







题目一
认识hash函数与hash表
*hash函数* (相同输入相同输出,不同输入均匀分布)
如何用一个哈希函数做出1000个哈希函数来
将一个hash函数返回结果的前八位与后八位拆分为两个hash函数
然后通过h1+1h2做出第三个,h1+2h2做出第四个一次改变系数直到第一千个
hash表经典结构
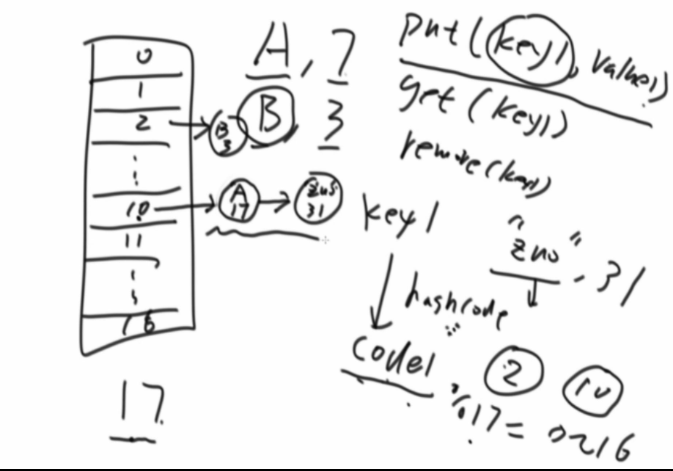
假如放入A,7,将key值A通过hashcode计算出一个码,然后取模hash表长度,得到具体位置,这里假设为10,所以A,7挂载到10位置,如果此时再来一个C,5,取得的位置也是10,那么会先判断key值是否相同,相同就更新value,不同就挂载到A,7后面,使用的是内部实现的node,相当于链表
hash表的增删改查是O(1),离线扩容
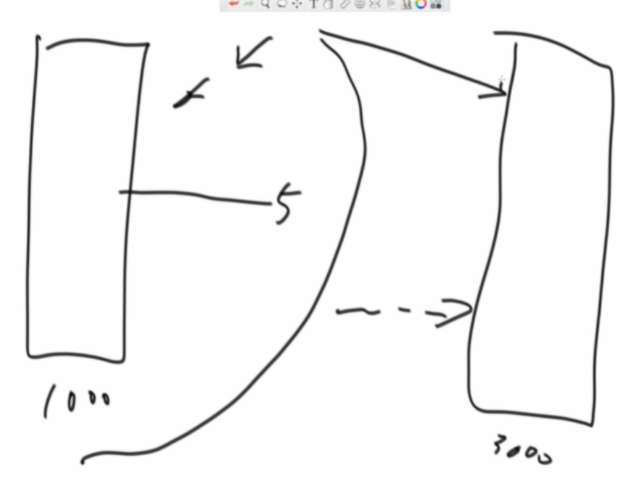
java中jvm的hash表是O(logn),jvm的hash表的桶很少扩容,每个桶有一颗红黑树(平衡搜索二叉树),TreeMap结构
所谓开放地址法,就是我每个桶放的是数组,数组某个位置被占用后,我就依次往下移,用完后整个扩容,其实这种结构还是链表的经典hash表结构
题目二

delete操作时让最后一个数填充删除的数位置
/**
* @author :LY
* @date :Created in 2021/4/16 8:30
* @modified By:
*/
public class RandomPoolTest {
public static class RandomPool{
public HashMap<String,Integer> map1 = new HashMap<>();
public HashMap<Integer,String> map2 = new HashMap<>();
public int size;
public RandomPool(){
map1 = new HashMap<>();
map2 = new HashMap<>();
size = 0;
}
public void add(String str){
if (!map1.containsKey(str)){
map1.put(str,size);
map2.put(size,str);
size++;
}
}
public String getRandom(){
if (size == 0){
return null;
}
int index = (int)Math.random() * size;
