






架构就不细讲,网上一大堆都大同小异,但是自己在部署的过程中发现踩了很多坑,记录一下整个部署过程,开干!
一、部署K8S集群资源数据采集组件:kube-state-metrics
yaml文件一共有5个:

1、cluster-role-binding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.3.0
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system2、cluster-role.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.3.0
name: kube-state-metrics
rules:
- apiGroups:
- ""
resources:
- configmaps
- secrets
- nodes
- pods
- services
- resourcequotas
- replicationcontrollers
- limitranges
- persistentvolumeclaims
- persistentvolumes
- namespaces
- endpoints
verbs:
- list
- watch
- apiGroups:
- apps
resources:
- statefulsets
- daemonsets
- deployments
- replicasets
verbs:
- list
- watch
- apiGroups:
- batch
resources:
- cronjobs
- jobs
verbs:
- list
- watch
- apiGroups:
- autoscaling
resources:
- horizontalpodautoscalers
verbs:
- list
- watch
- apiGroups:
- authentication.k8s.io
resources:
- tokenreviews
verbs:
- create
- apiGroups:
- authorization.k8s.io
resources:
- subjectaccessreviews
verbs:
- create
- apiGroups:
- policy
resources:
- poddisruptionbudgets
verbs:
- list
- watch
- apiGroups:
- certificates.k8s.io
resources:
- certificatesigningrequests
verbs:
- list
- watch
- apiGroups:
- storage.k8s.io
resources:
- storageclasses
- volumeattachments
verbs:
- list
- watch
- apiGroups:
- admissionregistration.k8s.io
resources:
- mutatingwebhookconfigurations
- validatingwebhookconfigurations
verbs:
- list
- watch
- apiGroups:
- networking.k8s.io
resources:
- networkpolicies
- ingresses
verbs:
- list
- watch
- apiGroups:
- coordination.k8s.io
resources:
- leases
verbs:
- list
- watch3、deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.3.0
name: kube-state-metrics
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: kube-state-metrics
template:
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.3.0
spec:
automountServiceAccountToken: true
imagePullSecrets:
- name: image-pull-secret
containers:
- image: # 我自己的私有镜像仓库/kube-state-metrics:v2.3.0,改镜像然后pull,往下看
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 5
name: kube-state-metrics
ports:
- containerPort: 8080
name: http-metrics
- containerPort: 8081
name: telemetry
readinessProbe:
httpGet:
path: /
port: 8081
initialDelaySeconds: 5
timeoutSeconds: 5
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsUser: 65534
nodeSelector:
kubernetes.io/os: linux
serviceAccountName: kube-state-metrics4、service-account.yaml
apiVersion: v1
