






The Article Is From:https://examples.javacodegeeks.com/enterprise-java/apache-hadoop/how-to-install-apache-hadoop-on-ubuntu/
建议先看英文再看翻译:翻译使用的是Google翻译。
关于作者:Ramaninder毕业于德国Georg-August大学计算机科学与数学系,目前与奥地利的大数据研究中心合作。他拥有应用计算机科学硕士学位,专业应用系统工程和商业信息学。 他也是一名微软认证过程,在Java,C#,Web开发和相关技术方面有超过5年的经验。目前,他的主要兴趣是大数据生态系统,包括批处理和流处理系统,机器学习和Web应用程序。
在这个例子中,我们将看到如何在Ubuntu系统上安装Apache Hadoop的细节。
我们将完成所有必需的步骤,从Apache Hadoop所需的先决条件开始,然后是如何配置Hadoop,我们将通过学习如何将数据插入Hadoop以及如何对该数据运行示例作业来完成此示例。
1.介绍
该示例将描述在Ubuntu 15.10上安装单节点Apache Hadoop集群的所有必需步骤。Hadoop是用于大型商品硬件群集上的应用程序的分布式处理的框架。 它是用Java编写的,并遵循MapReduce计算范式。
2.先决条件
以下是在Ubuntu上运行Apache Hadoop的先决条件。按照步骤获取所有必要条件。
2.1安装Java
由于Apache Hadoop是用Java编写的,因此需要在系统中安装最新的Java。要安装Java,首先更新源列表:
#Update the source list
sudo apt-get update它应该更新所有现有的软件包,如下面的屏幕截图所示。

现在使用以下命令安装默认jdk。
# The OpenJDK project is the default version of Java
sudo apt-get install default-jdkOpenJDK是Ubuntu Linux的Java的默认版本。 它应该使用apt-get命令成功安装。

default-jdk安装1.7版本的Java。 1.7版本可以运行Hadoop,但如果你愿意,你可以明确地安装版本1.8。
#Java Version
java -version
这完成了Apache Hadoop的第一个先决条件。 接下来,我们将转向创建Hadoop可用于执行其任务的专用用户。
2.2创建专用用户
Hadoop需要一个单独的专用用户来执行。 具有对Hadoop可执行文件和数据文件夹的完全控制。要创建新用户,请在终端中使用以下命令。
#create a user group for hadoop
sudo addgroup hadoop
#create user hduser and add it to the hadoop usergroup
sudo adduser --ingroup hadoop hduser第一个命令创建一个名为“hadoop”的新组,第二个命令创建一个新用户“hduser”并将其分配给“hadoop”组。我们保留所有的用户数据,如“名字”,“电话号码”等空。 您可以将其保留为空,或根据您的选择向帐户分配值。

