











一、聚簇索引(Clustered Index)
✅ 概念:
在 InnoDB 存储引擎中,聚簇索引就是数据本身,叶子节点中存储的是完整的行数据。每个表只能有一个聚簇索引,通常是主键。
📌 特点:
• 按照主键顺序物理存储。
• 非主键索引(即二级索引)的叶子节点,保存的是主键值,不是整行数据。
📚 使用场景:
• 用于主键查询非常频繁的表。
• 适合主键范围查询,比如时间戳范围、ID区间。
二、非聚簇索引(Secondary Index / 非聚集索引)
✅ 概念:
非聚簇索引(也叫辅助索引)是独立的一棵B+树,叶子节点存的是主键值(而不是行数据)。
📌 特点:
• 查询时要先通过非聚簇索引定位主键,再用主键去聚簇索引中找数据 → 这叫回表(下一节详解)。
• 一个表可以有多个非聚簇索引。
📚 使用场景:
• 查询频繁但不是主键字段,比如 name、email 等。
• 经常参与 where 条件的字段适合建非聚簇索引。
⸻
三、索引回表(Index Back to Table)
✅ 概念:
当使用非聚簇索引查询时,MySQL 只能通过索引定位到主键,再去聚簇索引树中查完整数据,这个过程就叫 回表。
📌 示例:
SELECT name FROM user WHERE email = 'a@example.com';
• email 上有非聚簇索引。
• 查询 email 命中索引后,返回主键 id。
• 再用主键去聚簇索引里找整行数据,取出 name。
📚 使用场景:
• 回表是成本高的操作,要避免频繁的回表。
• 如果查询字段能被索引包含,就能避免回表(见下一节:覆盖索引)。
四、索引覆盖(Covering Index)
✅ 概念:
如果查询所需的字段全部被索引包含(包含在非聚簇索引的 B+ 树里),就不需要回表,这个叫做 索引覆盖(Covering Index)。
📌 示例:
SELECT email FROM user WHERE email = 'a@example.com';
• email 既是查询条件也是查询字段。
• 直接从 email 索引中拿出数据,无需回表。
📚 使用场景:
• 高性能场景:构建“覆盖索引”来优化 SELECT 查询性能。
• 可以通过创建联合索引覆盖多个字段来优化慢查询。
五、索引下推(Index Condition Pushdown,ICP)
✅ 概念:
MySQL 5.6+ 的优化技术,在使用非聚簇索引扫描时,把WHERE 条件尽可能下推到存储引擎层进行过滤,减少回表的次数。
📌 举例:
SELECT * FROM user WHERE age > 20 AND name = 'Tom';
• 如果 name 有索引,传统做法是用 name 找主键,再回表判断 age > 20。
• 有了 ICP,InnoDB 可以在 索引扫描阶段提前过滤 age > 20。
📚 使用场景:
• 查询条件中一部分字段在索引中,一部分不在。
• 想减少回表次数,提高查询效率。
✅ 总结对比表格
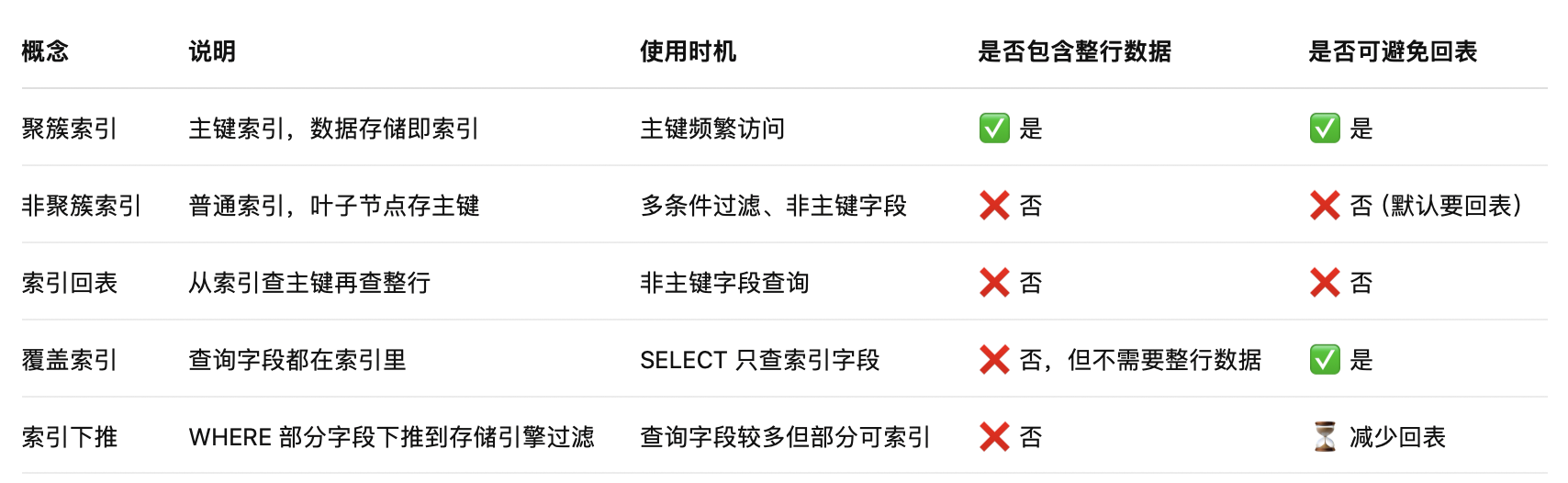
快速判断查询有没有“回表”、“用了覆盖索引”或“索引下推”,可以通过:
EXPLAIN SELECT ...
来看:
• Extra 字段中是否包含 Using index(表示覆盖索引);
• 是否有 Using index condition(表示用了索引下推);
• Using where; Using index 表示同时用了索引过滤和覆盖索引。
补充
InnoDB的普通索引叶子节点存储的是主键(聚簇索引)的值,而MyISAM的普通索引存储的是记录指针
Q:为什么非主键索引结构叶子结点存储的是主键值?
A:减少了出现行移动或者数据页分裂时二级索引的维护工作(当数据需要更新的时候,二级索引不需要修改,只需要修改聚簇索引,一个表只能有一个聚簇索引,其他的都是二级索引,这样只需要修改聚簇索引就可以了,不需要重新构建二级索引)
在使用非聚集索引时,为了取到具体数据,则需要通过PK回到聚集索引里去查询数据。这就叫回表查询,扫描了2次索引树,所以效率相对较低。


















 546
546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











