




主要优化了以下内容, 提升了高光谱算法分类精度。
这篇的内容, 是在1.高光谱数据集深度学习分类和代码分析(实践代码)一基础上进行的优化, 提升精度。
1. 加载所有多个数据集
def load_multiple_self_datasets(datasets, have_background=True, balance_labels_num=0):
"""把多个数据集的 Patch 和 Label 直接拼在一起返回"""
all_patches = []
all_labels = []
for i, ds in enumerate(datasets, 1):
# print(f"\n=== 载入第 {i} 组数据集 ===")
data_cube, label_mat = load_self_data( # 得到的data_cube和label_mat都是二维数据(h, w, b)
ds["spectral_path"],
ds["labels_path"],
ds["height"],
ds["width"],
ds["num_bands"],
ds["label"]
)
uniqueLabels, labelCounts = np.unique(label_mat, return_counts=True)
# 竖条纹去噪
if need_destripe_filter_flag == True:
data_cube_destriped = destripe_by_col_median(data_cube) # 竖条纹去噪
else:
data_cube_destriped = data_cube # 不竖条纹去噪
# PCA 降维
if need_pca_flag == True:
pca_cube = apply_pca(data_cube_destriped) # PCA 降维
else:
pca_cube = data_cube_destriped # 不降维
# print("====原始加载数据集-- >pca_cube.shape:", pca_cube.shape)
# 切 Patch(按 have_background_flag 决定是否保留背景)
if have_background:
patches, patch_labels = create_patches_has_background(pca_cube, label_mat)
else:
patches, patch_labels = create_patches_no_background(pca_cube, label_mat)
all_patches.append(patches)
all_labels.append(patch_labels)
# print(f" 本数据集 patch 数: {patches.shape[0]}")
# 拼接所有数据集
X = np.concatenate(all_patches, axis=0)
y = np.concatenate(all_labels, axis=0)
return X, y
patches, patch_labels = load_multiple_self_datasets(
datasets_info,
have_background = have_background_flag,
balance_labels_num = BALANCE_LABELS_NUM
)
root_path = '/home/01bcd/01bcd_code/20_hyperspectral-image/datasets/self_datasets/01lwl_datasets/0807_0_1_2_3_4_5_6_labels/train_val_datasets/all_datasets'
datasets_info = collect_dataset_info(root_path)
做了三个修改:
(1) 把每个标注的类别数据放到各自类别的文件夹中, 里面的标注是按照块的方式标注, 是batch的数据(见下图)。
(2) 以前是加载一副图像的方式, 加载高光谱数据集, 现在改为用batch的方式加载, 每个类别进行加载.
(3) 加载后的高光谱数据做了patch操作, 形成统一尺寸的patch图像, 每个输入 patch 是 window × window × bands 的小区域,我现在用的是 (3, 3, 30), 而标签是 window × window 的中心像素类别。

2. 修改网络模型结构:
def build_patch_model(input_shape, num_classes):
