



 本文深入探讨了TreeSet和TreeMap的实现原理,重点介绍了它们的排序机制、元素去重方式以及如何通过自定义Comparator实现定制排序。此外,还讨论了在不同场景下使用这些集合时需要注意的问题。
本文深入探讨了TreeSet和TreeMap的实现原理,重点介绍了它们的排序机制、元素去重方式以及如何通过自定义Comparator实现定制排序。此外,还讨论了在不同场景下使用这些集合时需要注意的问题。
TreeSet
属于TreeSet的其实源码并不多,他的底层其实还是TreeMap,就行HashSet底层是HashMap那样,TreeSet是可排序的单列集合。TreeSet的排序功能其实是TreeMap来实现的,TreeSet的add方法实际上就是调用TreeMap的put方法。
TreeSet的两种排序:
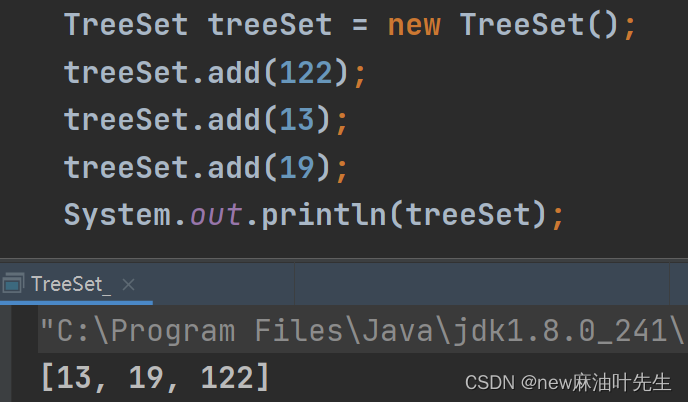
- 默认排序:底层是因为在TreeMap中实现SortMap接口,所以会有一个默认的排序升序功能。(前提是:传入的值都是同一个类型的,如下演示)
2.指定排序:底层是因为在TreeMap中有一个实现了Comparator接口,是他获得了一个比较器,如图

在使用指定排序的时候必须重写该接口,根据业务在方法体中定义想要的排序。
如图:
public int compare(Object o1, Object o2) {
String str1 = (String)o1;
String str2 = (String)o2;
//比较字符串的大小(遍历字符串的ASCII码的值来排序)
// return str1.compareTo(str2);//输出abcdef bc p
return -str1.compareTo(str2);//输出 p bc abcdef
