






The Article is From: https://dzone.com/refcardz/getting-started-apache-hadoop
Written by Piotr Krewski Hadoop consultant, getindata
Adam Kawa Hadoop Developer, ICM Warsaw University
简介:涵盖Hadoop的最重要的概念,描述其架构,并解释如何开始使用它。
建议先看英文再看翻译:翻译使用的是Google翻译。
第一部分
介绍
Refcard提供了Apache Hadoop,它是一个软件框架,它使用简单的高级编程模型实现大型数据集的分布式存储和处理。我们涵盖了Hadoop的最重要的概念,描述其架构,指导如何开始使用它,以及在Hadoop上编写和执行各种应用程序。
简而言之,Hadoop是Apache软件基金会的一个开源项目,可以安装在一组标准机器上,以便这些计算机可以进行通信和协同工作,以存储和处理大型数据集。Hadoop由于其有效地压缩大数据的能力,近年来已经变得非常成功。它允许公司将其所有数据存储在一个系统中,并对这些数据执行分析,否则这些数据将不可能或者与传统解决方案相比非常昂贵。
基于Hadoop的许多协同工具提供了各种各样的处理技术。与辅助系统和实用程序的集成非常好,使得Hadoop的现实工作更容易,更高效。这些工具一起构成了Hadoop生态系统。
热心提示:访问http://hadoop.apache.org以获取有关项目的更多信息并访问详细文档。
注意:通过标准机器,我们指的是许多供应商提供的典型服务器,并且具有预期会发生故障并在常规基础上更换的组件。因为Hadoop规模很好,并提供了许多容错机制,您不需要打破银行采购昂贵的顶端服务器,以最大限度地减少硬件故障的风险,增加存储容量和处理能力。
第二部分
设计概念
为了解决处理和存储大型数据集的挑战,Hadoop根据以下核心特性构建:
- 分布 - 而不是构建一个大的超级计算机,存储和处理分散在一组较小的机器,通信和协同工作
- 水平可扩展性 - 只需添加新机器即可轻松扩展Hadoop集群。每个新机器增加了Hadoop集群的总存储和处理能力
- 容错 - 即使少数硬件或软件组件无法正常工作,Hadoop仍可继续运行。成本优化 - Hadoop在标准硬件上运行;它不需要昂贵的服务器
- 编程抽象 - Hadoop负责处理与分布式计算相关的所有混乱细节。由于高级API,用户可以专注于实现解决他们现实世界问题的业务逻辑
- 数据位置 - 不需要将大数据集移动到应用程序正在运行的位置,而是运行数据已经在的应用程序
第三部分
Hadoop组件
Hadoop分为两个核心组件:
- HDFS - 分布式文件系统
- YARN - 集群资源管理技术
热心提示:许多执行框架在YARN之上运行,每个都针对特定的用例进行调整。最重要的是在下面的“YARN应用程序”下讨论。
让我们仔细看看他们的架构,并描述他们如何合作。
注意:YARN是替换Hadoop中的前一个处理层实现的新框架。你可以找到YARN如何解决以前版本在雅虎博客上的缺点:https://developer.yahoo.com/blogs/hadoop/next-generation-apache-hadoop-mapreduce-3061.html.
第四部分
HDFS
HDFS是一个Hadoop分布式文件系统。它可以安装在商用服务器上,并根据需要运行在任意数量的服务器上 - HDFS可轻松扩展到数千个节点和PB级数据。
较大的HDFS设置是,一些磁盘,服务器或网络交换机将失败的可能性更大。HDFS通过在多个服务器上复制数据来保存这些类型的故障。HDFS自动检测到给定组件已失败,并采取对用户透明发生的必要恢复操作。
HDFS设计用于存储大量数百兆字节或千兆字节的大文件,并为它们提供高吞吐量流式数据访问。最后但同样重要的是,HDFS支持一次写多读模型。对于这个用例HDFS工作像一个魅力。但是,如果您需要存储大量具有随机读写访问权限的小文件,则其他系统(如RDBMS和Apache HBase)可以做得更好。
注意:HDFS不允许您修改文件的内容。只有在文件末尾追加数据的支持。然而,Hadoop设计有HDFS作为许多可插拔存储选项之一 - 例如,使用MapR-Fs(专有文件系统),文件是完全读写的。其他HDFS备选方案包括Amazon S3和IBM GPFS。
HDFS架构
HDFS由在所选群集节点上安装和运行的以下守护程序组成:
- NameNode - 负责管理文件系统命名空间(文件名,权限和所有权,最后修改日期等)并控制对存储在HDFS中的数据的访问的主进程。它是一个有完整的分布式文件系统概述的地方。如果NameNode关闭,您将无法访问您的数据。如果你的命名空间永久丢失,你基本上丢失了所有的数据!
