







1、问题描述
1.1 基本信息[Basic Information]
- 集群规模:37+3台物理机,每台128G内存;CPU:2*16C;SATA磁盘,2T*12
- hadoop社区版本:**
- 商业版本:FusionInsight_HD_V100R002C60U10
- MetaStore:高斯数据库(Postgresql)
1.2 问题描述[Problem Description]
- 本问题属于系统bug,社区已经发现,属Linux内核社区相关问题(发行版内核有区别):
- http://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=4f9b16a64753d0bb607454347036dc997fd03b82
- 该问题和硬件强相关,如果非问题中描述的硬件,则不存在该Bug,无需关注。
- 排查方法:运行numactl -–hardware命令,如果节点与节点之间的距离大于20,并且/proc/sys/vm/zone_reclaim_mode文件的内容为1,则可能存在该问题:
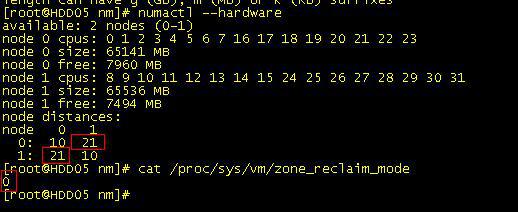
- 受影响的操作系统:RedHat 6.4/6.5、CentOS 6.4/6.5、SuSE11 SP1
- 该问题最初在运行Solr的环境中发现,但是并不代表只有运行Solr的环境才会出现,任何存在内存压力的环境都可能出现。以下以Solr为例阐述该问题。
- Solr在压力测试场景中,集群中的安装了solr的节点经常出现节点故障告警,登录节点故障告警节点,操作系统命令运行非常缓慢
- vmstat 1命令显示当前的cpu的sy占用在50%-60%。
- Solr的性能下降90%。
- 操作系统的性能下降90%,严重时有宕机的风险。
2、问题分析[Problem Analysis]
通过调用栈发现大量的进程在等待spin lock,都是在准备内存回收。由于当前的内存链表可能很长,会导致遍历的非常缓慢。
通过分析发现运行环境打开了zone_reclaim_mode开关,该值为1
zone_reclaim_mode的含义如下:
0:在numa结构的场景下,如果当前node的内存不够,那么从remote node中分配内存。
1:在numa结构的场景下,如果当前node的内存不够,那么进行reclaim尝试回收当前node的内存,并分配。
2:在numa结构的场景下,如果当前node的内存不够,那么进行reclaim尝试回收当前node的内存,如有必要,将脏页回写回收内存,并分配。
4:在numa结构的场景下,如果当前node的内存不够,那么进行reclaim尝试回收当前node的内存,如有必要,将使用swap,并分配。
当内存不足,操作系统根据zone_reclaim_mode进行判断,如果zone_reclaim_mode=0,那么尝试从另外node上面分配内存。
如果zone_reclaim_mode=1,那么会尝试在该node上进行内存回收,再将该node的内存分配给该申请者。
操作系统中的zone_reclaim_mode默认值是0,但是在一些硬件环境中,操作系统在初始化时会偷偷将其修改为1:
其计算node之间的距离,如果node之间的距离大于RECLAIM_DISTANCE,那么就将zone_reclaim_mode设置为1
而RECLAIM_DISTANCE的为20
也就是说,如果node之间的距离大于20,操作系统就自动将zone_reclaim_mode设置为1。
很不幸,我们会碰到这样的硬件环境。
Linux内核社区相关问题(发行版内核有区别):
http://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=4f9b16a64753d0bb607454347036dc997fd03b82
3、根本原因[Root Cause]
3.1 Hive表列属性偶现失败
????本问题主要包括两个方面:
- HiveServer与MetaStore客户端连接超时时间未按照集群规模进行合理配置;
- 对于大数据量频繁读元数据表的情形,缺少针对性优化。
3.2 Hive表列属性更新慢
- 系统建表未建立索引为可优化点,根据内部测试,建立索引后性能有较大幅度的提升。
- 用户之前反应比较快,根据生产环境到测试环境的重建,发现执行修改comment,需要相似的时间,用户反应之前快,可能是上边分析中修改的comment前后一样导致的.
4、解决措施[Corrective Action]
4.1 临时解决措施[Workaround]
- 步骤1. echo "vm.zone_reclaim_mode = 0" >> /etc/sysctl.conf
- 步骤2. sysctl -p
4.2 最终解决措施[Solution]
- RedHat 6.4:升级到RedHat 6.6 kernel-2.6.32-504.el6及以上
- RedHat 6.5:升级到RedHat 6.6 kernel-2.6.32-504.el6及以上
- CentOS 6.4: 升级到CentOS 6.6及以上
- CentOS 6.5: 升级到CentOS 6.6及以上
- SuSE11 SP1:升级到SuSE11 SP2及以上
- 社区将node的RECLAIM_DISTANCE设置为30,并且将zone_reclaim_mode=1的设置完全移除。
- 发行版的内核仅仅是将RECLAIM_DISTANCE的值改为30,所以升级内核的并不是特别可靠。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









