







1.前言
生产环境的一次真实事件,应用使用druid连接数据库,其中有一个逻辑,是使用定时任务处理某张临时表中的待处理数据,处理完后从表中删除。
刚开始处理速度很慢,因为生产者的生产速度远大于消费者的消费速度,这就导致待处理数据越积越多,早上9点入表数据,到晚上10点才处理完。为了优化这种情况,增加了定时任务的线程数量,刚开始由3线程并发增加到20线程并发,效果有所好转,但是生产速度依然大于消费速度。
于是又由20线程并发增加到50线程并发。但是这次效果甚微,并且数据库服务器cpu报警,长时间处于高负荷状态,durid连接池与数据库的active连接数也逐渐达到最大值,从而后面的业务再也无法获取到连接而报错。
无奈只好将并发数调小,但是处理慢又成了大问题。后面分析了详细日志发现其中有几个sql执行都超过了15秒,这才导致了业务执行慢,从而线程无法释放数据库连接,使连接数达到最大值而报错。优化sql后,问题解决(本文只说数据库连接参数调优问题,优化sql放在下一篇)
2.报错如下

3.报错直接原因
首先看3个参数
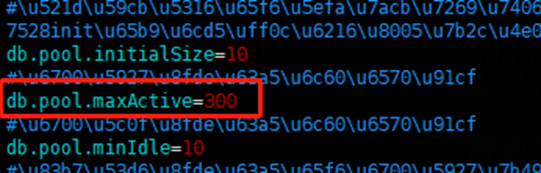
1)durid中配置参数最大活跃连接数量 maxActive
2)数据库配置最大session数量 session_per_user
(1)先根据用户名获取profile资源配置文件

(2)再根据profile获取session per user

3)当前数据库连接情况 active/inactive

我这里是测试环境,业务比较少,所以现在总的连接数只有初始化的10个加上新申请的1个,并且此时此刻11个连接均为inactive状态,新申请的1个如果长时间未使用也会根据durid中配置的超时参数进行回收
4)关系
durid中的maxActive 可以限制数据库中active最大值,session_per_user是限制数据库中total(active+inactive)最大值。一旦total等于session_per_user,应用就再也无法获取新连接,durid再获取连接时就会报上面的错。
4.结论
所以参数配置的原则应该为:
(1) 数据库session_per_user应尽可能满足数据库服务器的承受能力。
(2) durid中maxActive应该满足session_per_user。注意我这里测试环境是单应用连接但数据库,如果是应用集群应该满足maxActive乘以节点数量(几台应用)小于session_per_user;如果是数据库集群应该满足maxActive小于session_per_user乘以节点数量(几台数据库)
注意:理论上是不超过即可,但是考虑到可能有别的连接也使用此用户等特殊情况,一般是将maxActive总数配置成session_per_user的80%
附言:执行sql
-- 根据用户名获取profile资源配置名
select username,profile from dba_users where USERNAME = 'TEST_USER';
-- 根据profile名获取配置参数
select * from DBA_PROFILES where PROFILE = 'TEST_USER_PROFILE';
-- 获取当前数据库连接情况
select status,count(1) from GV$SESSION where username = 'TEST' group by status
union all
select 'TOTAL',count(1) from GV$SESSION where username = 'TEST' group by status;















 288
288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









