







每过一段时间,我都会练习一下单链表。
防止老年痴呆。
我开始在培训班学习C语言时,老师教我们,写C语言,先按照下面格式写个大框架,别人一看你就很专业。
#include <stdio.h>
int main()
{
return 0;
}
现在记不清那个老师姓什么了,只记得他玩帝国时代2很厉害。
跟我们吹牛说当年他们公司分两个帝国战队,招人时,先问会不会玩帝国2,水平如何。
水平不错的直接录用。水平不行就来聊聊技术问题。
先定义一个结构体作为链表的节点,或者说先定义节点结构体
为什么是struct info *next,而不是 NODE_S *next,是因为在这时对struct info的typedef还未完成。
因此不能使用NODE_S来代替struct info。
还有,注意看,我这里用的说明是指向另一个节点,而不是指向下一个节点。
#include <stdio.h>
typedef struct info
{
int data; //数据 无论是int还是char 还是数组结构体什么的都行
struct info *next; //指向另一个节点的指针
}NODE_S;
int main()
{
return 0;
}
接下来继续定义一个链表头指针。也就是一个指向链表结构体的指针。
然后写创建链表的函数。
#include <stdio.h>
typedef struct info
{
int data; //数据 无论是int还是char 还是数组结构体什么的都行
struct info *next; //指向另一个节点的指针
}NODE_S;
//创建链表
NODE_S *createList()
{
}
int main()
{
NODE_S *head;
head = createList();
return 0;
}
创建一个链表,然后返回链表头部的地址,用head这个指针接收, head = createList();
接下来我们具体看一下createList的实现,也是链表的精华
#include <stdio.h>
#include <malloc.h>
typedef struct info
{
int data; //数据 无论是int还是char 还是数组结构体什么的都行
struct info *next; //指向另一个节点的指针
}NODE_S;
//创建链表 有头结点 尾插法
NODE_S *createList()
{
int num = 0; //临时变量,用来接收输入数据
NODE_S *head = NULL;
NODE_S *p = NULL, *r = NULL;
head = (char*)malloc(sizeof(NODE_S)); //给头结点分配空间,这个头结点只有next存下一个节点地址data没用
r = head; //指向头结点
scanf("%d", &num); //接收输入数字
while (num>0)
{
p = (char*)malloc(sizeof(NODE_S)); //给下一个节点分配空间
p->data = num; //给p节点的data赋值
r->next = p; //刚才r指向head头节点,所以这里第一次的r->next也就等同于头结点的next,而第二次就等同于上一个节点的next
r = p; //r再指向p,也就是后移,这里不好理解,等下我画个图
scanf("%d",&num);
}
r->next = NULL; //把最后一个节点的next置空
return head;
}
int main()
{
NODE_S *head;
head = createList();
return 0;
}
这个图基本就是解释了这几个指针和节点之间的相互操作逻辑

只要这个能搞清楚,那么后面的增删改查节点,就没啥问题了。
现在创建好了节点,需要输出看看,那么我们就需要实现一个链表输出函数
void printList(NODE_S *p)
{
NODE_S *tmp = p->next; //这一步主要是因为是有头结点的链表,所以第一个节点是没有数据的,需要跳过
//当然也可以像下面这么跳
//p = p->next;
while (tmp)
{
printf("%d ", tmp->data);
tmp = tmp->next; //指向下一个节点
}
}
int main()
{
NODE_S *head;
head = createList();
printList(head);
return 0;
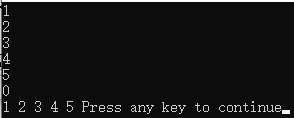
}
所以头结点的data不但浪费(我原来用这个玩意儿存储链表长度╮(╯▽╰)╭),使用链表时还需要跳过,感觉还有优化的空间
可不可以把这个头结点去掉呢?
当然是可以的。看下面代码,
//创建链表 无头结点 尾插法
NODE_S *createList2()
{
int num = 0; //临时变量,用来接收输入数据
NODE_S *head = NULL;
NODE_S *p = NULL, *r = NULL;
scanf("%d", &num); //接收输入数字
while (num>0)
{
p = (char*)malloc(sizeof(NODE_S)); //给下一个节点分配空间
p->data = num; //给p节点的data赋值
if (NULL==head)
{
head = p; //当head为NULL时,用头指针指向p
}else
{
r->next = p; //第一次以外的用r节点的next
}
r = p; //r再指向p,也就是后移,这里不好理解,等下我画个图
scanf("%d",&num);
}
r->next = NULL; //把最后一个节点的next置空
return head;
}
void printList2(NODE_S *p)
{
while (p)
{
printf("%d ", p->data);
p = p->next; //指向下一个节点
}
}
int main()
{
NODE_S *head;
//head = createList();
//printList(head);
head = createList2();
printList2(head);
return 0;
}区别
1 创建链表时 头结点不需要分配空间
2 用next指向p时,判断是否为第一个节点,如果是第一个用head指,如果不是用r->next指
3 打印,或者说使用链表时,不需要跳过第一个无数据的头结点
今天先讲到这里,改天继续讲 插入 删除 修改 查找(这个实际上等于讲过了,printList就是了)
甚至还有排序啥的,咱们循序渐进哈















 813
813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









