







Java面试题
一、基础知识
1.1 集合相关
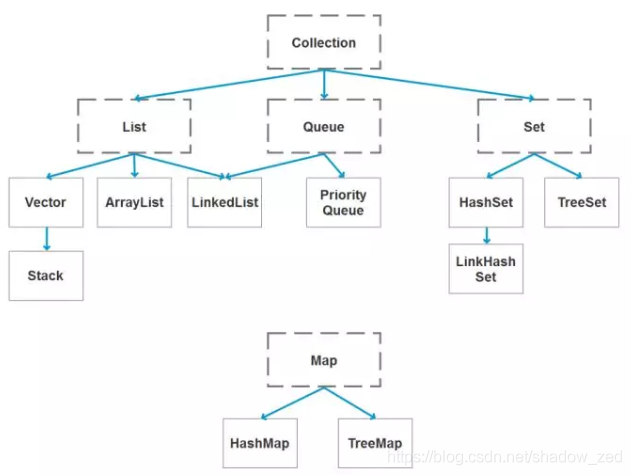
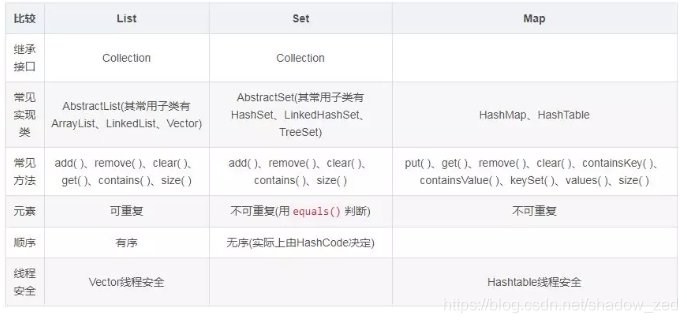
1.1.1 常用的集合有哪些?各自的特点
A、List系
1、ArrayList
-
底层数据结构:动态数组
-
特点:改查快,增删慢,
-
线程安全:线程不安全
2、LinkedList
-
底层数据结构:链表
-
特点:,改查慢,增删快
-
线程安全:线程不安全
3、Vector
-
底层数据结构:数组
-
特点:查询快,增删慢
-
线程安全:线程安全
B、set系列
1、hashSet
-
底层数据结构:哈希表 要想放入hashSet必须重写equals和hashCode方法
-
特点:元素不能重复;无序
-
线程安全:线程不安全
2、TreeSet
-
** 底层数据结构**:红黑树(自然平衡二叉树)
-
特点:元素不能重复;有序;TreeSet自动排序,添加元素时会调用compareTo(Object obj)方法,遇到重复不添加元素;有两种排序方法:1、自然排序(默认升序) 2、定制排序 ;
-
线程安全:线程不安全
3、LinkedHashSet
-
底层数据结构:哈希表(元素不可重复)+ 链表(有序)
-
特点:元素不能重复;有序
*线程安全:线程不安全
C、Map集合
1、HashMap
-
底层数据结构:基于哈希表的Map接口的非同步实现
-
特点:元素不可以重复,可以存一个null;不保证映射的顺序,特别是它不保证该顺序恒久不变。
-
线程安全:线程不安全
2、HashTable
-
底层数据结构:哈希表
-
特点:hashTable同步的,不允许为空值
-
线程安全:线程安全
D、常见问题
1、hashMap的实现原理
-
HashMap概述:
HashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
-
HashMap的数据结构:
在java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外。HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
当我们往Hashmap中put元素时,首先根据key的hashcode重新计算hash值,根据hash值得到这个元素在数组中的位置(下标),如果该数组在该位置上已经存放了其他元素,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放入链尾.如果数组中该位置没有元素,就直接将该元素放到数组的该位置上。
需要注意Jdk 1.8中对HashMap的实现做了优化,当链表中的节点数据超过八个之后,该链表会转为红黑树来提高查询效率,从原来的O(n)到O(logn)
2、 说一下 HashSet 的实现原理?