automountServiceAccountToken: false
kind: ServiceAccount
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.3.0
name: kube-state-metrics
namespace: kube-system5、service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.3.0
name: kube-state-metrics
namespace: kube-system
spec:
clusterIP: None
ports:
- name: http-metrics
port: 8080
targetPort: http-metrics
- name: telemetry
port: 8081
targetPort: telemetry
selector:
app.kubernetes.io/name: kube-state-metrics6、以上文件准备好了,就可以执行deploy了
需要注意的是镜像k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.3.0
这个国内无法下载,需要通过国内源下载,然后tag打包push到自己的私有仓库
docker pull registry.aliyuncs.com/google_containers/kube-apiserver:v1.28.0
docker tag 更换仓库地址
docker push 镜像kubectl apply -f cluster-role-binding.yaml
kubectl apply -f cluster-role.yaml
kubectl apply -f deployment.yaml
kubectl apply -f service-account.yaml
kubectl apply -f service.yaml
二、部署k8s集群节点监控
1、下载
Releases · prometheus/node_exporter · GitHub下载安装包
我这里使用旧版本:node_exporter-0.18.1.linux-amd64.tar.gz
2、安装
将安装包上传到k8s集群节点的/tmp目录,创建一下shell脚本并执行即可完成安装
install_node_exporter.sh
#!/bin/bash
mkdir -p /usr/local/software/node-exporter
# Step 1: Download Node Exporter
mv /tmp/node_exporter-0.18.1.linux-amd64.tar.gz /usr/local/software/node-exporter
# Step 2: Extract Node Exporter
cd /usr/local/software/node-exporter/
tar xvfz node_exporter-0.18.1.linux-amd64.tar.gz
# Step 3: Change to Node Exporter directory
cd node_exporter-0.18.1.linux-amd64
# Step 4: Copy Node Exporter binary to /usr/local/bin
sudo cp node_exporter /usr/local/bin/
# Step 5: Create systemd service unit file
sudo tee /etc/systemd/system/node_exporter.service > /dev/null <<EOT
[Unit]
Description=Node Exporter
After=network.target
[Service]
ExecStart=/usr/local/bin/node_exporter
[Install]
WantedBy=default.target
EOT
# Step 6: Enable and start Node Exporter service
sudo systemctl enable node_exporter
sudo systemctl start node_exporter
# Step 7: Check Node Exporter status
sudo systemctl status node_exporter三、部署prmoetheus
yaml文件7份、配置文件1份、告警规则文件1份

1、clusterRole.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups:
- extensions
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: default
namespace: monitoring2、prometheus--acme-tls.yml
apiVersion: v1
kind: Secret
metadata:
name: prometheus--acme-tls
namespace: monitoring
type: kubernetes.io/tls
data:
ca.crt: ""
tls.crt: #域名证书SSL的crt 方法是: cat 证书.crt | base64
tls.key: #域名证书SSL的key 方法是: cat 证书.key | base643、prometheus-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-deployment