- DataNodes - 负责存储和提供数据的从属进程。DataNode安装在集群中的每个工作节点上。
图1说明了在4节点集群上安装HDFS。 其中一个节点托管NameNode守护程序,而其他三个节点运行DataNode守护程序。

注意:NameNode和DataNode是在Linux发行版之上运行的Java进程,例如RedHat,Centos,Ubuntu等。它们使用本地磁盘存储HDFS数据。
HDFS将每个文件拆分为一个更小,但仍然很大的块序列(默认块大小等于128MB - 更大的块意味着更少的磁盘寻道操作,这导致大的吞吐量)。每个块都冗余存储在多个DataNode上,用于容错。块本身不知道它属于哪个文件 - 此信息仅由具有HDFS中所有目录,文件和块的全局图片的NameNode维护。
图2示出了将文件分割为块的概念。 文件X被分割成块B1和B2,文件Y仅包括一个块B3。 所有块在集群内复制2次。如上所述,关于哪些块构成文件的信息由NameNode保存,而原始数据由DataNode存储。

与HDFS交互
HDFS提供了一个简单的类似POSIX的接口来处理数据。使用hdfs dfs命令执行文件系统操作。
热心提示:要开始使用Hadoop,您不必经历设置整个群集的过程。Hadoop可以在单个机器上以所谓的伪分布式模式运行。您可以下载沙箱虚拟机,所有HDFS组件已安装,并开始使用Hadoop在任何时间!只需按照以下链接之一:
http://www.mapr.com/products/mapr-sandbox-hadoop
http://hortonworks.com/products/hortonworks-sandbox/#install
http://www.cloudera.com/downloads/quickstart_vms/5-7.html
以下步骤说明了HDFS用户可以执行的典型操作:
#列出主目录的内容
$ hdfs dfs -ls /user/adam#将文件从本地文件系统上传到HDFS
$ hdfs dfs -put songs.txt /user/adam# 从HDFS读取文件的内容
$ hdfs dfs -cat /user/adam/songs.txt# 更改文件的权限
$ hdfs dfs -chmod 700 /user/adam/songs.txt#将文件的复制因子设置为4
$ hdfs dfs -setrep -w 4 /user/adam/songs.txt# 检查文件的大小
$ hdfs dfs -du -h /user/adam/songs.txt#将文件移动到新创建的子目录
$ hdfs dfs -mv songs.txt songs/#从HDFS中删除目录
$ hdfs dfs -rm -r songs热心提示:您可以键入hdfs dfs而不使用任何参数来获取可用命令的完整列表。
第五部分
YARN
YARN是一个框架,用于管理集群上的资源,并允许运行各种分布式应用程序来处理存储(通常)在HDFS上的数据。
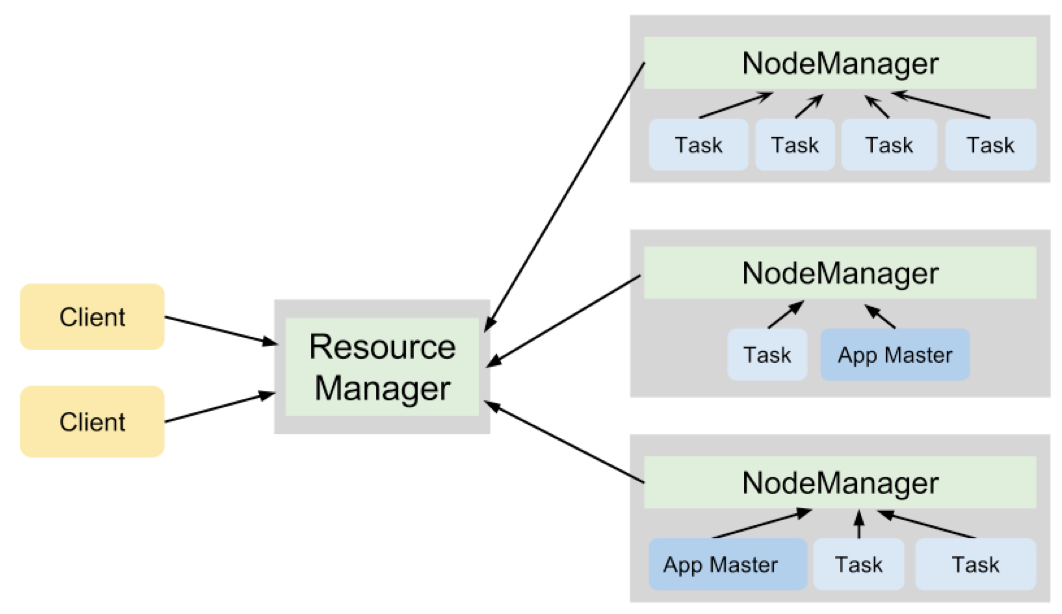
YARN与HDFS类似,遵循具有单个ResourceManager守护程序和多个NodeManager守护程序的主从设计。 这些类型的守护程序具有不同的职责。
ResourceManager
- 跟踪活动的NodeManager和它们当前可用的计算资源的数量
- 为客户端提交的应用程序分配可用资源
- 监视应用程序是否成功完成
NodeManagers
- 以容器的形式提供计算资源
- 在容器中运行各种应用程序的任务
YARN以表示诸如存储器和CPU的资源元素的组合的资源容器的形式向各种应用分配集群资源。
在YARN群集上执行的每个应用程序都有自己的ApplicationMaster进程。 此过程在应用程序在集群上调度并协调此应用程序中所有任务的执行时开始。
每个任务在由所选NodeManager管理的容器内运行。 ApplicationMaster与ResourceManager协商资源(以容器的形式)。在成功协商后,ResourceManager向ApplicationMaster提交容器规范。然后将此规范切换到启动容器并在其中执行任务的NodeManager。
图3说明了YARN守护进程在运行两个应用程序的4节点集群上的合作,这些应用程序总共产生了7个任务。
Hadoop 2.0 = HDFS + YARN
在同一集群上运行的HDFS和YARN守护进程为我们提供了一个强大的平台来存储和处理大型数据集。
有趣的是,DataNode和NodeManager进程并置在同一个节点上,以实现称为数据本地化的Hadoop最大的优点之一。 数据局部性允许我们在实际存储数据的机器上执行计算,从而最小化通过网络发送大块数据的必要性。 这种称为“向数据发送计算”的技术在处理大数据时显着提高性能。