- HashSet底层由HashMap实现
- HashSet的值存放于HashMap的key上
- HashMap的value统一为PRESENT
3、 ArrayList 和 LinkedList 的区别是什么?
最明显的区别是 ArrrayList底层的数据结构是数组,支持随机访问,而 LinkedList 的底层数据结构是双向循环链表,不支持随机访问。使用下标访问一个元素,ArrayList 的时间复杂度是 O(1),而 LinkedList 是 O(n)。
4、ArrayList 和 Vector 的区别是什么?
- Vector是同步的,而ArrayList不是。然而,如果你寻求在迭代的时候对列表进行改变,你应该使用CopyOnWriteArrayList。
- ArrayList比Vector快,它因为有同步,不会过载。
- ArrayList更加通用,因为我们可以使用Collections工具类轻易地获取同步列表和只读列表。
5、Array 和 ArrayList 有何区别?
- Array可以容纳基本类型和对象,而ArrayList只能容纳对象。
- Array是指定大小后不可变的,而ArrayList大小是可变的。
- Array没有提供ArrayList那么多功能,比如addAll、removeAll和iterator等
6、哪些集合类是线程安全的?
- vector:就比arraylist多了个同步化机制(线程安全),因为效率较低,现在已经不太建议使用。在web应用中,特别是前台页面,往往效率(页面响应速度)是优先考虑的。
- statck:堆栈类,先进后出。
- hashtable:就比hashmap多了个线程安全。
- enumeration:枚举,相当于迭代器。
1.1.2 HashMap的扩容机制,ArrayList的扩容机制
- hashMap扩容是当 查过当前容量的75%之后容器就会自动扩容为之前的两倍,初始容量为1 << 4 = 16
- ArrayList扩容机制是扩大一半
1.2 IO/NIO
1.2.1 java 中 IO 流分为几种?
按功能来分:输入流(input)、输出流(output)。
按类型来分:字节流和字符流。
字节流和字符流的区别是:字节流按 8 位传输以字节为单位输入输出数据,字符流按 16 位传输以字符为单位输 入输出数据。
1.2.2、BIO、NIO、AIO 有什么区别?
- BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。
- NIO:New IO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过 Channel(通道)通讯,实现了多路复用。
- AIO:Asynchronous IO 是 NIO 的升级,也叫 NIO2,实现了异步非堵塞 IO ,异步 IO 的操作基于事件和回调机制。
1.2.3 Files的常用方法都有哪些?
- Files.exists():检测文件路径是否存在。
- Files.createFile():创建文件。
- Files.createDirectory():创建文件夹。
- Files.delete():删除一个文件或目录。
- Files.copy():复制文件。
- Files.move():移动文件。
- Files.size():查看文件个数。
- Files.read():读取文件。
- Files.write():写入文件。
1.3 String 、StringBuilder 、StringBuffer的区别与特点
-
数据可变不可变
String底层是有final修饰的数组实现,所以一旦创建便不可以修改,StringBuilder和StringBuffer都继承了AbstractStringBuilder底层使用的是可变字符数组:char[] value;所以可以修改
-
线程安全
stringBuilder线程不安全;StringBuffer线程安全;StringBuffer是有同步锁,而StringBuilder没有
-
效率
StringBuilder > StringBuffer > String
1.4 ”==“ 和equals的区别
- 在没有重新equals方法的情况下,equals和“==“没有区别;如下源码:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
-
较的是两个引用在内存中指向的是不是同一对象(即同一内存空间),也就是说在内存空间中的存储位置是否一致。如果两个对象的引用相同时(指向同一对象时),“”操作符返回true,否则返回flase。
-
基本数据类型用==比较
-
equals用来比较某些特征是否一样。我们平时用的String类等的equals方法都是重写后的,实现比较两个对象的内容是否相等。
-
小记:
int的包装类型Integer,在-128~127这个范围内用”==“比较,是可以的,但是超过这个范围就只能用equal比较
1.5 hashCode相等,则equals一定相等吗?如果不是,请举反例
hashCode相等,equals不一定相等,如: “通话” 、" 重地"
String th = "通话", zd = "重地";
System.out.println(hash(th) == hash(th)); //true hash(th) = 1179426 hash(zd) = 1179426
System.out.println(th.equals(zd)); // false
二、多线程
2.1 synchronized volatile区别与工作原理
2.1.1 说一下 synchronized 底层实现原理?