namespace: monitoring
labels:
app: prometheus-server
spec:
replicas: 1
selector:
matchLabels:
app: prometheus-server
template:
metadata:
labels:
app: prometheus-server
spec:
containers:
- name: prometheus
image: prom/prometheus
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus/"
- --storage.tsdb.retention=60d
- --web.enable-lifecycle
- --web.enable-admin-api
ports:
- containerPort: 9090
volumeMounts:
- mountPath: /etc/prometheus
name: prometheus-storage-volume
subPath: prometheus/conf
- mountPath: /prometheus
name: prometheus-storage-volume
subPath: prometheus/data
volumes:
- name: prometheus-storage-volume
persistentVolumeClaim:
claimName: pvc-nas-prometheus
4、prometheus-ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: prometheus-service
namespace: monitoring
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/ssl-redirect: "true"
nginx.ingress.kubernetes.io/rewrite-target: /
nginx.ingress.kubernetes.io/whitelist-source-range: "#需要加白名单的ip,无加白无法访问"
spec:
tls:
- hosts:
# 自定义域名,访问prometheus用到
- prometheus.xxx.xxx.com
secretName: prometheus--acme-tls
rules:
- host: prometheus.xxx.xxx.com
http:
paths:
- path: /
backend:
serviceName: prometheus-service
servicePort: 80805、prometheus-service.yaml
apiVersion: v1
kind: Service
metadata:
name: prometheus-service
namespace: monitoring
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '9090'
spec:
selector:
app: prometheus-server
ports:
- port: 8080
targetPort: 9090
6、10-pv.yml (这里使用的阿里云的Nas,可以根据实际情况创建pv与pvc)
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-nas-prometheus
labels:
alicloud-pvname: pv-nas-prometheus
spec:
capacity:
storage: 100Gi
accessModes:
- ReadWriteMany
csi:
driver: nasplugin.csi.alibabacloud.com
volumeHandle: pv-nas-prometheus
volumeAttributes:
server: "xxxxxxxx.cn-shenzhen.nas.aliyuncs.com"
path: "/prometheus"
mountOptions:
- nolock,tcp,noresvport
- vers=37、20-pvc.yml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pvc-nas-prometheus
namespace: monitoring
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Gi
selector:
matchLabels:
alicloud-pvname: pv-nas-prometheus8、prometheus.rules(该文件放在创建的pv目录内,我这里是放在阿里云nas的/prometheus/prometheus/conf/)
## CPU告警规则
groups:
- name: CpuAlertRule
rules:
- alert: PodCPU告警
expr: (sum(rate(container_cpu_usage_seconds_total{image!="",pod!=""}[1m])) by (namespace, pod)) / (sum(container_spec_cpu_quota{image!="", pod!=""}) by(namespace, pod) / 100000) * 100 > 80