图4:在Hadoop集群上并置HDFS和YARN守护程序。
第六部分
YARN应用程序
YARN只是一个知道如何为在Hadoop集群上运行的各种应用程序分配分布式计算资源的资源管理器。换句话说,YARN本身不提供可以分析HDFS中的数据的任何处理逻辑。因此,各种处理框架必须与YARN(通过提供ApplicationMaster的特定实现)集成以在Hadoop集群上运行并在HDFS中处理数据。
下表提供了可在由YARN提供支持的Hadoop集群上运行的最流行的分布式计算框架的列表和简短描述。
MapReduce 是Hadoop最流行的处理框架,将计算表示为一系列map和reduce任务。MapReduce将在下一节中解释.Apache SparkA是一种用于大规模数据处理的快速和通用引擎,通过积极地在内存中缓存数据来优化计算.Apache Tez将MapReduce范例通用为一个更强大和更快的框架,以复杂的有向无环一般数据处理任务的图形.Apache Giraph大数据的迭代图处理框架.Apache StormA实时流处理引擎.Cloudera Impala基于Hadoop的SQL。
第七部分
MapReduce
MapReduce是一个允许实现并行分布式算法的编程模型。 要在这个范例中定义计算,您需要为两个函数提供逻辑:map()和reduce(),它们对<key,value>对进行操作。
映射函数取一个<key,value>对,并生成零个或多个中间<key,value> 对:
Map(k1, v1) -> list(k2, v2)减少函数获取一个键和与该键相关联的值的列表,并产生零个或多个最终<key,value>对:
Reduce(k2, list(v2)) -> list(k3, v3)在Map和Reduce函数之间,Map函数产生的所有中间<key,value>对都通过key进行重排和排序,以便将与同一个键相关联的所有值组合在一起并传递给同一个Reduce函数。

Map函数的一般用途是变换或过滤输入数据。 另一方面,Reduce函数通常聚合或汇总Map函数产生的数据。
图6显示了使用MapReduce计算句子中不同单词出现次数的示例。 映射函数拆分语句并产生中间的<key,value>对,其中键是单词,值等于1.然后reduce函数将与给定单词相关联的所有1相加,返回该单词的总出现次数。

第八部分
YARN上的MapReduce
MapReduce 在YARN上是一个框架,支持在由YARN提供支持的Hadoop集群上运行MapReduce作业。它提供了一个高级API,用于实现各种语言的自定义Map和Reduce功能,以及提交,运行和监视MapReduce作业所需的代码基础设施。
注意:MapReduce是历史上唯一可以与Hadoop一起使用的编程模型。在YARN推出后就不再是这样。但MapReduce仍然是在YARN集群上运行的最流行的应用程序。
每个MapReduce作业的执行由称为MapReduce应用程序主(MR AM)的特殊进程的实例管理和协调。MR AM生成运行map()函数的Map任务和运行reduce()函数的Reduce任务。每个Map任务处理输入数据集的单独子集(默认情况下为HDFS中的一个块)。每个reduce任务处理由Map任务生成的中间数据的单独子集。此外,Map和Reduce任务彼此独立运行,允许并行和容错计算。
为了优化计算,MR AM尝试调度数据本地Map任务。这些任务在与已存储我们要处理的数据的DataNodes并置的NodeManager上运行的容器中执行。因为默认情况下HDFS中的每个块都被冗余地存储在三个DataNode上,所以有三个NodeManager可以被要求在本地运行给定的Map任务。
第九部分
提交MapReduce作业
让我们看看MapReduce在操作中,并在Hadoop集群上运行MapReduce作业。
为了快速入门,我们使用一个随Hadoop软件包提供的MapReduce示例的jar文件。 在Linux系统上可以找到:
/usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar我们运行上一节中解释的字数统计作业。
#创建一个名为hamlet.txt的文件,其具有以下内容:
To be or not to be#在HDFS上上传输入数据
# hdfs dfs -mkdir input#将WordCount MapReduce作业提交到集群:
# hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar wordcount input hamlet-output成功提交后,在ResourceManager Web UI上跟踪此作业的进度。
热心提示:如果您使用沙箱,则ResourceManager UI可用于http:// localhost:8088