-
synchronized可以保证方法或者代码块在运行时,同一时刻只有一个方法可以进入到临界区,同时它还可以保证共享变量的内存可见性。
Java中每一个对象都可以作为锁,这是synchronized实现同步的基础:
- 普通同步方法,锁是当前实例对象
- 静态同步方法,锁是当前类的class对象
- 同步方法块,锁是括号里面的对象
2.2.2 synchronized 和 volatile 的区别是什么?
- volatile本质是在告诉jvm当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取; synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。
- volatile仅能使用在变量级别;synchronized则可以使用在变量、方法、和类级别的。
- volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量的修改可见性和原子性。
- volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞。
- volatile标记的变量不会被编译器优化;synchronized标记的变量可以被编译器优化。
2.2.3 在 java 程序中怎么保证多线程的运行安全?
线程安全在三个方面体现:
- 原子性:提供互斥访问,同一时刻只能有一个线程对数据进行操作,(atomic,synchronized);
- 可见性:一个线程对主内存的修改可以及时地被其他线程看到,(synchronized,volatile);
- 有序性:一个线程观察其他线程中的指令执行顺序,由于指令重排序,该观察结果一般杂乱无序,(happens-before原则)。
2.2 线程
2.2.1 创建线程的几种方式
①. 继承Thread类创建线程类
- 定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务。因此把run()方法称为执行体。
- 创建Thread子类的实例,即创建了线程对象。
- 调用线程对象的start()方法来启动该线程。
②. 通过Runnable接口创建线程类
- 定义runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。
- 创建 Runnable实现类的实例,并依此实例作为Thread的target来创建Thread对象,该Thread对象才是真正的线程对象。
- 调用线程对象的start()方法来启动该线程。
③. 通过Callable和Future创建线程
- 创建Callable接口的实现类,并实现call()方法,该call()方法将作为线程执行体,并且有返回值。
- 创建Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。
- 使用FutureTask对象作为Thread对象的target创建并启动新线程。
- 调用FutureTask对象的get()方法来获得子线程执行结束后的返回值。
2.3 创建线程池的几种方式,线程池的优点
-
一、通过Executors
A、Executors.newFixedThreadPool(int nThread): 创建固定大小的线程池
B、Executors.newCachedThreadPool(): 创建无限大小的线程池,线程池中的数量不固定,可根据需求自动 更改
C、Executors.newScheduledThreadPool(int nThread):创建固定大小的线程池,可以延迟或定时的任务
D、Executors.newSingleThredPool(): 创建单个线程池,线程池中只有一个线程池
-
二、自己手动创建线程池(阿里巴巴开发规范手册推荐)
new ThreadPoolExecutor(2, 5, 1L, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(3), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy());参数说明:
-
int corePoolSize
核心池的大小,这个参数跟后面讲述的线程池的实现原理有非常大的关系。预创建线程的意思,即在没有任务到来之前就创建corePoolSize个线程或者一个线程。默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中;
-
int maximumPoolSize
线程池最大线程数,这个参数也是一个非常重要的参数,它表示在线程池中最多能创建多少个线程;
-
long keepAliveTime
表示线程没有任务执行时最多保持多久时间会终止
-
TimeUnit unit
参数keepAliveTime的时间单位,有7种取值。TimeUnit.DAYS、TimeUnit.HOURS、TimeUnit.MINUTES、TimeUnit.SECONDS、TimeUnit.MILLISECONDS、TimeUnit.MICROSECONDS、TimeUnit.NANOSECONDS
-
BlockingQueue workQueue
一个阻塞队列,用来存储等待执行的任务,这个参数的选择也很重要,会对线程池的运行过程产生重大影响,一般来说,这里的阻塞队列有以下几种选择:ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue。
ArrayBlockingQueue和PriorityBlockingQueue使用较少,一般使用LinkedBlockingQueue和Synchronous。线程池的排队策略与BlockingQueue有关。 -
ThreadFactory threadFactory
线程工厂,主要用来创建线程;
-
handler
表示当拒绝处理任务时的策略,有以下四种取值:
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
三、线程池的优点
(1)降低资源的消耗。通过重复利用已经创建的线程降低线程创建和销毁造成的消耗。
(2)提高响应速度。当任务到达时,任务可以不需要等线程创建就能立即执行。
(3)提高线程可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的 稳定性,使用线程池可以进行统一的分配,调优和监控。 -
2.4 实现runnable和callable有什么区别?
