







拜读好文章,做一下笔记

Code![]() https://github.com/QingyangZhang/DUL
https://github.com/QingyangZhang/DUL
Abstract
作者发现,SOTA方法的卓越 分布外(OOD)检测性能是通过暗中牺牲 OOD 泛化能力实现的。
具体地说,当这些模型遇到即使是很小的噪声,也可能使分类准确度急剧恶化。这一现象与模型可信性的目标相矛盾,严重限制了模型在现实场景中的适用性。
本文从理论上揭开了许多现有OOD检测方法中存在的“sensitive-robust”困境。因此,本文提出了一种基于理论启发的算法来解决这一难题,通过从贝叶斯的角度解耦不确定性学习目标,自然地协调了OOD检测和OOD泛化之间的冲突,并可期望获得双重最优性能。
据我们所知,这项工作是第一个有原则的 OOD 检测(principled OOD detection)方法,它在不影响 OOD 泛化能力的情况下实现了最先进的 OOD 检测性能。
通过检查OOD检测方法在加入轻微的噪音后的性能是否崩溃,发现其泛化能力是否退步。
Introduction
在开放环境中,模型需要同时具备两个能力:
- OOD检测能力:敏感地识别不属于已知类别的样本(语义OOD样本)。
- OOD泛化能力:在遇到协变量转移(如噪声、腐蚀)时仍能稳健地做出正确的预测。
看起来,OOD detection 和OOD generalization 任务的目标似乎是相反的:
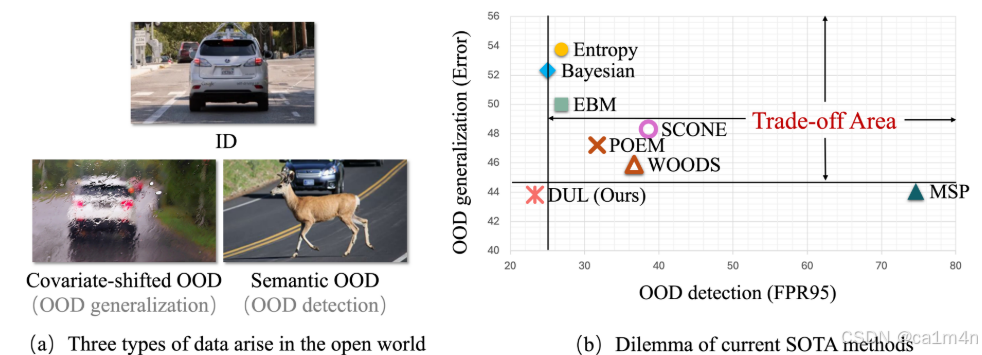
OOD detection 鼓励对未见数据进行敏感的不确定性感知(高度不确定的预测),而泛化则期望预测在不可预见的分布变化情况下具有信心和鲁棒性。以前在 OOD 检测研究领域的工作将 OOD 检测和 OOD 泛化之间的关系描述为一种权衡(trade-off),因此力求性能平衡。然而,这种权衡极大地限制了当前最先进的 OOD 检测方法的应用。当然,为了确保安全,我们可能会要求模型感知 OOD 输入,但肯定不会期望牺牲泛化能力,更不用说在噪声或损坏情况下灾难性地崩溃分类性能了。
在这项工作中,我们首先通过描述以往 OOD detection 方法的泛化误差下限(即 sensitive-robust dilemma),揭示了这一限制背后的潜在原因。为了克服这一困境,我们设计了一种新颖的去耦不确定性学习(Decoupled Uncertainty Learning, DUL)框架,以实现双优性能。
解耦不确定性分别负责表征语义 OOD(检测)和协变量偏移 OOD(泛化)。得益于解耦不确定性学习目标,OOD 检测和 OOD 概括的双优性能是可以预期的。我们的重点是分类任务中的一类特定 OOD 检测方法,包括基于最大softmax概率(MSP)的模型、基于能量的模型(EBM)和贝叶斯方法。这种选择具有两方面的优势。首先,MSP、EBM 和贝叶斯检测器涵盖了分类任务中 OOD 检测的主要进展。其次,在各种学习任务(分类、物体检测 、时间序列预测和图像分割)中开展的大量 OOD 检测工作都与分类大致相关。本文的贡献概述如下:
- 本文揭示了现有的SOTA OOD检测方法可能遭受灾难性的退化方面的OOD泛化。也就是说,它们的上级OOD检测能力是通过(秘密地)牺牲OOD泛化能力来实现的。我们从理论上揭示了学习目标中的sensitive-robust困境是这种限制背后的主要原因。
- 以往的研究将 OOD 检测和 OOD 泛化描述为相互冲突的学习任务,从而意味着不可避免的权衡取舍。与此不同,我们提出了一种称为 “解耦不确定性学习”(Decoupled Uncertainty Learning,DUL)的新型学习框架,成功突破了简单权衡取舍的限制。我们的 DUL 极大地协调了 OOD 检测和 OOD 泛化之间的冲突,在不牺牲 OOD 概括能力的情况下实现了最佳的 OOD 检测性能。
- 我们在标准基准上进行了广泛的实验,以验证我们的发现。我们的DUL实现双最佳OOD检测和OOD泛化性能。据我们所知,DUL是第一种获得最先进的OOD检测性能而不牺牲OOD泛化能力的方法。
Bayesian框架下的不确定性估计(Related Work)
在贝叶斯框架中,预测不确定性可以被视为输入样本是否倾向于OOD的指标。由于OOD样本在训练过程中未见过,因此其不确定性应高于 ID 样本。分类模型的总体预测不确定性可根据其来源分解为三个因素,包括数据不确定性(AU)、分布不确定性(DU)和模型不确定性(EU)。AU 衡量的是数据的自然复杂性(如类重叠、标签噪声),而 EU 则源于用有限的训练数据估计模型参数的难度。DU 是由于测试数据和训练数据的分布不匹配造成的。经典的测量方法可用于捕捉各种类型的不确定性,包括熵、互信息和差分熵。
OOD检测的敏感-鲁棒困境
本文提出了“敏感-鲁棒”困境,即优化OOD检测损失会使模型在语义OOD样本上做出高度不确定的预测,同时这种不确定性也影响模型对协变量转移的OOD样本表现,导致泛化错误下界的增加。这种损失函数设计虽然提升了OOD检测的准确性,但却降低了对环境噪声和分布变化的鲁棒性,进而造成分类性能显著下降。
差异不一致性(理论工具)
为了分析OOD检测损失如何影响泛化错误,文章引入了差异不一致性(Disparity Discrepancy)作为理论工具。这是一个衡量两个分布和
在假设空间
下的差异的指标:
其中是分布P上假设
之间的差异,通常通过总变差距离度量(TVD)。
这表明,OOD检测损失在语义OOD分布上的最小化也会影响到协变量转移分布
上的模型表现,因为这两个分布在输入空间可能具有相似性。
sensitive-robust dilemma
一、对于MSP检测器,模型在协变量转移的OOD数据上的泛化错误下界与语义OOD数据上的OOD检测损失负相关,公式如下:
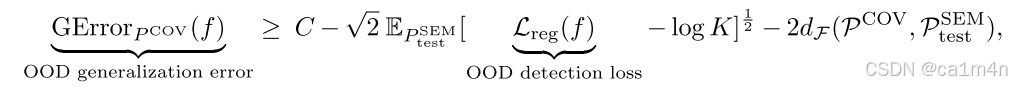
其中,是模型在
上的泛化错误;
是OOD检测损失(e.g., 交叉熵损失);
K是类别数;
C是假设空间和分布相关的常数;
是
和
之间的差异不一致性。
由此式,我们可以看到提高OOD检测性能(即降低OOD检测损失)会导致模型在协变量转移的(covariate-shifted)OOD数据上的泛化性能下降。
- 语义OOD和协变量转移OOD的相似性:由于现实中语义OOD和协变量转移的OOD数据可能在输入空间上存在一定的相似性,差异不一致性
不会很大。
- 损失函数的影响:在OOD检测中,模型被鼓励在语义OOD样本上产生高不确定性(high-entropy prediction)。由于差异不一致性较小,这种高不确定性会传播到covariate-shifted OOD数据上。
- 结果:模型在covariate-shifted OOD数据(应当泛化时)上也会产生高不确定性,导致预测结果不确定,泛化性能下降。
二、对于EBM方法的分析揭示了类似的问题
虽然EBM通过能量函数来区分ID和OOD样本,但在优化过程中,高能量(不确定性)也会影响到covariate-shifted OOD数据。
- 梯度影响:在训练过程中,EBM的梯度更新倾向于在OOD样本上降低对某些类别的置信度,从而增加不确定性(高不确定性)。
结论:由于在学习目标中,OOD检测损失和泛化性能之间存在冲突,最小化OOD检测损失会导致泛化错误下界增加。
Decoupled Uncertainty Learning(方法)
将不确定性解耦,分别处理语义OOD检测和协变量转移的OOD泛化。
与旨在寻求良好权衡的最相关的工作(SCONE)不同,DUL框架成功地摆脱了上述sensitive-robust dilemma。
- 高分布不确定性(distributional uncertainty, DU):在语义OOD样本上,鼓励模型的分布不确定性增加,以提高检测性能。
- 保持总不确定性不变:约束模型在OOD样本上的总不确定性(包括数据不确定性和分布不确定性)不增加,以保持泛化性能。
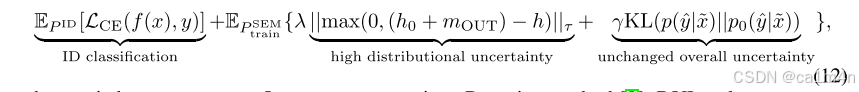 其中,
其中,是分布不确定性,
是初始分布不确定性;
第三项约束了总不确定性不增加;
是权重系数。
实验结果
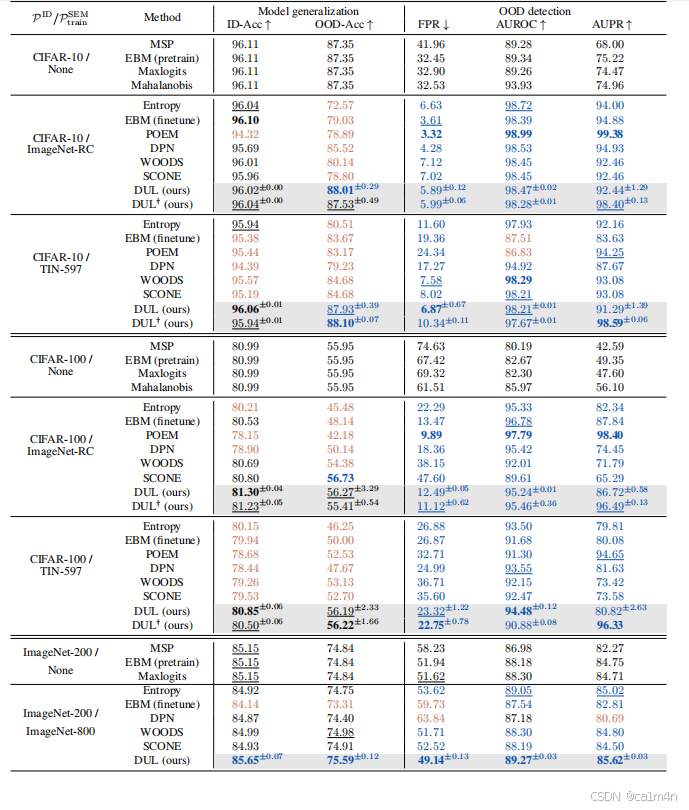
表 1:OOD检测和泛化性能比较。与基线 MSP (训练时未进行任何 OOD 检测正则化)相比,大幅提高(≥ 0.5)和降低分别以蓝色或红色标出。最佳和次佳结果以粗体或下划线表示。DUL 是唯一种在不牺牲泛化的情况下实现 SOTA OOD 检测性能(大部分为最佳或次佳)的方法,即整行的值为蓝色或黑色。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











