






一、概述
存储作为AI大模型训练的重要基础设施,贯穿大模型全流程,存储的能力和性能,直接影响大模型训练周期,影响整体成本付出。
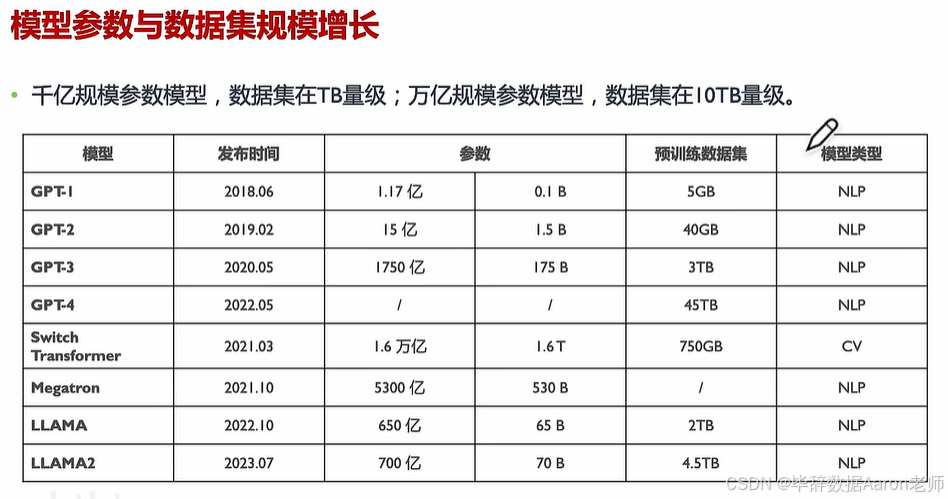
目前,受多个因素影响,大模型训练一次耗时很长,少则几天,多则数周,这取决于训练规模,比如Llama2大模型有70B规模,这里的70B指的是参数数量,70B也就是700亿,预训练数据集达到了4.5TB,所以,大模型训练是耗硬件大户,什么GPU算力、内存容量和速率、网络带宽,存储IO和吞吐量,每个环节都影响训练的时长,也就是训练成本。
二、大模型训练过程
大模型训练一般分为如下四个步骤,采集、调试、训练和推理,每个阶段对于存储需求是不同的
①数据采集和清洗 => ②开发调试 => ③模型训练 => ④模型推理
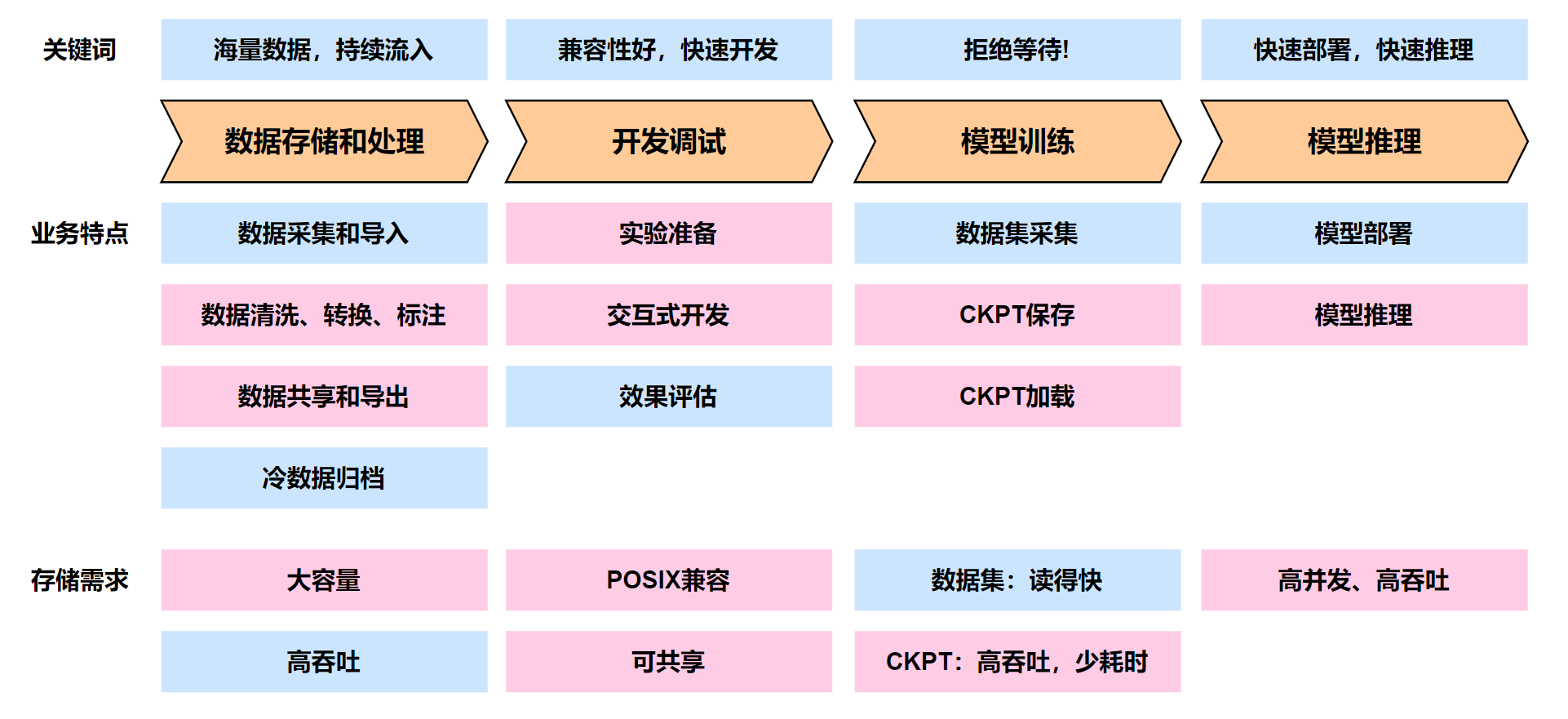
三、各个阶段的挑战和存储需求
| 训练阶段 | 主要动作 | 主要挑战 | 存储需求 |
| 数据采集和导入 | 汇集各种数据 |
示例:
|
|
| 开发调试 | 试验阶段,调测阶段 | 多人并行调试,效果评估 |
|
| 模型训练 | 模型训练 |
|
|
| 模型推理 | 智能体高并发的推理需求 | 客户端高并发请求,带来存储高并发访问 | 存储高并发访问、高带宽 |
拙作:《Ceph存储从入门到突破》



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