图7:带有运行作业的ResourceManager UI

#在HDFS中检查此作业的输出
# hadoop fs -cat hamlet-output/*除了字计数作业,jar文件包含几个其他MapReduce示例。您可以通过键入以下命令来列出它们:
# hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar下表提供了一些有趣的MapReduce示例的列表和简短描述:
grepCounts使用准蒙特卡罗方法对输入数据集中的给定正则表达式匹配.piEstimates Pi.terasort对输入数据集进行排序。经常与teragen和teravalidate联合使用。查找更多详情:https://hadoop.apache.org/docs/current/api/org/apache/hadoop/examples/terasort/package-summary.html
wordmeanCounts输入数据集中单词的平均长度。
第十部分
处理框架
在本地MapReduce中开发应用程序可能是一个耗时且令人沮丧的工作,仅为程序员保留。
幸运的是,有一些框架使得在Hadoop集群上实现分布式计算的过程变得容易和快速,甚至对于非开发人员也是如此。 最受欢迎的是Hive和Pig。
Hive
Hive提供了一种类似SQL的语言,称为HiveQL,用于更容易地分析Hadoop集群中的数据。当使用Hive时,我们在HDFS中的数据集表示为具有行和列的表。因此,Hive易于学习和吸引,以便用于那些已经知道SQL并具有处理关系数据库经验的人。
有了这个说法,Hive可以被看作是建立在Hadoop之上的数据仓库基础设施。
Hive查询被翻译成随后在Hadoop集群上执行的一系列MapReduce作业(或者Tez有向无环图)。
Hive示例
让我们处理关于在给定时间内用户收听的歌曲的数据集。 输入数据包含一个制表符分隔的文件songs.txt:
“Creep” Radiohead piotr 2014-07-20
“Desert Rose” Sting adam 2014-07-14
“Desert Rose” Sting piotr 2014-06-10
“Karma Police” Radiohead adam 2014-07-23
“Everybody” Madonna piotr 2014-07-01
“Stupid Car” Radiohead adam 2014-07-18
“All This Time” Sting adam 2014-07-13我们使用Hive在2014年7月找到两个最受欢迎的艺术家:
注意:我们假设以下命令作为用户“training”执行。
##将songs.txt文件放在HDFS上:
# hdfs dfs -mkdir songs
# hdfs dfs -put songs.txt songs/##进入Hive:
# hive
hive>##在Hive中创建一个外部表,为HDFS上的数据提供一个模式
hive> CREATE TABLE songs(
title STRING,
artist STRING,
user STRING,
date DATE
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\t’
LOCATION ‘/user/training/songs’;##检查表是否已成功创建:
hive> SHOW tables;您还可以查看表的属性和列:
##除了有关列名称和类型的信息之外,您还可以看到其他有趣的属性:
# Detailed TableInformation
Database: default
Owner: root
CreateTime: Tue Jul 29 14:08:49 PDT 2014
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://localhost:8020/user/root/songs
Table Type: EXTERNAL_TABLE##在2014年7月运行查找两个最受欢迎的艺术家的查询:
SELECT artist,COUNT(*) AS total
FROM songs
WHERE year(date) = 2014 AND month(date) = 7
GROUP BY artist
ORDER BY total DESC
LIMIT 2;此查询将转换为两个MapReduce作业。 通过读取由Hive客户端生成的标准输出日志消息或通过使用ResourceManager WebUI跟踪在Hadoop群集上执行的作业来验证它。
注意:在撰写本文时,MapReduce是Hive的默认执行引擎。 它可能在未来改变。 有关如何为Hive设置其他执行引擎的说明,请参阅下一节。