- Runnable接口中的run()方法的返回值是void,它做的事情只是纯粹地去执行run()方法中的代码而已;
- Callable接口中的call()方法是有返回值的,是一个泛型,和Future、FutureTask配合可以用来获取异步执行的结果。
2.5 阿里规范 要求的自定义线程池怎么实现,为什么这样要求?
Executors各个方法的弊端:
1)newFixedThreadPool和newSingleThreadExecutor:
主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至OOM。
2)newCachedThreadPool和newScheduledThreadPool:
主要问题是线程数最大数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至OOM。
2.6 JMM??
三、数据库
3.1 Mysql索引底层实现原理?
B+Tree
四、Spring、Spring Boot 、SpringMVC、Spring Security…
4.1 Spring
Spring 是一个开源应用框架,旨在降低应用程序开发的复杂度。它是轻量级、松散耦合的。它具有分层体系结构,允许用户选择组件,同时还为 J2EE 应用程序开发提供了一个有凝聚力的框架。它可以集成其他框架,如Structs、Hibernate、EJB 等,所以又称为框架的框架
4.1.1 Spring中bean的生命周期

- 1、Spring 容器根据配置中的 bean 定义中实例化 bean。
- 2、Spring 使用依赖注入填充所有属性,如 bean 中所定义的配置。
- 3、如果 bean 实现BeanNameAware 接口,则工厂通过传递 bean 的 ID 来调用setBeanName()。
- 4、如果 bean 实现 BeanFactoryAware 接口,工厂通过传递自身的实例来调用 setBeanFactory()。
- 5、如果存在与 bean 关联的任何BeanPostProcessors,则调用 preProcessBeforeInitialization() 方法。
- 6、如果为 bean 指定了 init 方法( 的 init-method 属性),那么将调
用它。 - 7、最后,如果存在与 bean 关联的任何 BeanPostProcessors,则将调用 postProcessAfterInitialization() 方法。
- 8、如果 bean 实现DisposableBean 接口,当 spring 容器关闭时,会调用 destory()。
- 9、如果为bean 指定了 destroy 方法( 的 destroy-method 属性),那么将
调用它。
4.1.2 Spring中是如何解决循环依赖的
三级缓存
4.1.3 简介AOP(aspect、join point、advice、around)、IOC
4.1.3.1、什么是AOP
AOP(Aspect-Oriented Programming), 即 面向切面编程, 它与OOP( Object-Oriented Programming, 面向对象编程) 相辅相成, 提供了与OOP 不同的抽象软件结构的视角. 在 OOP 中, 我们以类(class)作为我们的基本单元, 而 AOP 中的基本单元是 Aspect(切面)
4.1.3.2 什么是Aspect
- a、如何通过 pointcut 和 advice 定位到特定的 joinpoint 上
- b、如何在advice 中编写切面代码.