2.3禁用ipv6
下一步是在所有机器上禁用ipv6。 Hadoop设置为使用ipv4,这就是为什么我们需要在创建hadoop集群之前禁用ipv6。使用nano(或您选择的任何其他编辑器)以root身份打开/etc/sysctl.conf:
sudo nano /etc/sysctl.conf并在文件末尾添加以下行:
#commands to disable ipv6
net.ipv6.conf.all.disable-ipv6=1
net.ipv6.conf.default.disable-ipv6=1
net.ipv6.conf.lo.disable-ipv6=1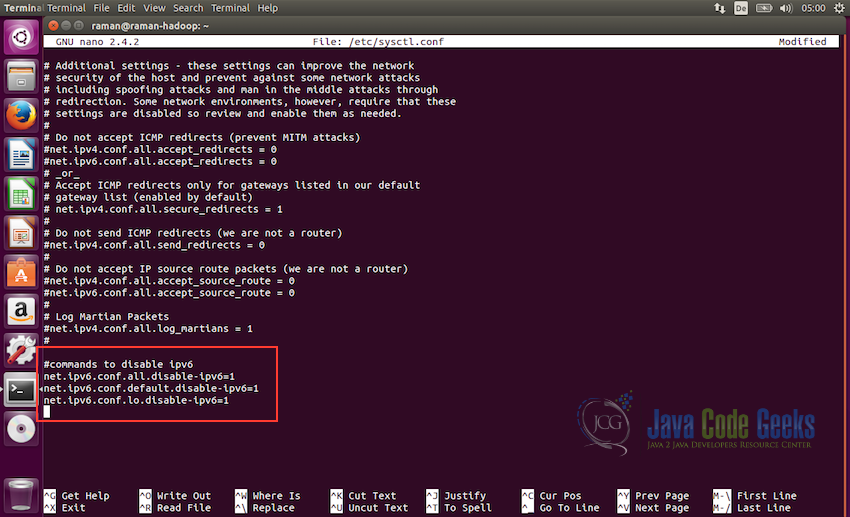
当提示保存文件时,使用ctrl + X保存文件,然后选择是。之后,要检查ipv6是否正确禁用,我们可以使用以下命令:
cat /proc/sys/net/ipv6/conf/all/disable-ipv6它应该返回0或1作为输出,我们希望它为1,因为它象征着ipv6被禁用。
2.4安装SSH和设置证书
Hadoop需要SSH访问来管理其远程节点以及本地机器上的节点。对于此示例,我们需要配置SSH访问localhost。
因此,我们将确保我们已经启动并运行SSH并设置公钥访问权限,以允许它在没有密码的情况下登录。 我们将设置SSH证书以允许密码较少的身份验证。使用以下命令执行所需的步骤。
ssh有两个主要组件:
- ssh:我们用来连接远程机器的命令 - 客户端
- sshd:在服务器上运行并允许客户端连接到服务器的守护程序
SSH在Ubuntu上预先启用,但为了确保sshd启用,我们需要使用以下命令首先安装ssh。
#installing ssh
sudo apt-get install ssh要确保一切都正确设置,请使用以下命令,并确保输出与屏幕截图中显示的类似。
#Checking ssh
which ssh
#Checking sshd
which sshd上述命令都应该显示安装ssh和sshd的文件夹的路径,如下面的屏幕截图所示。这是为了确保两者都存在于系统中。

现在,为了生成ssh证书,我们将切换到hduser用户。在以下命令中,我们保持密码为空,同时生成ssh的密钥,如果您愿意,可以给它一些密码。
#change to user hduser
su hduser
#generate ssh key
ssh-keygen -t rsa -P "" 第二个命令将为机器创建一个RSA密钥对。 此键的密码将为空,如命令中所述。它将要求存储密钥的路径,默认路径为$ HOME / .ssh / id-rsa.pub,当提示保持同一路径时,按Enter键。 如果您计划更改路径,请记住它,因为它将在下一步中需要。

使用上一步中创建的密钥启用对机器的SSH访问。为此,我们必须将密钥添加到机器的授权密钥列表。
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys我们可以检查ssh是否工作如下,是ssh到localhost成功没有密码提示,然后证书正确启用。
ssh localhost到目前为止,我们已经完成了Apache Hadoop的所有先决条件。我们将在下一节中检查如何设置Hadoop。
3.安装Apache Hadoop
在所有先决条件之后,我们准备在我们的Ubuntu 15.10机器上安装Apache Hadoop。
3.1下载Apache Hadoop
1.从Apache Mirrors下载Hadoop,网址为www.apache.org/dyn/closer.cgi/hadoop/core。它可以手动下载或使用wget命令。
2.下载完成后,解压hadoop文件夹并将其移动到/ usr / local / hadoop,最后更改文件夹的所有者为hduser和hadoop组。
#Change to the directory
cd /usr/local
#move hadoop files to the directory
sudo mv /home/hadoop1/Downloads/hadoop-2.7.1 hadoop
#change the permissions to the hduser user.
sudo chown -R hduser:hadoop hadoop我们现在可以使用命令检查hadoop文件夹的权限:
ls -lah此命令显示/ usr / local /目录中的内容列表以及元数据。Hadoop fodler应该有hduser作为所有者,hadoop作为用户组,如下面的屏幕截图所示。

3.2更新bash
1.更新用户hduser的bashrc文件。
su - hduser
nano $HOME/.bashrc2. 在文件末尾,添加以下行。
export HADOOP_HOME=/usr/local/hadoop
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-i386
#Some convenient aliases
unalias fs &> /dev/null
alias fs="hadoop fs"
unalias hls &> /dev/null
alias hls="fs -ls"
export PATH=$PATH:$HADOOP_HOME/bin方便别名的块是可选的,可以省略。 JAVA_HOME,HADOOP_HOME和PATH是唯一的强制要求。

