






大家好,我是设计师子衿,这期干货错过就可惜了。
如今,随着数字技术的快速发展,人工智能与大数据的结合正在改变着设计师们的工作模式。从整体的趋势来看,人工智能(AI)技术在机器学习和大数据技术的支持下不断进步,可以为日常的工作流程带来极大的便利和创意空间。
就目前而言,大部分的AI工具仅能支持某些较为垂直的方向。在实际工作中, 我们往往需要在确认了需要使用的场景后,再选择相对应的工具进行使用和操作。在AI绘画领域较为知名的产品就是Midjourney 和Stable Diffusion web UI了。事实上,就目前的使用而言,两者除了上手难度的差异外,在日常工作中的使用场景也存在着较大的区别。
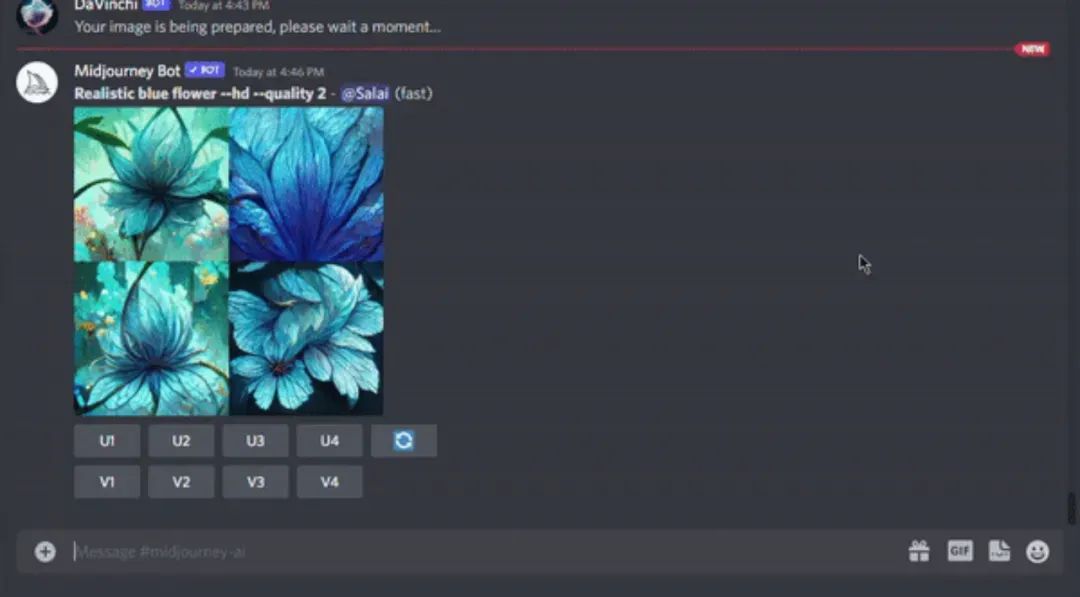
Midjourney(以下简称MJ) 是Open AI 公司开发的一款产品,它的产品形态目前主要以插件的形式存在,目前的主要绘图手段也以文生图为主。为了提高准确性,MJ还支持用户添加参考图的方式来提高AI绘画的准确性。由于MJ的模型训练是由openAI公司的封闭式模型进行训练的产物,因此它的产出相对品质较高, 比较适合设计师在没有特定想法时候获取灵感来进行使用。
与之相对的,Stable Diffusion web UI(以下简称SD)在准确性和上手难度上,几乎和MJ是完全相反的。SD在日常的操作中, 允许用户通过使用不同AI模型的组合,以此获得更加符合设计师需求的图片,且由于SD本身并不是一个产品,只是一个开源项目,它甚至可以允许用户进行本地化部署。因此,使用SD的时候需要操作者对需要生成的内容有较为清晰的认知,同时,为了更好的操作SD,需要使用者对模型的类型以及作用,需要有较为清晰的认知,也以此导致了它的上手难度相对较大。但由于SD较高的准确性和可控性,深受专业人事的喜爱。本次介绍也主要向大家介绍SD这款工具。