for: 2m
labels:
severity: warning
annotations:
description: "CPU使用率大于80%"
value: "{{$value}}%"
#summary: 'CPU使用率大于80%,当前值为{{.Value}}%,CPU使用率: {{ printf `ceil(100 - ((avg by (instance)(irate(node_cpu_seconds_total{mode="idle",instance="%s"}[1m]))) *100))` $labels.instance | query | first | value }}%'
- alert: NodeCPU告警
expr: round(100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m]))by(kubernetes_node)*100) > 80
for: 2m
labels:
severity: warning
annotations:
description: "CPU使用率大于80%"
value: "{{$value}}%"
#summary: 'CPU使用率大于80%,当前值为{{.Value}}%,CPU使用率: {{ printf `ceil(100 - ((avg by (instance)(irate(node_cpu_seconds_total{mode="idle",instance="%s"}[1m]))) *100))` $labels.instance | query | first | value }}%'
## DISK告警规则
- name: DiskAlertRule
rules:
- alert: Node磁盘告警
expr: round((1- node_filesystem_avail_bytes{fstype=~"ext.+|nfs.+",mountpoint!~".*docker.*"}/node_filesystem_size_bytes{fstype=~"ext.+|nfs.+",mountpoint!~".*docker.*"})*100) > 85
for: 1m
labels:
severity: warning
annotations:
description: "磁盘使用率大于85%"
value: "{{$value}}%"
## MEM告警规则
- name: MemAlertRule
rules:
- alert: Pod内存告警
expr: sum(container_memory_working_set_bytes{image!=""}) by(namespace, pod) / sum(container_spec_memory_limit_bytes{image!=""}) by(namespace, pod) * 100 != +inf > 85
for: 2m
labels:
severity: warning
annotations:
description: "内存使用率大于85%"
value: "{{$value}}%"
- alert: Node内存告警
expr: round(100-((node_memory_MemAvailable_bytes*100)/node_memory_MemTotal_bytes)) > 80
for: 2m
labels:
severity: warning
annotations:
description: "内存使用率大于85%"
value: "{{$value}}%"
## Pod意外重启
- name: PodRestartAlertRule
rules:
- alert: Pod重启告警
expr: delta(kube_pod_container_status_restarts_total[1m]) > 0
for: 1s
labels:
severity: warning
annotations:
description: "Pod发生意外重启事件"
## JvmCMSOldGC
- name: PodJvmOldGCAlertRule
rules:
- alert: PodJvmCMSOldGC
expr: round((jvm_memory_pool_bytes_used{pool=~".+Old Gen"}/jvm_memory_pool_bytes_max{pool=~".+Old Gen"})*100) > 89
for: 5s
labels:
severity: warning
annotations:
description: "Pod堆内存触发CMSOldGC"
value: "{{$value}}%"
## Pod实例异常
- name: ContainerInstanceAlertRule
rules:
- alert: Pod实例异常
expr: kube_pod_container_status_ready - kube_pod_container_status_running > 0
for: 20s
labels:
severity: warning
annotations:
description: "Container实例异常"
## Pod实例OOM
- name: ContainerOOMAlertRule
rules:
- alert: Pod实例OOM
expr: kube_pod_container_status_terminated_reason{reason="OOMKilled"} > 0