可以就这样认为:使用@Aspect注解的累就是切面
4.1.3.3 什么是JoinPoint
程序运行中的一些时间点,例如一个方法的执行,或者是一个异常的处理。
在Spring AOP中,jion point总是方法的执行点
4.1.3.4 什么是通知(Advice)
特定的JoinPoint处的Aspect所采取的动作成为Advice。Spring AOP使用一个Advice作为拦截器,在JoinPoint”周围“维护一系列的拦截器。
4.1.3.5 有哪些类型的通知(Advice)
- Before - 这些类型的 Advice 在 joinpoint 方法之前执行,并使用@Before 注解标记进行配置。
- After Returning - 这些类型的 Advice 在连接点方法正常执行后执行,并使用@AfterReturning 注解标记进行配置。
- After Throwing - 这些类型的 Advice 仅在 joinpoint 方法通过抛出异常退出并使用 @AfterThrowing 注解标记配置时执行。
- After (finally) - 这些类型的 Advice 在连接点方法之后执行,无论方法退出是正常还是异常返回,并使用 @After 注解标记进行配置。
- Around - 这些类型的 Advice 在连接点之前和之后执行,并使用@Around 注解标记进行配置
4.1.4 Spring中的代理
将 Advice 应用于目标对象后创建的对象称为代理。在客户端对象的情况下,目标对象和代理对象是相同的。
4.1.5有哪些不同类型的 IOC(依赖注入)方式?
-
构造器依赖注入:
构造器依赖注入通过容器触发一个类的构造器来实现的,该类有一系列参数,每个参数代表一个对其他类的依赖。
-
Setter 方法注入:
Setter 方法注入是容器通过调用无参构造器或无参static 工厂 方法实例化 bean 之后,调用该 bean 的 setter 方法,即实现了基于 setter 的依赖注入
4.2 SpringBoot
4.2.1 简介下Spring与SpringBoot的区别
4.2.1 SpringBoot的自动装配原理
主要基于两个注解:@EnableAutoConfigration 和 @SpringBootConfiguration
4.3 SpringMVC
Spring 配备构建 Web 应用的全功能 MVC 框架。Spring 可以很便捷地和其他MVC 框架集成,如 Struts,Spring 的 MVC 框架用控制反转把业务对象和控制逻辑清晰地隔离。它也允许以声明的方式把请求参数和业务对象绑定
4.3.1 SpringMVC包含了哪些部分?主要做什么的?
- 前端控制器(DispatcherServlet):主要负责捕获来自客户端的请求和调度各个组件。
- 处理器映射器(HandlerMapping):根据url查找后端控制器Handler。
- 处理器适配器(HandlerAdapter):执行后端控制器(Handler),拿到后端控制器返回的结果ModelAndView后将结果返回给前端控制器DispatcherServlet。
- 后端控制器(处理器)(Handler):主要负责处理前端请求,完成业务逻辑,生成ModelAndView对象返回给HandlerAdapter。
- 视图解析器(ViewResolver):主要负责将从DispatcherServlet中拿到的ModelAndView对象进行解析,生成View对象返回给DispatcherServlet。
SpringMVC 的工作流程:

1.客户端浏览器向前端控制器(DispatcherServlet)发出请求。
2.DispatcherServlet接收到请求后,调用处理器映射器(HandlerMapping)。
3.HandlerMapping根据请求url查找相应的处理器(Handler,也称后端控制器),返回处理器对象(Handler),并且如果有处理器拦截器(HandlerInterceptor)的话,会将处理器对象(Handler)和处理器拦截器对象(HandlerInterceptor)一并返回给DispatcherServlet。