3.3配置Hadoop
在这一步中,我们将配置Hadoop。
1.在/ usr / local / hadoop / etc / hadoop中打开hadoop-env.sh并设置JAVA_HOME变量,如下所示:
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-i386并使用ctrl + X然后单击“是”保存文件。
注意:到java的路径应该是java在系统中存在的路径。默认情况下,它应该在/ usr / lib文件夹中,但确保它是根据您的系统的正确路径。 此外,确保您要使用的java版本是正确的。下面的截图显示了需要在hadoop-env.sh中修改它的位置。

2.接下来,我们将在/ usr / local / hadoop / etc / hadoop /文件夹中配置core-site.xml,并添加以下属性
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:54310</value>
</property>
</configuration>这将告诉系统系统上应运行默认文件系统的位置。

3.接下来,我们需要更新hdfs-site.xml。此文件用于指定将用作namenode和datanode的目录。
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hdfs/datanode</value>
</property>
</configuration> 
4.现在,我们将更新mapred-site.xml文件。文件夹/ usr / local / hadoop / etc / hadoop /包含文件mapred-site.xml.template。在修改之前将此文件重命名为mapred-site.xml。
<configuration>
<property>
<name>mapreduce.jobtracker.address</name>
<value>localhost:54311</value>
</property>
</configuration>
3.4格式化Hadoop文件系统
我们现在完成所有的配置,所以在启动集群之前,我们需要格式化namenode。为此,请在终端上使用以下命令。
hdfs namenode -format此命令应该在控制台输出上没有任何错误的情况下执行。 如果它没有任何错误地执行,我们很好在我们的Ubuntu系统上启动Apache Hadoop实例。
3.5启动Apache Hadoop
现在是开始Hadoop的时候了。以下是这样做的命令:
/usr/local/hadoop/sbin/start-dfs.sh
一旦dfs启动没有任何错误,我们可以使用命令jps检查一切是否正常工作
cd /usr/local/hadoop/sbin
#Checking the status of the Hadoop components
jps此命令显示正确运行的Hadoop的所有组件,我们应该看到至少一个Namenode和Datanode,如下面的屏幕截图所示。

其他选项是使用http:// localhost:50070上的Namenode的Web界面检查Apache Hadoop的状态。

以下截图显示了Web界面中的Namenode的详细信息

并且以下屏幕截图显示了Hadoop Web界面中的Datanode详细信息

3.6.测试MapReduce作业
1.首先,让我们做出所需的HDFS目录并复制一些输入数据用于测试目的
#Make the required directories in HDFS
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/hduser这些目录也可以从Web界面访问。 为此,请转到Web界面,从菜单中选择“实用程序”,然后从下拉列表中选择“浏览文件系统”

2.现在,我们可以添加一些虚拟文件到我们将用于测试目的的目录。让我们从etc / hadoop文件夹传递所有文件。
#Copy the input files into the distributed file system
/usr/local/hadoop/bin/hdfs dfs -put /usr/local/hadoop/etc/hadoop input下面的屏幕截图显示了添加到Web界面中的/ user / hduser /输入的文件

3.使用以下命令运行Hadoop软件包中包含的MapReduce示例作业:
/usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-example-2.7.1.jar grep input output 'dfs[a-z.]+'注意:有关MapReduce示例如何工作的详细信息,请参阅文章“Hadoop Hello World示例”
下面的截图显示了测试示例的输出日志:

4.我们现在可以使用命令查看输出文件
/usr/local/hadoop/bin/hdfs dfs -cat output/*或使用网络界面也如下面的截图所示:

3.7停止Apache Hadoop
现在我们可以使用以下命令停止dfs(分布式格式系统):
/usr/local/hadoop/sbin/stop-dfs.sh
4.总结
这使我们结束了这个例子。到目前为止,我们已经在我们的Ubuntu系统上安装了Apache Hadoop,我们知道如何向Hadoop添加数据以及如何在添加的数据上执行作业。在这之后,你可以玩Hadoop。 您还可以按照示例来了解一些常见的Hadoop文件系统命令。















 3465
3465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