// return str2.compareTo(str1);//输出 p bc abcdef
}
});
treeSet.add("abcdef");
treeSet.add("bc");
treeSet.add("p");
System.out.println(treeSet);
//注意当你添加的字符串的时候它调用的比较方法是String类中的compareTo方法,他不是计算总的字符串ASCII码,而是遍历比较字符的ASCII,比如“abcdefg”和“b”他的排序是“abcdefg” < “b”
,因为他遍历第一位字符a的时候字符a小于字符b,那么他就直接返回结果认定你这个“abcdefg”比“b”小。
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
String str1 = (String)o1;
String str2 = (String)o2;
//比较字符串长度(按照字符串长度来排序)
// return str1.length()-str2.length();//输出a abc abcd
// return str2.length()-str1.length();//输出abcd abc a
return -(str1.length()-str2.length());//输出abcd abc a
}
});
treeSet.add("abc");
treeSet.add("abcd");
treeSet.add("a");
System.out.println(treeSet);
千万注意:TreeSet的元素不能“重复”,这个“重复”与TreeSet的排序机制相关联的。
比如默认排序:
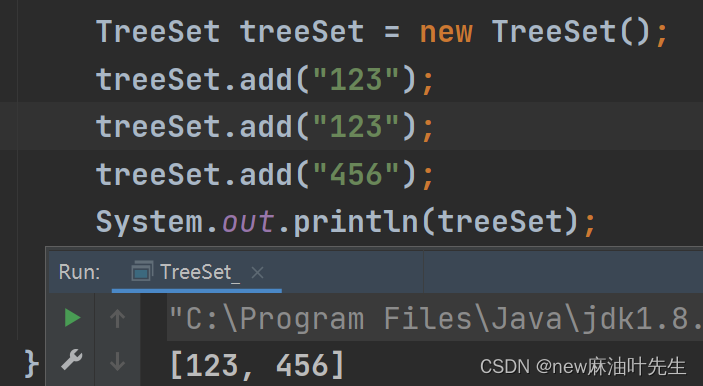
我们知道默认排序如果是字符串则按照遍历字符串的字符ASCII码升序排序,如果是整数类型则按照数值大小升序排序。所以现在评判添加元素首“重复”的标准是ASCII码唯一性。那么当你传入第二个“123”的时候他不再是按照经过算法转化哈希值得到索引下标而是直接判断当前储存空间有没有与“123”的ASII码大小一样的元素,如果有的话就存不进去。(注意这个ASCII码不是指字符串中的字符ASCII码值的总合,而是遍历字符一个一个的比较知道出现不相同的字符的时候就直接返回结果了)
再比如定制排序:
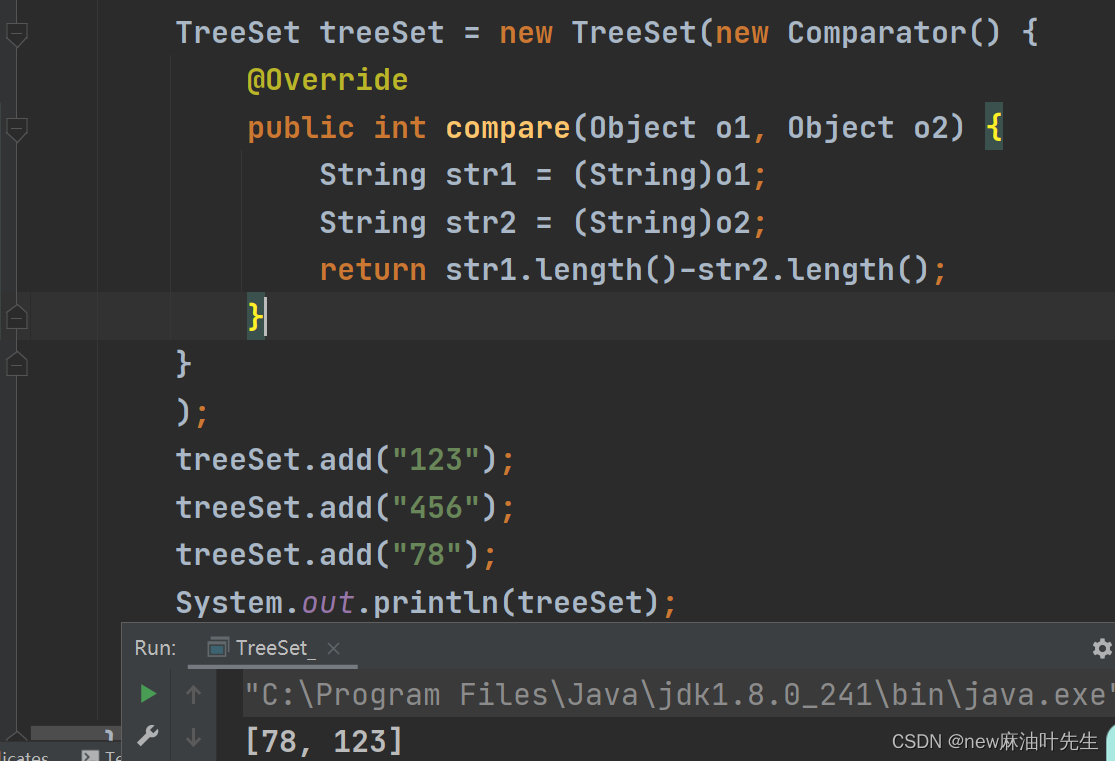
上面是按照字符串长度升序排序,此时添加元素是否“重复”的评判标准是字符串长度唯一性。当你添加“456”的时候,它的长度为3,与前面的“123”长度也为3重复了。所以添加失败。
TreeSet
在说说TreeMap,我们前面说了TreeSet的排序机制,其实底层就是TreeMap,唯一不一样的是TreeMap双列集合,他的排序是按照Key作为标准来排序的,也就是说再添加元素的时候Key是不能重复的,而value可以,再添加元素的时候TreeMap的key如果“重复”了则会覆盖前面的那个相同的key。不多说直接看演示吧。
自然排序:
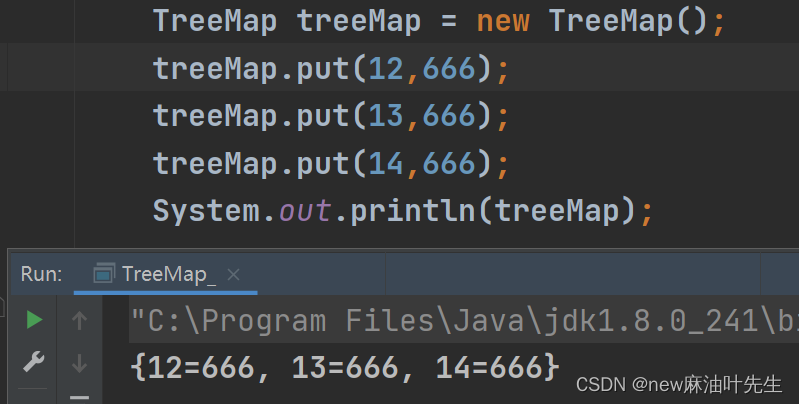
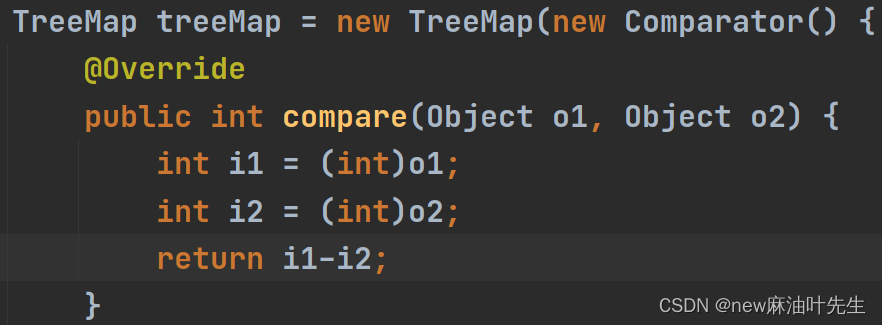
它的底层默认那个比较器是这样的,没啥好说的。注意是把key排序哦
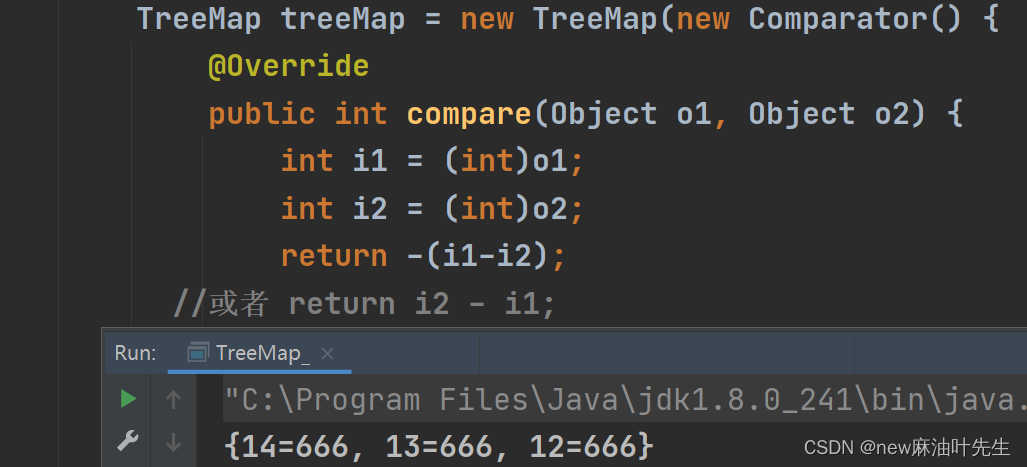
你要是想让他按照逆序的排序直接重写这个改一下返回值就可以了比如
按字符串比较:
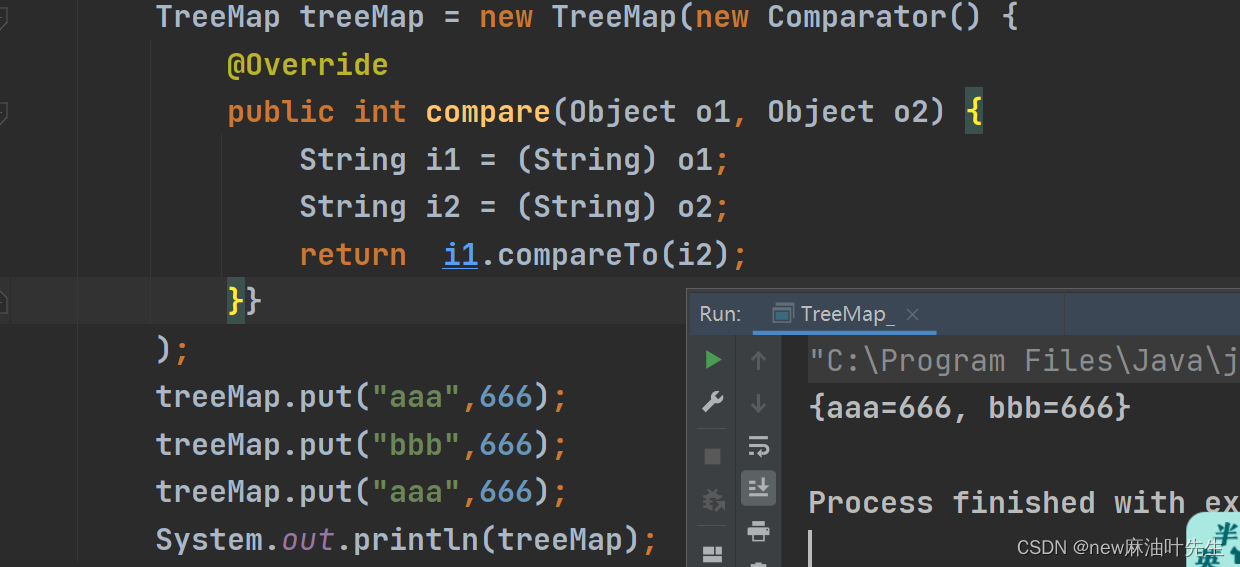
两个"aaa"用Comparator比较值相等判定为“重复”所以第二个“aaa”添加不进去。
TreeMap传入一个自定义类他的去重机制
来看一段代码:
TreeMap treemap = new TreeMap();
treemap.add(new Person());
class Person{}
问会不会报错???会!!!
前面说的如果往TreeMap里面添加int、String这些基本数据类型或者包装类他都不会报错,因为首先你只能传相同类型的对象比如我全部传int或者String他们都会有自然排序,但是你传一个自定义类型对象,我们你他按照啥排序???他不清楚你的comparator是判断啥,所以你要么在Person类中实现Comparable接口并且重写comparatTo方法让Person类对象也拥有自然排序,要么你就在newTree Map();的时候传入匿名对象conparator比较器,是他拥有定制排序。这样才不会报错。其实定制类的自然排序和定制排序都可由程序员自己决定。
其实TreeSet和TreeMap本质上没啥区别,因为TreeSet的代码底层还是一个TreeMap,这是两个可以自定义排序的集合,只要是在TreeMap的底层包含一个Comparator(比较工具),那么在你创建TreeSet或者TreeMap的时候就要求你传入一个匿名内部类——重写过后的Comparator,在这个匿名内部类你可以根据业务自定义排序功能。TreeSet比较的是你的那个单列值


















 1400
1400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