4.DispatcherServlet拿到这些信息后,会调用处理器适配器(HandlerAdapter),HandlerAdapter会执行Handler,Handler执行处理DispatcherServlet发来的请求,生成ModelAndView对象返回给HandlerAdapter。
5.HandlerAdapter将ModelAndView对象返回给DispatcherServlet。
6.DispatcherServlet在拿到ModelAndView对象之后,将ModelAndView对象发给视图解析器(ViewResolver)。
7.ViewResolver将ModelAndView对象进行解析,生成View对象,将View对象返回给DispatcherServlet。
8.DispatcherServlet拿到View对象,对jsp页面进行渲染(将模型数据填充到视图中),将渲染后的页面呈现给用户。
4.3.2 dispatchServlet做什么的
ispatcherServlet主要用作职责调度工作,本身主要用于控制流程,主要职责如下:
-
1、文件上传解析,如果请求类型是multipart将通过MultipartResolve进行文件上传解析;
-
2、通过HandlerMapping,将请求映射到处理器(返回一个HandlerExecutionChain,它包括一个处理器,多个HandlerIntercept拦截器)
-
3、通过HandlerAdapter支持多种类型的处理器(HandlerExecutionChain中的处理器);
-
4、通过ViewReslver解析逻辑视图名到具体视图实现;
-
5、本地化解析;
-
6、渲染具体的视图等;
-
7、如何执行过程中遇到异常将交给HandlerExecutionResolver来解析;
4.3 SpringCloud
4.3.1 什么是SpringCloud
Spring cloud 流应用程序启动器是基于 Spring Boot 的 Spring 集成应用程序,提供与外部系统的集成。Spring cloud Task,一个生命周期短暂的微服务框架,用于快速构建执行有限数据处理的应用程序。
4.3.2 使用 Spring Cloud 有什么优势?
使用 Spring Boot 开发分布式微服务时,我们面临以下问题
- 1、与分布式系统相关的复杂性-这种开销包括网络问题,延迟开销,带宽问题,安全问题。
- 2、服务发现-服务发现工具管理群集中的流程和服务如何查找和互相交谈。它涉及一个服务目录,在该目录中注册服务,然后能够查找并连接到该目录中的服务。
- 3、冗余-分布式系统中的冗余问题。
- 4、负载平衡 --负载平衡改善跨多个计算资源的工作负荷,诸如计算机,计算机集群,网络链路,中央处理单元,或磁盘驱动器的分布。
- 5、性能-问题 由于各种运营开销导致的性能问题。
- 6、部署复杂性-Devops 技能的要求
4.3.3 什么是 Hystrix?它如何实现容错?
Hystrix 是一个延迟和容错库,旨在隔离远程系统,服务和第三方库的访问点,当出现故障是不可避免的故障时,停止级联故障并在复杂的分布式系统中实现弹性。通常对于使用微服务架构开发的系统,涉及到许多微服务。这些微服务彼此协作
4.3.1 SpringCloud基本组件有哪些?
4.4 SpringSecurity
4.4.1 springSecurity怎么使用,用来做什么?
主要两个功能:
1、安全认证
2、权限校验
五、Redis
5.1 什么是redis
Redis 是完全开源免费的,遵守 BSD 协议,是一个高性能的 key-value 数据库。
5.1 redis主要有那些数据结构
Redis 支持五种数据类型:
- string(字符串)
- hash(哈希)
- list(列表)
- set(集合)
- zsetsorted set:(有序集合)
5.2 用的什么工具类来操作redis
jedis
5.3 redis的失效时间和永久有效怎么设置?
EXPIRE 和 设置国企时间
PERSIST [pərˈsɪst] 命令设置永久有效
5.4 redis内存不够了,会出现什么情况?
