('cpu')
criterion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(classifier.parameters(),lr=0.01)
start=time.time()
print("Training for %d epoch..." % N_EPOCHS)
acc_list=[]
for epoch in range(1,N_EPOCHS+1):
trainModel()
acc=testModel()
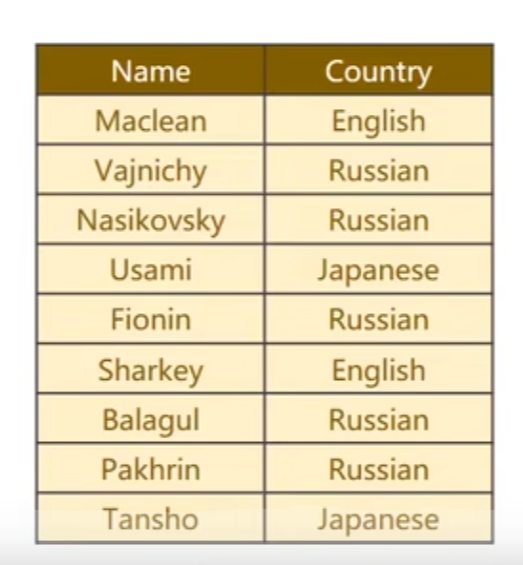
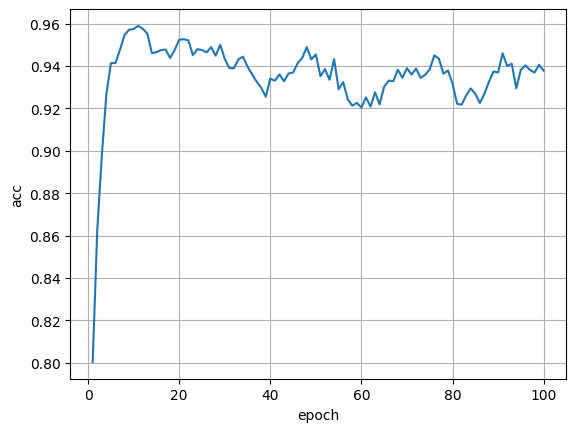
acc_list.append(acc)结论:adam优化器在分类任务上有天然的优势,前五轮即可得到90%以上的准确率
再用matplotlib绘制一下loss下降的过程:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