return map2.get(index);
}
public void delete(String str){
if (!map1.containsKey(str)){
Integer integer = map1.get(str);
String lastKey = map2.get(--size);
map1.put(lastKey,integer);
map2.put(integer,lastKey);
map1.remove(lastKey);
map2.remove(size);
}
}
}
}
题目三
认识布隆过滤器
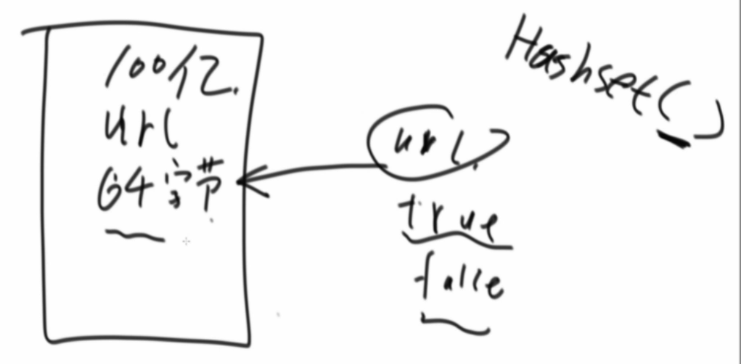
100亿url黑名单,查找后面进来的url是否存在于黑名单中,存在返回true,否则返回false
用hash表需要至少6400亿字节(640g) ,所以不现实
布隆过滤器:有失误率,但是只会误报不会漏报,是一个bit类型的数组
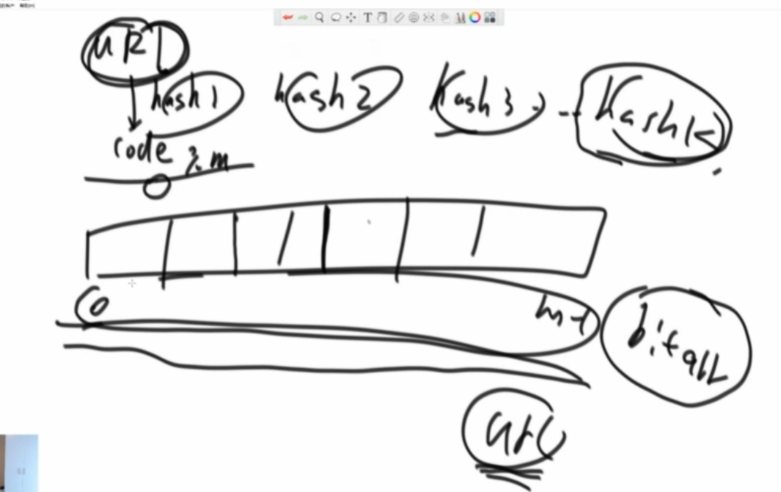
准备k个hash函数,url经过k个hash函数算出来的位置都描黑,这个url就进到布隆过滤器了,将100亿个url都这么操作一遍,所以bit数组需要准备到大一些,
如何查:url经过k个hash函数算出k个位置,如果这些位置都是黑的,那么url就在黑名单中,有一个不是黑的就不在黑名单中
极端情况下,数组太小,那么可能都被描黑,所有url计算的位置都将是黑的,所以会产生误报
计算bit数组大小的公式:n(样本量),p(失误率)
手动推一个,样本量100亿,失误率万分之一
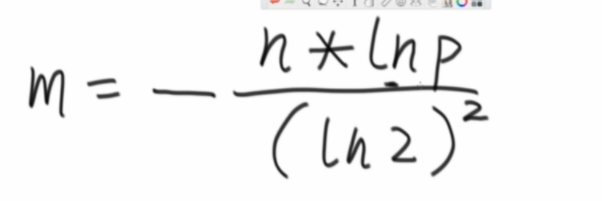
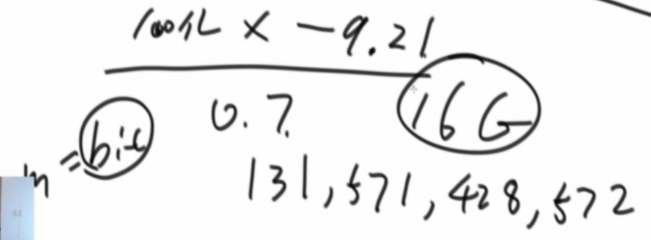
计算hash函数个数个数
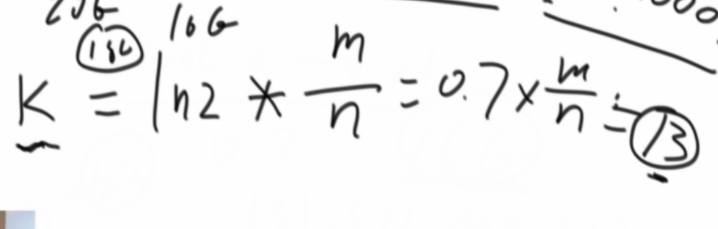
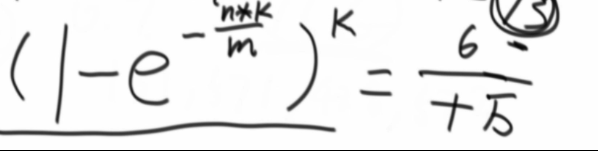
真实失误率公式
题目五
认识一致性哈希
解决了普通的hash函数负载均衡的机器增加减少问题
hash一致性,将我们所有后台机器的IP算出hashcode按照大小排序为一个数组,放到每一台前端服务器中,当请求过来时,算出hashcode,使用二分查找,找到第一个>=请求hashcode的机器
添加机器的过程
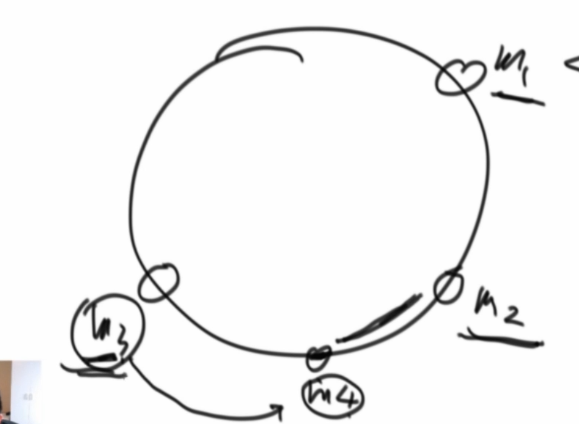 添加一台m4机器,如果算出的hashcode区间在m2-m3之间,那么只需要从m3中迁移m2到m4这段位置的数据到m4服务器就完成