for: 1s
labels:
severity: warning
annotations:
description: "Container实例OOM"
## Pod实例驱逐
- name: ContainerEvictionAlertRule
rules:
- alert: Pod实例驱逐
expr: kube_pod_container_status_terminated_reason{reason="Evicted"} > 0
for: 1s
labels:
severity: warning
annotations:
description: "Container实例驱逐"
## MQ内存告警
- name: MQMemoryAlertRule
rules:
- alert: MQ内存水位线
expr: rabbitmq_node_mem_alarm{job=~".*rabbitmq.*"} == 1
for: 1s
labels:
severity: warning
annotations:
description: "RabbitMQ内存高水位线告警"
summary: RabbitMQ {{`{{ $labels.instance }}`}} High Memory Alarm is going off. Which means the node hit highwater mark and has cut off network connectivity, see RabbitMQ WebUI
- alert: MQ内存使用告警
expr: round(avg(rabbitmq_node_mem_used{job=~".*rabbitmq.*"} / rabbitmq_node_mem_limit{job=~".*rabbitmq.*"})by(node,kubernetes_namespace)*100) > 90
for: 10s
labels:
severity: warning
annotations:
description: "RabbitMQ使用告警"
value: "{{$value}}%"
summary: RabbitMQ {{`{{ $labels.instance }}`}} Memory Usage > 90%
##PodJava进程异常
- name: PodJavaProcessAlertRule
rules:
- alert: PodJava进程异常
expr: sum(up{job="kubernetes-pods-jvm"})by(kubernetes_container_name,kubernetes_pod_name) == 0
for: 10s
labels:
severity: warning
annotations:
description: "PodJava进程异常"
summary: "赶快看看吧,顶不住了"9、prometheus.yml (该文件放在创建的pv目录内,我这里是放在阿里云nas的/prometheus/prometheus/conf/)
global:
scrape_interval: 5s
evaluation_interval: 5s
rule_files:
- /etc/prometheus/prometheus.rules
alerting:
alertmanagers:
- scheme: http
static_configs:
- targets:
- "alertmanager.monitoring.svc.cluster.local:9093"
scrape_configs:
- job_name: 'node-exporter'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_endpoints_name]
regex: 'node-exporter'
action: keep
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-nodes'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'kube-state-metrics'
static_configs:
- targets: ['kube-state-metrics.kube-system.svc.cluster.local:8080']
- job_name: 'kubernetes-cadvisor'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
## 节点监控,根据实际情况编写
- job_name: 'k8s-pro'
static_configs:
- targets: ['节点ip:9100']
labels:
instance: devops.105213.pro
- targets: ['节点ip:9100']
labels:
instance: devops.104245.pro
- targets: ['节点ip:9100']
labels:
instance: devops.104249.pro
- targets: ['节点ip:9100']
labels:
instance: devops.105007.pro
- targets: ['节点ip:9100']
labels:
instance: devops.105008.pro
- targets: ['节点ip:9100']
labels:
instance: devops.104250.pro10、以上yaml文件准备好,即可deploy
创建命名空间:kubectl create namespace monitoring
kubectl deploy -f 10-pv.yml
kubectl deploy -f 20-pvc.yml
放文件到指定路径 prometheus.rules
放文件到指定路径 prometheus.yml
kubectl deploy -f clusterRole.yaml
kubectl deploy -f prometheus-deployment.yaml
kubectl deploy -f prometheus-service.yaml
kubectl deploy -f prometheus--acme-tls.yml
kubectl deploy -f prometheus-ingress
验证:访问 https://prometheus.xxx.xxx.com

四、部署altertmanager + webhook-dingtalk
部署需要准备yaml文件6份、配置文件1份、告警内容模版文件1份
 1、10-pv.yml
1、10-pv.yml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-nas-alertmanager
labels:
alicloud-pvname: pv-nas-alertmanager
spec:
capacity:
storage: 50Gi
accessModes:
- ReadWriteMany
csi:
driver: nasplugin.csi.alibabacloud.com
volumeHandle: pv-nas-alertmanager
volumeAttributes:
#使用了阿里云的nas,以实际为准
server: "xxxx.cn-shenzhen.nas.aliyuncs.com"
path: "/alertmanager"
mountOptions:
- nolock,tcp,noresvport
- vers=32、20-pvc.yml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pvc-nas-alertmanager
namespace: monitoring
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 50Gi
selector:
matchLabels:
alicloud-pvname: pv-nas-alertmanager3、alertmanager--acme-tls.yml
apiVersion: v1
kind: Secret
metadata:
name: alertmanager--acme-tls
namespace: monitoring
type: kubernetes.io/tls
data:
ca.crt: ""
tls.crt: # cat 域名证书ssl的crt文件|base64
tls.key: # cat 域名证书ssl的key文件|base644、alertmanager-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager-deployment
namespace: monitoring
labels:
app: alertmanager-server
spec:
replicas: 1
selector:
matchLabels:
app: alertmanager-server
template:
metadata:
labels:
app: alertmanager-server
spec:
containers:
- name: alertmanager
image: prom/alertmanager:latest
args:
- "--config.file=/etc/alertmanager/config.yml"
- "--storage.path=/alertmanager/data"
- --cluster.advertise-address=0.0.0.0:9093
ports:
- containerPort: 9093
protocol: TCP
volumeMounts:
- mountPath: /etc/alertmanager
name: alertmanager-storage-volume
subPath: conf
- mountPath: /alertmanager/data
name: alertmanager-storage-volume
subPath: data
volumes:
- name: alertmanager-storage-volume
persistentVolumeClaim:
claimName: pvc-nas-alertmanager5、alertmanager-ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: alertmanager-service
namespace: monitoring
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/ssl-redirect: "true"
nginx.ingress.kubernetes.io/rewrite-target: /
nginx.ingress.kubernetes.io/whitelist-source-range: "填写需要加白的ip,无在白名单内无法访问的"