model = Sequential([
Conv2D(64, (3,3), activation='relu', padding='valid', input_shape=input_shape),
BatchNormalization(),
Flatten(), # 因为没有padding='same',所以 (3,3)---> (1,1),直接flatten成向量
Dense(128, activation='relu'),
Dropout(0.5),
Dense(num_classes, activation='softmax') # 做softmax必须确保是one-hot 编码, patch_labels 在进入模型训练前,做了 to_categorical()
])
model.compile(optimizer=Adam(learning_rate=LEARNING_RATE),
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
模型结构优化:
(1) 高光谱的数据处理已经在前处理完成, 都已经是(window × window × bands), 所以定义的模型结构上不需要再加padding, 所以padding=‘valid’。
(2) 去掉了 MaxPooling 和 GlobalAveragePooling, 因为它们会严重破坏空间信息。
MaxPooling2D((2,2)) 会将 3×3 patch 变为 1×1,导致空间信息丢失,不适用于极小尺寸 patch。
GlobalAveragePooling2D() 是为整图分类准备的,等价于完全“忽略位置”并做特征平均,不适用于 patch-based 像素分类。
如果输入 patch 是 3×3 或 5×5 这么小,不要用 Pooling 层和 GAP 层,直接 flatten 或用 1×1 conv 提取全局特征。
(3) 减少了算法模型层数。
对 3×3 或 5×5 小 patch 进行分类时,模型太深反而学不到东西。例如:
用了 3 个 Conv2D,每层都有 32/64/128 个通道,但输入 patch 只有 3×3,再卷也卷不出空间关系了
输入 patch 太小,深层 Conv 的感受野根本没法扩展,只是在做“逐像素拟合”。
对小 patch,用 1-2 层卷积或者直接使用 Dense 层(把 patch flatten 后当作向量)
如果 window=5 或更大,也可以再保留一层 Conv + Padding=‘same’, 加大模型深度:
def build_patch_model(input_shape, num_classes):
model = Sequential([
Conv2D(32, (3,3), activation='relu', padding='valid', input_shape=input_shape),
BatchNormalization(),
Conv2D(64, (3,3), activation='relu', padding='valid'),
BatchNormalization(),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.5),
Dense(num_classes, activation='softmax')
])
model.compile(optimizer=Adam(learning_rate=LEARNING_RATE),
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
3. 模型训练
# 训练模型
with tf.device(gpu_device):
history = model.fit(
X_train_aug, y_train_aug,
validation_data=(X_val, y_val),
epochs=EPOCHS,
batch_size=BATCH_SIZE,
shuffle=True,
verbose=1,
callbacks=[early_stop, checkpoint_best, checkpoint_final] # 添加回调
)
解析:
在模型训练中, 添加best和last模型的保存,以及早停的处理, 能防止模型过拟合。
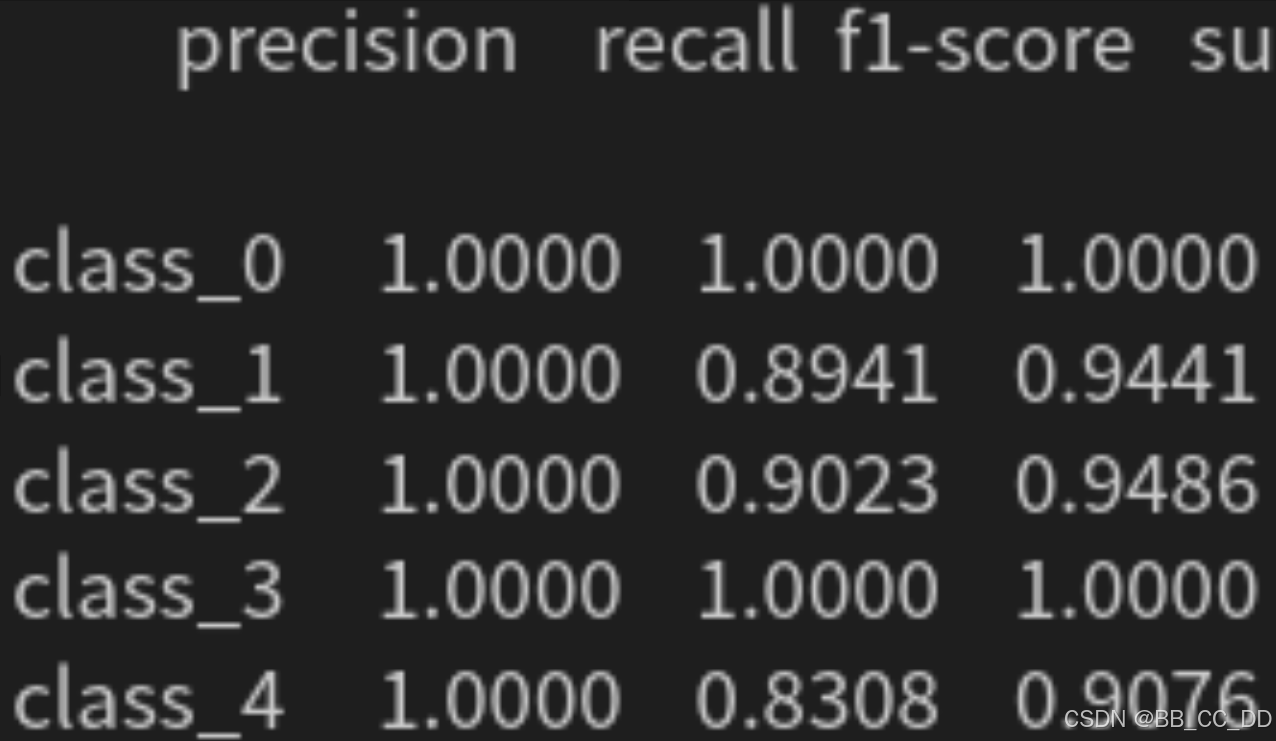
下面是训练后打印的模型指标:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











