






项目背景
1.由于当时这个是从0-1的新项目,为了开快速开发功能,我们第一版接口,直接从数据库中查询组织数据,组装成组织树,然后返回给前端。
2.通过这种方式,简化了数据流程,快速把整个页面功能调通了。
组织树优化
目前优化方案
1.代码部署IDC环境,刚开始没啥问题;
2.随着4A全量组织数据导入,很快就暴露出性能瓶颈;
3.我们不得不做优化了,我们第一个想到的是代码层面进行优化;
4.代码优化如下图,目前已经符合上线条件。
/**
* 查询组织树
* @param arkSysDept
* @return
*/
@Override
public List<DeptTreeNode> findDeptTreeByDept(ArkSysDept arkSysDept) {
List<DeptTreeNode> treeList = new ArrayList<DeptTreeNode>();
arkSysDept.setDelFlag("0");
Long startTime = System.currentTimeMillis();
List<DeptTree> deptList = new ArrayList<DeptTree>();
if(redisUtils.hasKey(DEPT_TREE_NODE)){
deptList = (List<DeptTree>) redisUtils.get(DEPT_TREE_NODE);
log.info("查询redis总耗时 :" + (System.currentTimeMillis()-startTime));
}else{
deptList = arkSysDeptDao.findDeptTreeByDept(arkSysDept);
log.info("查询数据库总耗时 :" + (System.currentTimeMillis()-startTime));
redisUtils.set(DEPT_TREE_NODE,deptList);
}
Long buildTreeStartTime = System.currentTimeMillis();
treeList = buildTree(deptList);
log.info("封装组织树总耗时 :" + (System.currentTimeMillis()-buildTreeStartTime));
log.info("查询组织树总耗时 :" + (System.currentTimeMillis()-startTime));
return treeList;
}
/**
* 封装组织树结构list
* @param deptList
* @return
*/
private List<DeptTreeNode> buildTree(List<DeptTree> deptList) {
if(null == deptList || deptList.isEmpty()){
return new LinkedList<DeptTreeNode>();
}
// 最终要返回的只保留根节点的集合,增删比较多,使用LinkedList
List<DeptTreeNode> respTreeNodeList = new LinkedList<DeptTreeNode>();
// id集合,后面用来判断parentId是否在deptList存在,如果存在则说明是子节点,不存在则认为是根节点
Set<String> idSet = new HashSet<>(deptList.size());
DeptTreeNode deptTreeNode;
for (DeptTree deptTree : deptList) {
deptTreeNode = new DeptTreeNode();
deptTreeNode.setId(deptTree.getDeptId().toString());
deptTreeNode.setLabel(deptTree.getDeptName());
deptTreeNode.setFreeze("Y");
deptTreeNode.setParentId(deptTree.getParentId().toString());
// 遍历的时候顺便保存id集合
idSet.add(deptTreeNode.getId());
respTreeNodeList.add(deptTreeNode);
}
// 获取由parentId作为key的map,同一个父节点的数据已经被汇总成一个list,通过key就能获取
Map<String, List<DeptTreeNode>> parentIdMap = respTreeNodeList.stream().collect(Collectors.groupingBy(item -> item.getParentId() != null ? item.getParentId() : "nonParent"));
// 设置children,并从根节点移出不是父节点的数据
Iterator<DeptTreeNode> iterator = respTreeNodeList.iterator();
DeptTreeNode node;
while (iterator.hasNext()) {
node = iterator.next();
// 获取当前结点的子节点集合
node.setChildren(parentIdMap.get(node.getId()));
// 如果父id在id集合中存在,则说明他不是根节点,移除
if (idSet.contains(node.getParentId())) {
iterator.remove();
}else{
String pId = node.getParentId();
if(!pId.equals("-1")){
iterator.remove();
}
}
}
return respTreeNodeList;
}
后期优化法案一
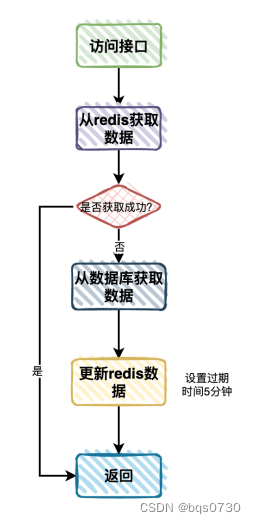
1.组织相关数据实时性要求不是太高;
2.我们第一个想到的是:加Redis缓存;
3.用户访问接口获取组织树时,先从Redis中查询数据;
4.如果Redis中有数据,则直接数据;
5.如果Redis中没有数据,则再从数据库中查询数据,拼接成组织树返回;
6.将从数据库中查到的组织树的数据,保存到Redis中,设置过期时间5分钟;
7.将组织树返回给用户;
8.流程图如下:
后期优化法案二
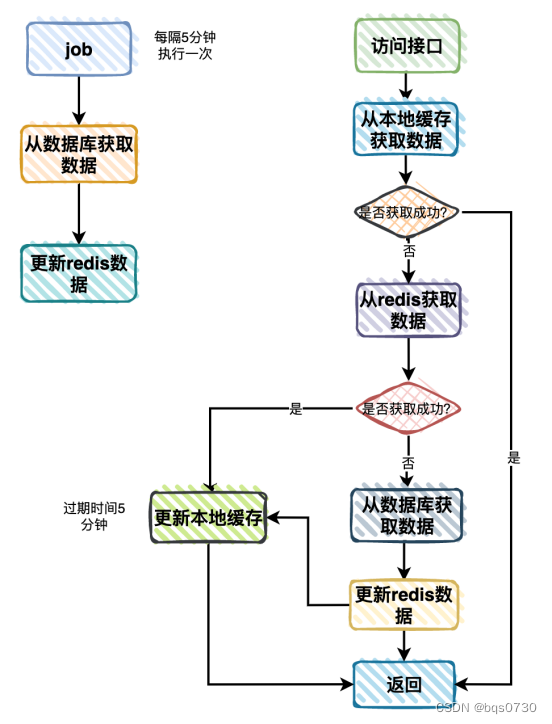
1.随着数据量不断增加,可以添加一层内存缓存;
2.使用Job定期异步更新组织树到Redis中;
3.内存缓存是保存在服务器节点上的,不同的服务器节点更新的频率可能有点差异,这样可能会导致数据的不一致性;
4.但组织本身是更新频率比较低的数据,对于用户来说不太敏感,即使在短时间内,用户看到的组织树有些差异,也不会对用户造成太大的影响;
5.因此,组织树这种业务场景,是可以使用内存缓存的;
6.建议使用了Spring推荐的caffine作为内存缓存;
7.流程图如下:
优化后业务逻辑说明
1.用户访问接口时改成先从本地缓存分类数查询数据;
2.如果本地缓存有,则直接返回;
3.如果本地缓存没有,则从Redis中查询数据;
4.如果Redis中有数据,则将数据更新到本地缓存中,然后返回数据;
5.如果Redis中也没有数据(说明Redis挂了),则从数据库中查询数据,更新到Redis中(万一Redis恢复了呢),然后更新到本地缓存中,返回返回数据;
6.需要注意的是,需要改本地缓存设置一个过期时间,这里设置的5分钟,不然的话,没办法获取新的数据。















 1670
1670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