spec:
tls:
- hosts:
- alert.xxx.com
secretName: alertmanager--acme-tls
rules:
- host: alert.xxx.com
http:
paths:
- path: /
backend:
serviceName: alertmanager
servicePort: 90936、alertmanager-service.yaml
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: monitoring
spec:
selector:
app: alertmanager-server
ports:
- name: web
port: 9093
protocol: TCP
targetPort: 90937、config.yml (这里是配置钉钉机器人告警,没有配置邮件,如果需要按实际情况添加)
global:
resolve_timeout: 5m
route:
group_by: ['alertname', 'severity', 'namespace']
group_wait: 10s
group_interval: 10s
repeat_interval: 10s
receiver: 'webhook'
routes:
- receiver: 'webhook'
group_wait: 10s
group_interval: 15s
repeat_interval: 3h
templates:
- /etc/alertmanager/config/template.tmp1
receivers:
- name: 'webhook'
webhook_configs:
- url: 'http://webhook-dingtalk'
send_resolved: true8、template.tmp1 (告警内容模版文件)
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
===异常告警===
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
告警详情: {{ $alert.Annotations.description}}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
{{- if gt (len $alert.Labels.namespace) 0 }}
命名空间: {{ $alert.Labels.namespace }}
{{- end }}
{{- if gt (len $alert.Labels.node) 0 }}
节点信息: {{ $alert.Labels.node }}
{{- end }}
{{- if gt (len $alert.Labels.pod) 0 }}
实例名称: {{ $alert.Labels.pod }}
{{- end }}
===END===
{{- end }}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
===异常恢复===
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
告警详情: {{ $alert.Annotations.description}}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
{{- if gt (len $alert.Labels.namespace) 0 }}
命名空间: {{ $alert.Labels.namespace }}
{{- end }}
{{- if gt (len $alert.Labels.node) 0 }}
节点信息: {{ $alert.Labels.node }}
{{- end }}
{{- if gt (len $alert.Labels.pod) 0 }}
实例名称: {{ $alert.Labels.pod }}
{{- end }}
===END===
{{- end }}
{{- end }}
{{- end }}
{{- end }}显示大致如下:

9、webhook-dingtalk.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: webhook-dingtalk
namespace: monitoring
labels:
app: webhook-dingtalk
spec:
replicas: 1
selector:
matchLabels:
app: webhook-dingtalk
template:
metadata:
labels:
app: webhook-dingtalk
spec:
containers:
- name: webhook-dingtalk
image: yangpeng2468/alertmanager-dingtalk-hook:v1
env:
- name: ROBOT_TOKEN
valueFrom:
secretKeyRef:
name: dingtalk-secret
key: token
ports:
- containerPort: 5000
protocol: TCP
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 500m
memory: 500Mi
---
apiVersion: v1