01
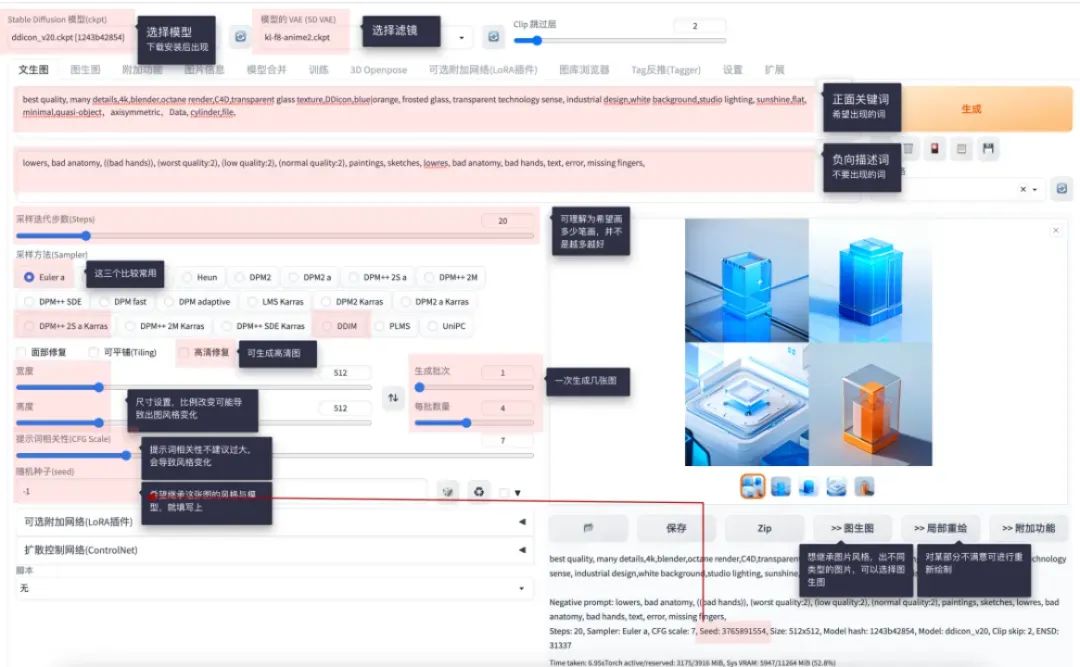
在SD的使用中, 一般需要用户先进行选择对应的模型组合以及添加对应的文案描述,如果想进一步提升精准度,甚至可以使用预处理的方式来控制主题物的样式,本次介绍仅介绍较为主流和通用的【文生图】模式,剩余的【图生图】模式会在后续进行补充。而针对SD的使用原理, 较为简单的解释就是通过大模型嵌套小模型的方式,通过正向提示加反向提示文案的辅助以及垫图的方式进行图像的生成。
其中,我们最需要知道SD的模型就是它的主模型(checkpoint),其主要用途在于控制生成图片的大方向。其次需要使用嵌套的lora模型控制细节风格, 通过VAE模型来进行滤镜美化,再配合采样算法,对应的文字提示,预处理的图形以及一定的调整后,基本可以获得效果还不错的素材的。以下将会是关于AI生图的文案构成,书写顺序,以及采样方法这三个较为主要模块的说明。
#01
语法说明
在AI绘图中,文案的填写大部分时候都是一种玄学,人们将之戏称为“咒语”,也是有一定的原因的。但其实,AI绘图的文案也会存在一些规律可以辅助我们更好像AI表示我们的想法。在SD中,“咒语”是分为【正向词】和【反向词】的,其中,正向词表示在AI绘画中想要展示的内容,而反向词表示不想在AI绘图中展示的内容。本次仅展示一些基本的正向词的规则,反向词规则以及较为复杂的规则会在后续推文中单独撰文展示。部分正向词规则如下:
规则 1: 只接受英文描述
描述词必须使用英文,不必讲求什么英文语法
规则 2: 描述词组化
不要出现一些短句,相比于一个可爱的小男孩坐在大大的花园里, 这种短句,更容易听懂 小男孩、坐姿、大花园 或(男生,年幼)(花园,大的)这种词组
规则 3: 同义词转化
例如一个男孩,可以写成 A boy也可以是 1boy,对于人来说是没有差别的,但是AI会认为,1boy更准确。同理,比起 A little girl,在 AI 看来 loli,solo 会更贴切。
#02
描述词排序

01 : 物体描述
描述词期待绘画的主体信息
02: 描述词组化
描绘增加对应的材质,细节需求等相关信息,尽可能详细描述,如果必要,可以尽可能多的补充说明
03:渲染信息
展示相关的渲染信息,包括自己的描述和lora模型的使用比例
02
#02
采样与降噪说明
采样与降噪是AI绘图中较为重要的步骤,采用适合的采样方式,可以更好的得到更为适合的图像。
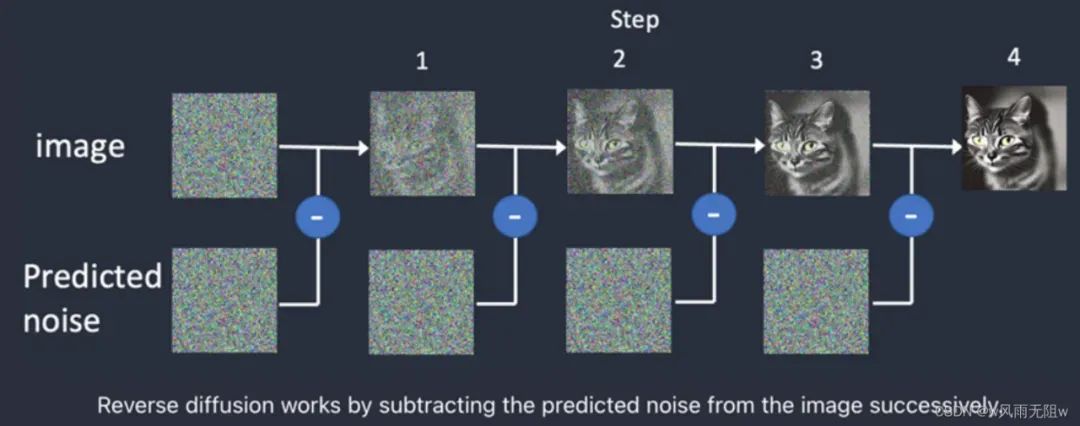
首先,为了生成图像, Stable Diffusion 会在潜在空间中生成一个完全随机的图像。其次,噪声预测器会估算图像的噪声。最后,噪声预测器从图像中减去预测的噪声。在这个过程反复重复 N 次以后,会得到一个干净准确的图像。以下是我总结的一些关于采样方法的说明:
如果想快速生成质量不错的图片
–建议选择 DPM++ 2M Karras (20 -30步) 、UNIPC (15-25步)
如果想要高质量的图
–不关心重现性,建议选择 DPM++ SDE Karras (10-15步 较慢) ,DDIM(10-15步 较快)
如果想要简单的图
–建议选择 Euler, Heun(可以减少步骤以节省时间)
如果想要稳定可重现的图像
–请避免选择任何祖先采样器(名字里面带a或SDE)
相反,如果想要每次生成不一样的图像
–可以选择不收敛的祖先采样器(名字里面带a或SDE)
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

 若有侵权,请联系删除
若有侵权,请联系删除
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