添加一台m4机器,如果算出的hashcode区间在m2-m3之间,那么只需要从m3中迁移m2到m4这段位置的数据到m4服务器就完成
这个结构的缺点是负载不均匀,优化
假如我们有三台机器,给他们设置三张路由表,每张路由表设置1000个虚拟节点,3000个节点设置在环上,此时会非常均匀
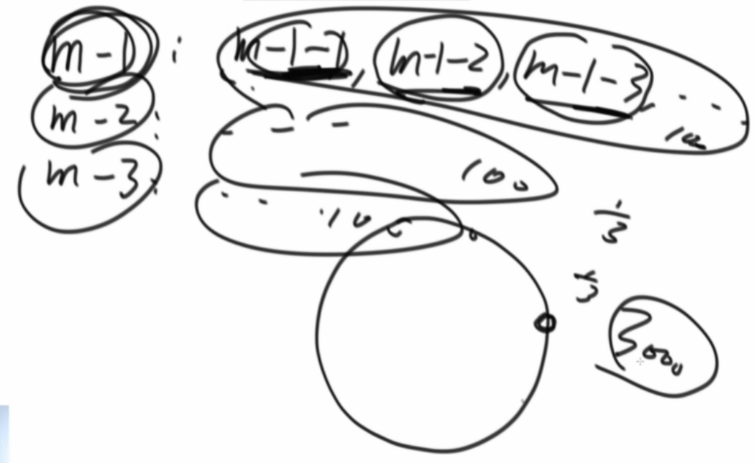
题目六
认识并查集结构
功能:
- 非常快的查找两个元素是否属于一个集合
- 两个元素所在的集合合并在一起
使用并查集必须先把所有数据样本传进来,不支持流
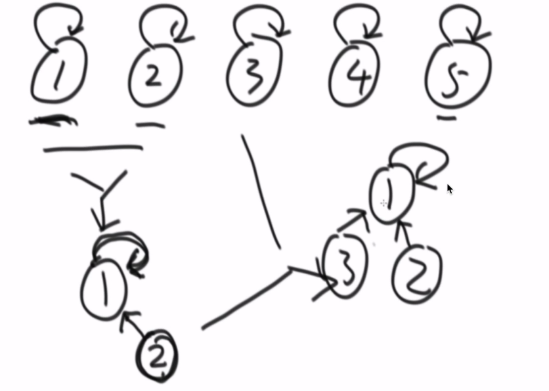
头节点的parent指向自己
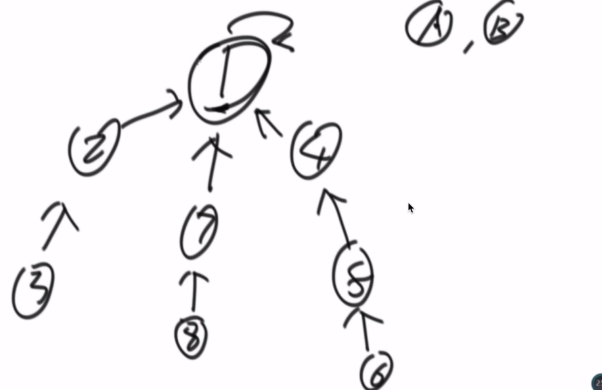
完成功能1,只需要找到头节点,然后看看是否一致,如果一致就是同一个集合
完成功能2,将节点少的集合直接挂到另一个集合即可
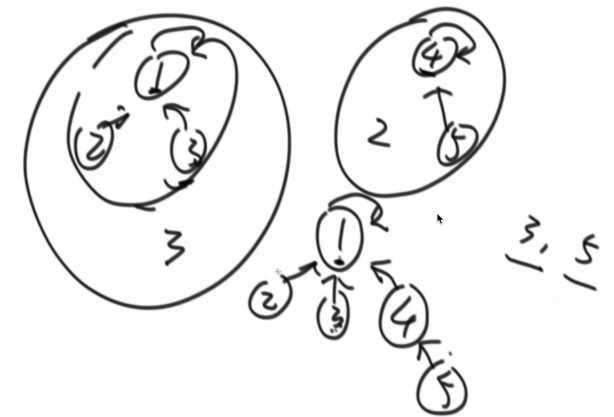
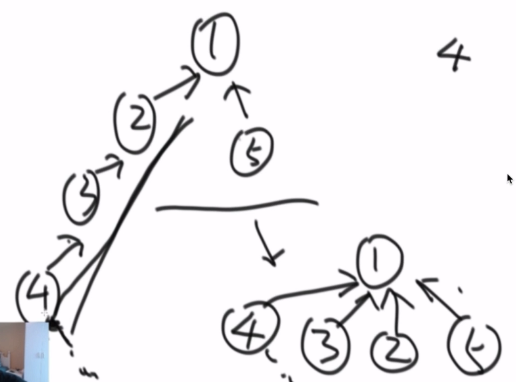
结构优化,在找一个元素的代表节点时,查找完成后将所有节点直接连到代表节点
/**
* @author :LY
* @date :Created in 2021/4/23 8:44
* @modified By:
*/
public class 并查集结构 {
private Map<String,String> fatherMap;//key child value:father
private HashMap<String,Integer> sizeMap;
public 并查集结构(List<String> nodes){
makeSets(nodes);
}
private void makeSets(List<String> nodes){
fatherMap = new Hashtable<>();
sizeMap = new HashMap<>();
for (String node : nodes) {
fatherMap.put(node,node);
sizeMap.put(node,1);
}
}
/**
* 递归方法
* @param node
* @return
*/
private String findHead(String node){
String parent = fatherMap.get(node);