kind: Service
metadata:
labels:
app: webhook-dingtalk
name: webhook-dingtalk
namespace: monitoring
#需要和alertmanager在同一个namespace
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 5000
selector:
app: webhook-dingtalk
type: ClusterIP10、在钉钉群创建机器人并获取token码
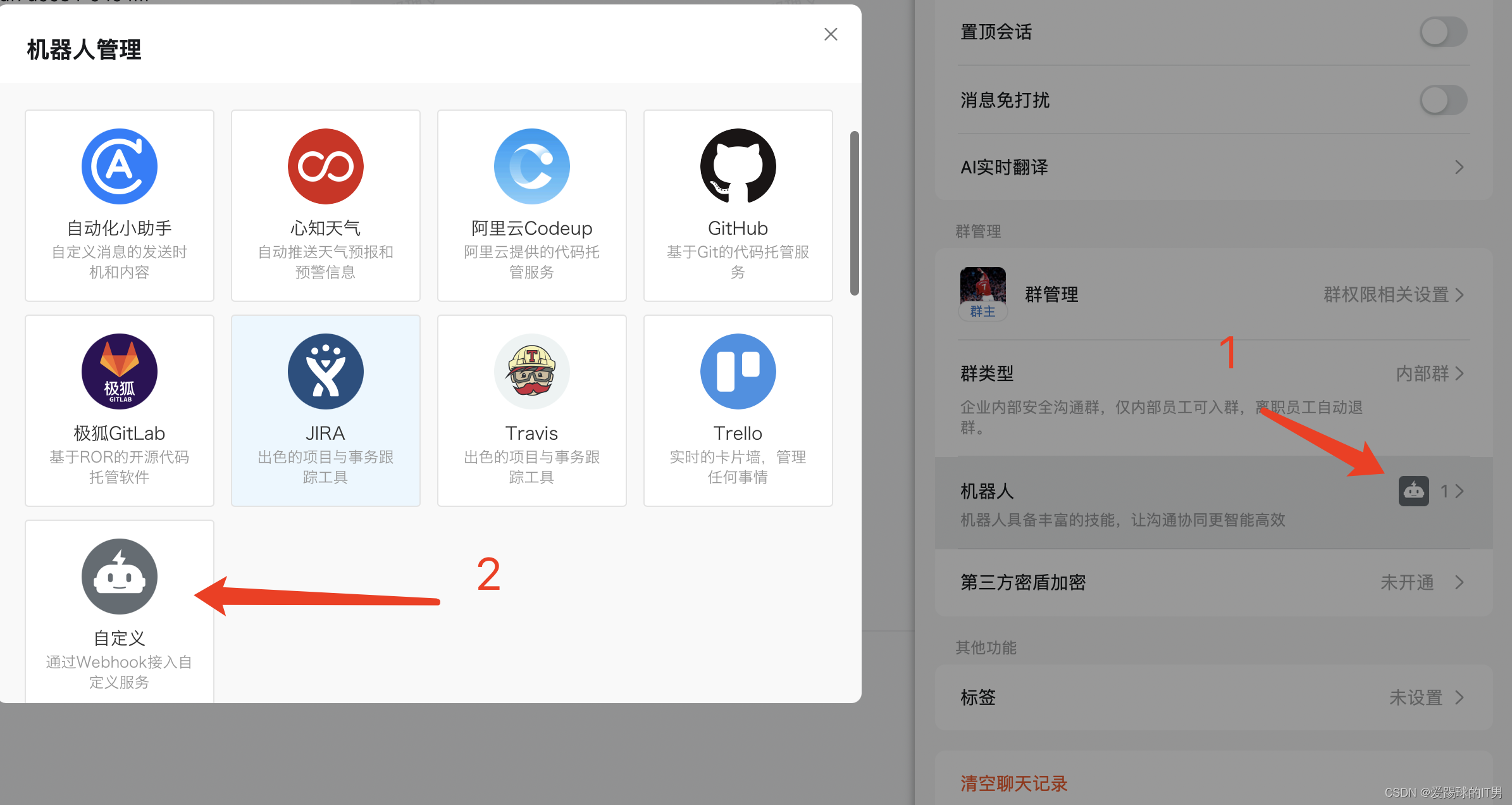
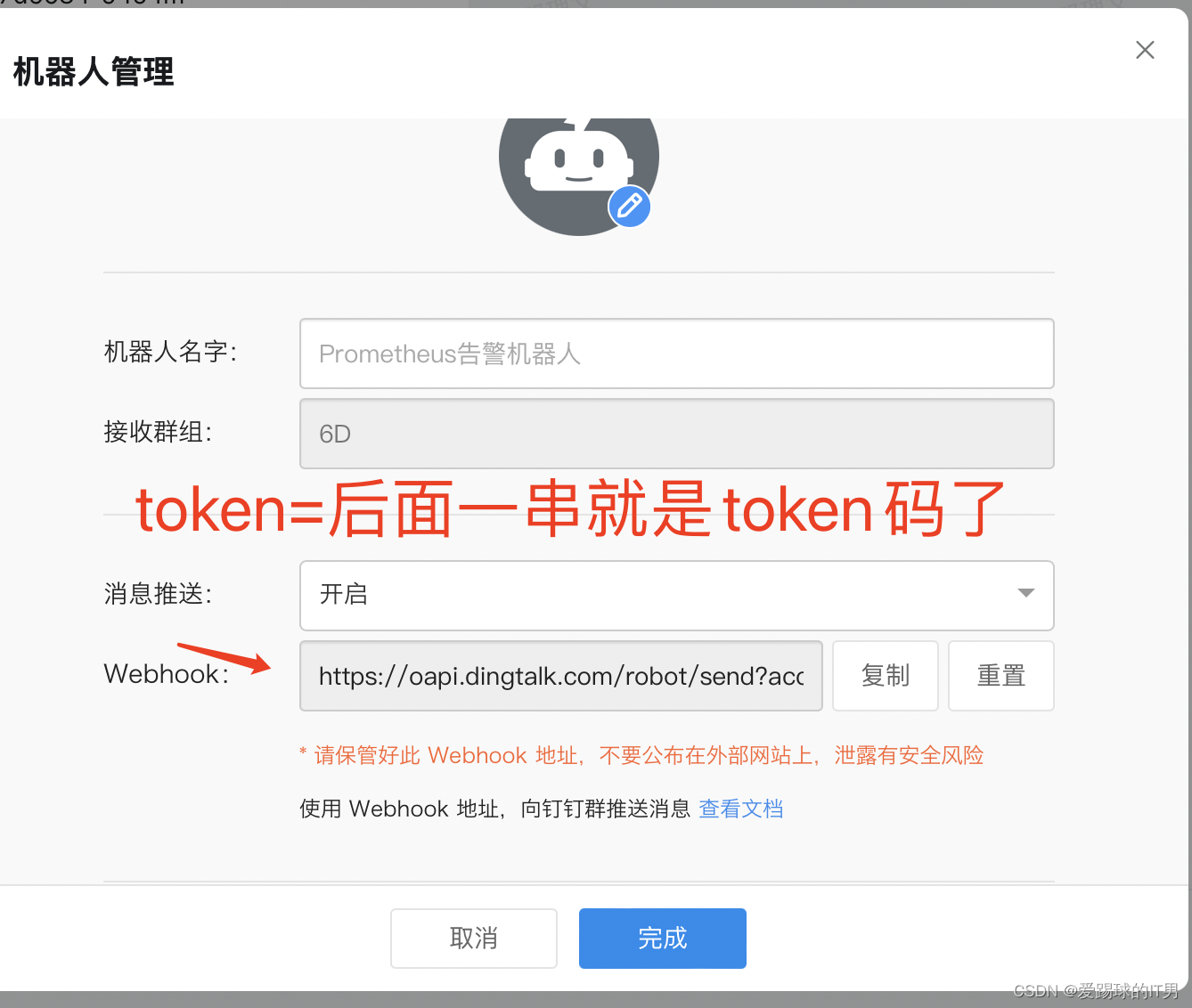
11、以上文件准备好,即可开始deploy
创建钉钉机器人的token文件,xxxxxxxxxx 为钉钉机器人的token:
kubectl create secret generic dingtalk-secret --from-literal=token=xxxxxxxxxx -n monitoring
kubectl deploy -f webhook-dingtalk.yaml
kubectl deploy -f 10-pv.yml
kubectl deploy -f 20-pvc.yml
config.yml 文件放在创建的nas pv路径下的/alertmanager/conf
template.tmp1 文件放在创建的nas pv路径下的/alertmanager/conf/config/
kubectl deploy -f alertmanager-deployment.yaml
kubectl deploy -f alertmanager--acme-tls.yml
kubectl deploy -f alertmanager-service.yaml
kubectl deploy -f alertmanager-ingress.yaml
访问web https://alert.xxx.com 验证
至此,数据采集以及告警都已经部署完成,接下来部署grafana展示数据
五、部署Grafana
由于我实际环境与架构设计的原因,Grafana没有部署在k8s集群中,使用docker部署了,如果需要部署到k8s,可以将docker-compose文件转换成k8s的yaml文件部署即可。
1、docker-comepose.yml
version: "3"
services:
grafana:
image: grafana/grafana:8.1.5
container_name: grafana
restart: always
network_mode: "host"
# ports:
# - 3000:3000
environment:
- GF_SECURITY_ADMIN_USER=admin
- GF_SECURITY_ADMIN_PASSWORD=密码
- GF_AUTH_ANONYMOUS_ENABLED=true
- GF_SECURITY_ALLOW_EMBEDDING=true
volumes:
- /etc/localtime:/etc/localtime:ro
- /data/volumes/monitor/grafana:/var/lib/grafana:z
# 这里可以把grafana的配置文件挂载出来,我本次部署还没对这里动手
# - /data/volumes/monitor/grafana-cfg/grafana.ini:/etc/grafana/grafana.ini:z 访问web http://ip:3000 输入账号密码登录
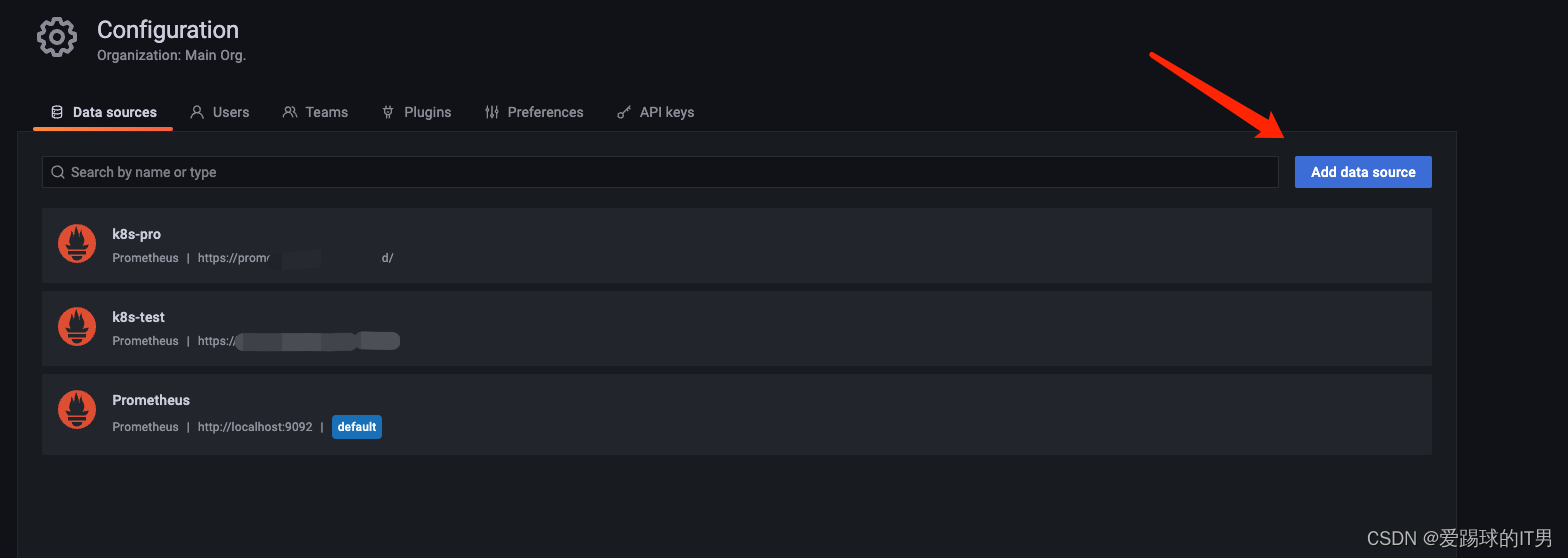
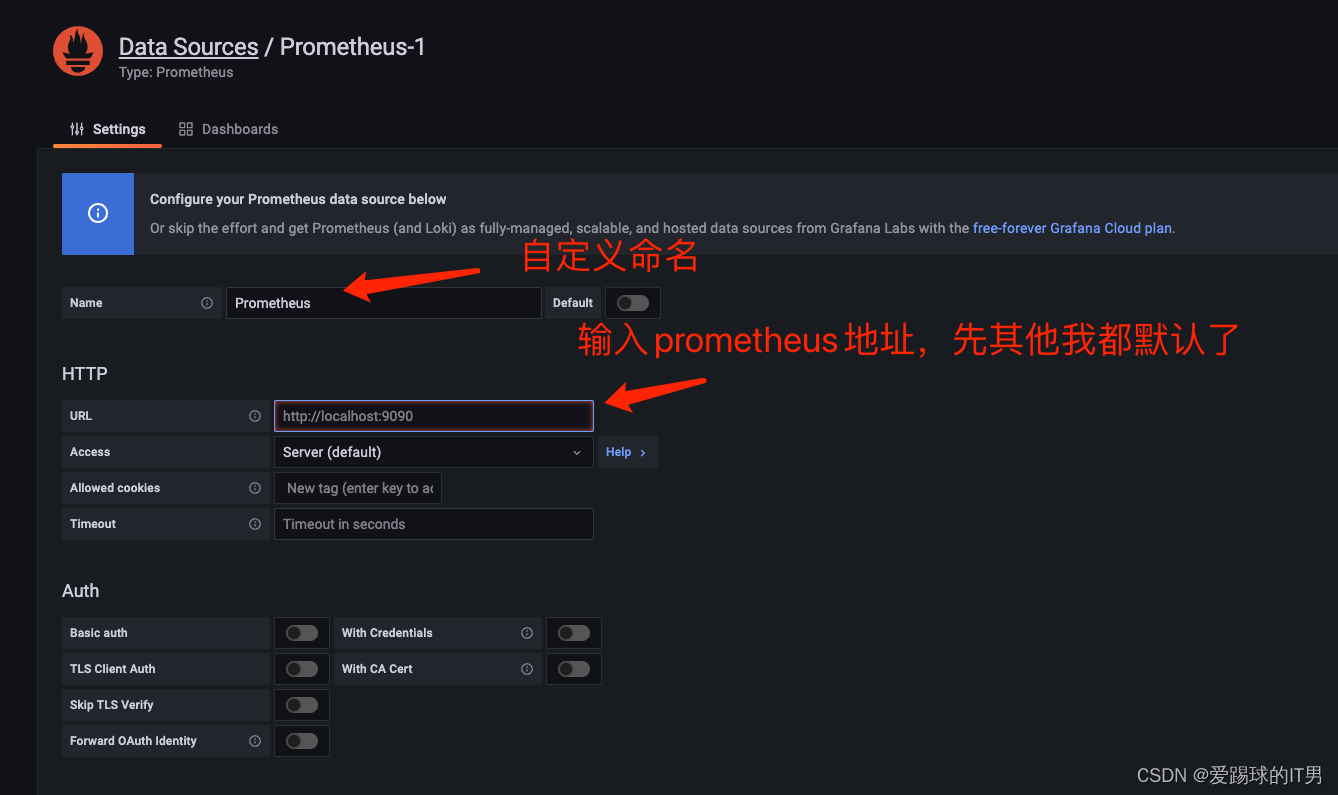
2、添加prometheus数据源地址
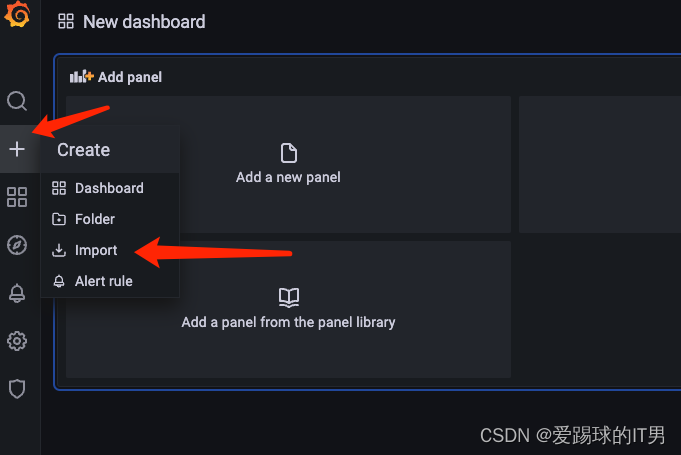
3、导入k8s资源监控grafana模版
这里我是用了模版编号是:13105
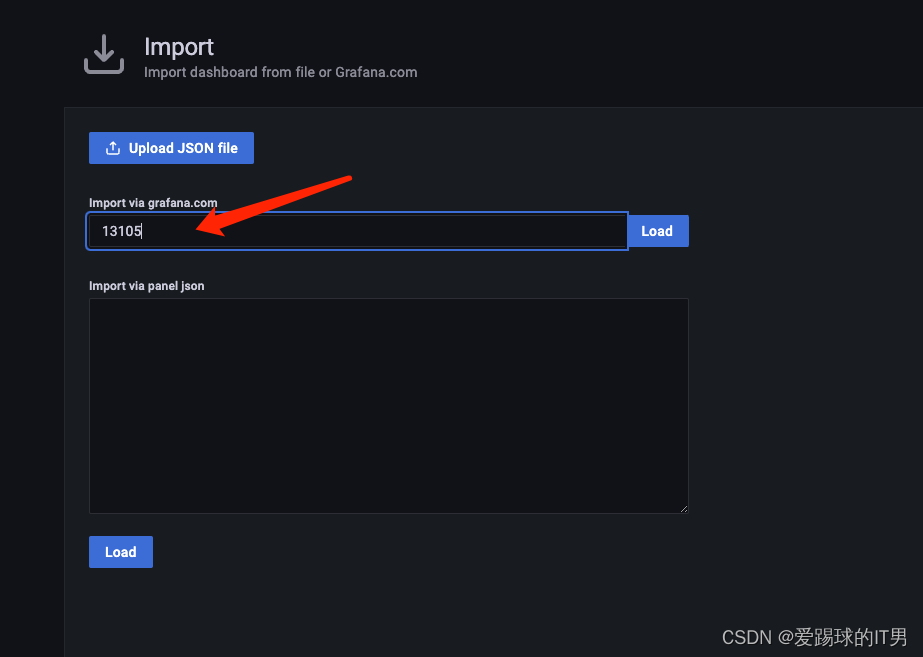
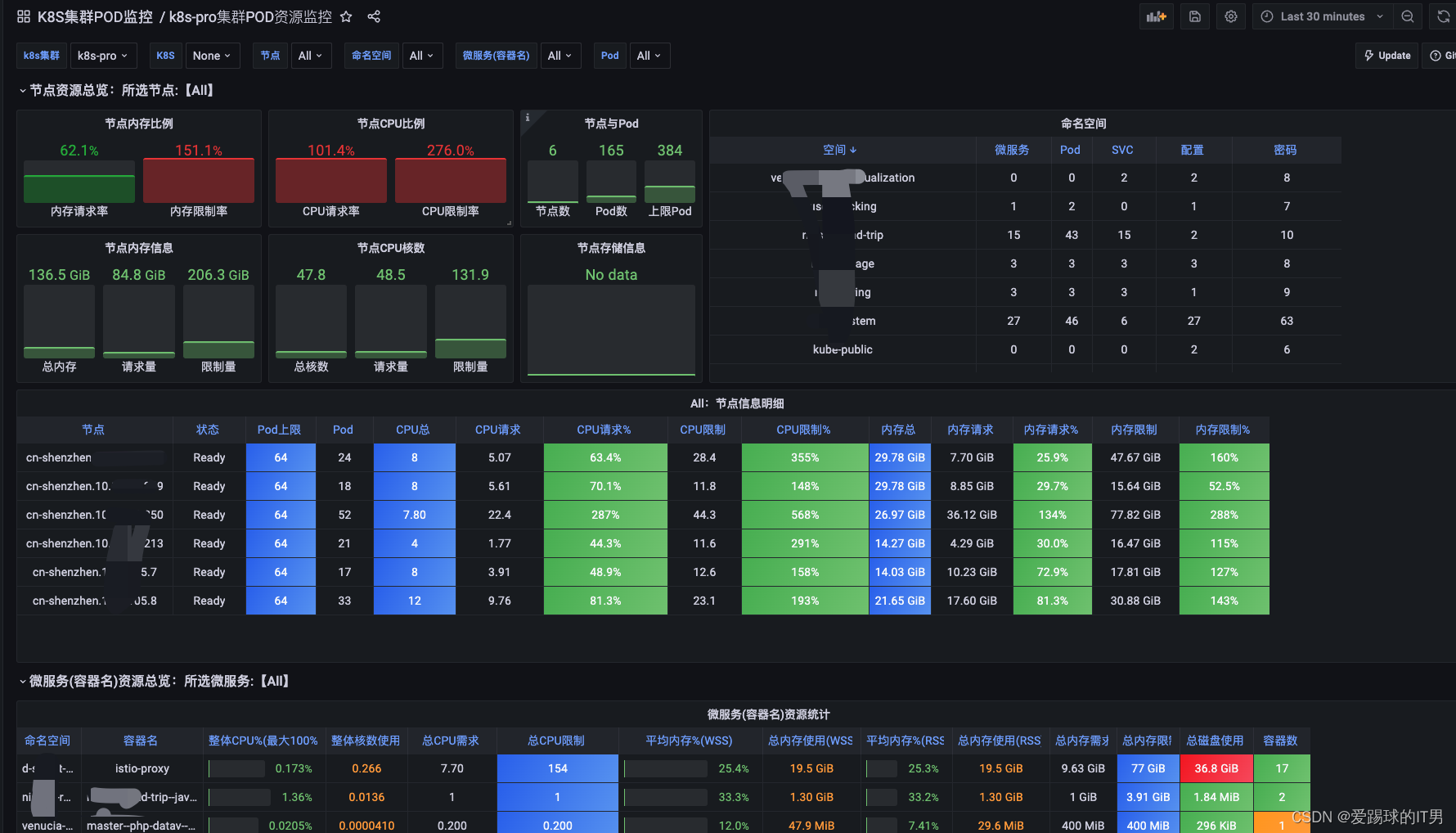
接下来根据实际情况去修改模版里面的prometheus语句等等操作了,这里就不一一介绍了。
具体展示如下
六、踩坑记录
1、部署过程中prometheus告警调用alertmanager的时候报错
报错内容:
http://alertmanager.monitoring.svc.cluster.local:9093/api/v2/alerts count=1 msg="error sending alert" err="bad response status 404 not found"
排查发现原来是alertmanager版本问题,我之前用的是v0.15.1,解决方法更换alertmanager镜像为prom/alertmanager:latest就解决了。
2、部署过程中alertmanager调用webhook-dingtalk报错
报错内容:
error in app: exception on /dingtalk/send/
直接弃用使用的镜像 billy98/webhook-dingtalk:latest和端口8080,解决方法就是更换上述部署yaml文件即可。















 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