如果达到设置的上限,Redis 的写命令会返回错误信息(但是读命令还可以正常返回。)或者你可以将 Redis 当缓存来使用配置淘汰机制,当 Redis 达到内存上限时会冲刷掉旧的内容。
Redis 提供了多种缓存淘汰策略,含义在注释中说的很清楚。
LRU:表示最近最少使用; LFU:表示最不常用的。
区别在于:LFU 是一定时间内访问最少的,比如 10 分钟内访问最少的,而 LRU 则是指服务启动后,访问量最少的内容。 下面按顺序说明下淘汰策略:
volatile-lru 筛选出设置了有效期的,最近最少使用的 key;
allkeys-lru 所有 key 中,筛选出最近最少使用的 key;
volatile-lfu 筛选出设置了有效期的,最不常用的 key;
allkeys-lfu 所有 key 中,筛选出最不常用的 key ;
valatile-random 随机筛选出设置了有效期的 key;
allkeys-random 所有 key 中,随机筛选出 key进行删除;
volatile-ttl 筛选出所有设置有效期的 key 中,有效期最短的 key;
noeviction 拒绝策略,当内存满了之后,服务不做任何处理,直接返回一个错误 Redis 默认是拒绝策略,可根据实际情况做出设置。(默认)
5.5 怎么实现redis与数据库的同步
先去redis中判断数据是否存在,如果存在,则直接返回缓存好的数据。而如果不存在的话,就会去数据库中,读取数据,并把数据缓存到Redis中。适用场合:如果数据量比较大,但不是经常更新的情况(比如用户排行
六、Java web
6.1 什么是servlet?servlet的生命周期
-
什么是servlet
Java Servlet 是运行在 Web 服务器或应用服务器上的程序,它是作为来自 Web 浏览器或其他 HTTP 客户端的请求和 HTTP 服务器上的数据库或应用程序之间的中间层。
-
servlet的生命周期
Servlet 生命周期可被定义为从创建直到毁灭的整个过程。以下是 Servlet 遵循的过程:
- Servlet 通过调用 init () 方法进行初始化。
- Servlet 调用 service() 方法来处理客户端的请求。
- Servlet 通过调用 destroy() 方法终止(结束)。
- 最后,Servlet 是由 JVM 的垃圾回收器进行垃圾回收的
6.2 cookie和session的区别
- cookie
- cookie是存在浏览器端
- 单个cookie在客户端的限制是3K
- session
- session保存在服务器端
6.3 filter
过滤器是Servlet2.3规范中定义的一种小型的、可插入的Web组件,其作用是拦截Servlet容器的请求和响应,控制客户端和服务端进行的数据交换。

七、JVM、性能调优
7.1 GC的两种算法
-
可达性算法
在对象中添加一个引用计数器,当有地方引用这个对象的时候,引用计数器的值就+1,当引用失效的时候,计数器的值就-1,当引用计数器被减为零的时候,标志着这个对象已经没有引用了,可以回收了!
-
引用计数法
在主流商用语言(如Java、C#)的主流实现中, 都是通过可达性分析算法来判定对象是否存活的: 通过一系列的称为 GC Roots 的对象作为起点, 然后向下搜索; 搜索所走过的路径称为引用链/Reference Chain, 当一个对象到 GC Roots 没有任何引用链相连时, 即该对象不可达, 也就说明此对象是不可用的, 如下图:虽然E和F相互关联, 但它们到GC Roots是不可达的, 因此也会被判定为可回收的对象。
7.2 JVM内存区域的划分
八、zookeeper与dubbo
8.1 zookeeper的工作原理
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态
8.2 CAP 定理
CAP定理:CAP定理又称CAP原则,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
-
一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
-
可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
-
分区容忍性(P):就是高可用性,一个节点崩了,并不影响其它的节点(100个节点,挂了几个,不影响服务,越多机器越好)
一般来讲,基于网络的不稳定性,分布容错是不可避免的,所以我们默认CAP中的P总是成立的。
九、其他问题
9.1什么是WebSockets?
- WebSocket是一种计算机通信协议,通过单个TCP连接提供全双工通信信道。
- WebSocket是双向的-使用WebSocket客户端或服务器可以发起消息发送。
- WebSocket是全双工的-客户端和服务器通信是相互独立的。单个TCP连接-初始连接使用HTTP,然后将此连接升级到基于套接字的连接。然后这个单一连接用于所有未来的通信Light-与http相比,WebSocket消息数据交换要轻得多














 5655
5655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