Tez
Hive不限制只将查询转换为MapReduce作业。您还可以指示Hive使用其他分布式框架(如Apache Tez)表达其查询。
Tez是一个有效的框架,以任务的DAG(有向无环图)的形式执行计算。 使用Tez,复杂的Hive查询可以表示为单个TezDAG而不是多个MapReduce作业。这样我们不会引入启动多个作业的开销,并避免在HDFS的作业之间存储数据的成本,这些都节省了I / O。
要受益于Tez的快速响应时间,只需覆盖hive.execution.engine属性并将其设置为tez。
按照以下步骤将上一节中的Hive查询作为Tez应用程序执行:
##进入Hive
# hive
hive>hive> SET hive.execution.engine=tez;从Hive部分执行查询:
注意:现在您可以看到在控制台上显示的不同日志在MapReduce上执行查询时:
Total Jobs = 1
Launching Job 1 out of 1
Status: Running application id: application_123123_0001
Map 1: -/- Reducer 2: 0/1 Reducer 3: 0/1
Map 1: 0/1 Reducer 2: 0/1 Reducer 3: 0/1
…
Map 1: 1/1/ Reducer 2: 1/1 Reducer 3: 1/1
Status: Finished successfully
OK
Radiohead 3
Sting 2该查询现在仅作为一个Tez作业执行,而不是像以前一样执行两个MapReduce作业。Tez没有绑定到严格的MapReduce模型 - 它可以在单个作业中执行任意序列的任务,例如Reduce任务后减少任务,带来显着的性能优势。
了解更多关于Tez的博客: http://hortonworks.com/blog/apache-tez-a-new-chapter-in-hadoop-data-processing.
Pig
Apache Pig是另一个用于Hadoop大规模计算的流行框架。与Hive类似,Pig允许您以比使用MapReduce更简单,更快,更简单的方式实现计算。 Pig引入了一种简单但功能强大,类似脚本的语言PigLatin。PigLatin支持许多常见的和即用的数据操作,如过滤,聚合,排序和连接。 开发人员还可以实现扩展Pig核心功能的自己的函数(UDF)。
与Hive查询一样,Pig脚本也转换为计划在Hadoop集群上运行的MapReduce作业。
我们使用Pig找到最流行的艺术家,就像我们在前面的例子中使用Hive。
##将以下脚本保存在top-artists.pig文件中
a = LOAD ‘songs/songs.txt’ as (title, artist, user,date);
b = FILTER a BY date MATCHES ‘2014-07-.*’;
c = GROUP b BY artist;
d = FOREACH c GENERATE group, COUNT(b) AS total;
e = ORDER d by total DESC;
f = LIMIT e 2;
STORE f INTO ‘top-artists-pig’;##在Hadoop集群上执行pig脚本:
# pig top-artists.pig读取输出目录的内容:
热心提示:当开发Pig脚本时,您可以在本地模式下进行迭代,并在向集群提交作业之前捕获错误。要启用本地模式,请向pig命令添加-x local选项。
总结
Apache Hadoop是用于大数据处理的最流行的工具之一,这得益于其高级API,可扩展性,在商用硬件上运行的能力,容错和开源性质等强大的功能。Hadoop已经被许多公司成功部署在生产中了几年。
Hadoop生态系统提供各种开源工具,用于收集,存储和处理数据,以及集群部署,监控和数据安全。 由于这个令人惊叹的工具生态系统,每个公司现在可以轻松,相对便宜地以分布式和高度可扩展的方式存储和处理大量数据。
Hadoop生态系统
此表包含Hadoop生态系统中最有用和最受欢迎的项目的名称和简短描述,这些项目尚未提及:
OozieWorkflow调度程序系统来管理Hadoop jobs.ZookeeperFramework,实现高度可靠的分布式协调.SoopTool用于在Hadoop和结构化数据存储(如关系数据库)之间高效传输批量数据.FlumeService用于聚合,收集和移动大量日志数据.HbaseNon-关系,分布式数据库运行在HDFS之上。 它可以随机实时读/写访问您的大数据。
第十一部分
额外资源















 2230
2230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