if (node != parent){
parent = findHead(parent);
}
fatherMap.put(null,null);
return parent;
}
/**
* 迭代方法
* @param node
* @return
*/
private String findHead2(String node){
Stack<String> stack = new Stack<>();
String cur = node;
String parent = fatherMap.get(cur);
while (cur != parent){
stack.push(cur);
cur = parent;
parent = fatherMap.get(cur);
}
while (!stack.isEmpty()){
fatherMap.put(stack.pop(),parent);
}
return parent;
}
/**
* 比较两个值是否属于同一节点
* @param a
* @param b
* @return
*/
public boolean isSameSet(String a, String b){
return findHead(a) == findHead(b);
}
/**
* 合并两个节点所属的列表
* @param a
* @param b
*/
public void union(String a, String b){
if (a == null || b == null){
return;
}
String aHead = findHead(a);
String bHead =findHead(b);
if (aHead != bHead){
int aSetSize = sizeMap.get(aHead);
int bSetSize = sizeMap.get(bHead);
if (aSetSize <= bSetSize){
fatherMap.put(aHead,bHead);
sizeMap.put(bHead,aSetSize+bSetSize);
}else {
fatherMap.put(bHead,aHead);
sizeMap.put(aHead,aSetSize +bSetSize);
}
}
}
}















 1104
1104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









