







相关博客
【极速前进】20240706-24240714:用于Agent的树搜、理解LLM的语种困惑、事实知识抽取微调、Quiet-STaR
【极速前进】20240615-20240623:Zipper融合模态、VideoLLM视频理解、WebAgent可以自我改善、Nemotron-4、AnyGPT统一模态
【极速前进】20240608-20240610:评估模型Prometheus 2、CoPE、DITTO:使用示例反馈对齐LLM、CoA:利用多Agent解决长文本、Qwen2在线合并优化器
【极速前进】20240524-20240526:Meta多模态模型Chameleon、参数高效微调MoRA、跨层注意力降低KV Cache、Octopus v4、SimPO
【极速前进】20240423-20240428:Phi-3、fDPO、TextSquare多模态合成数据、遵循准则而不是偏好标签、混合LoRA专家
【极速前进】20240422:预训练RHO-1、合成数据CodecLM、网页到HTML数据集、MLLM消融实验MM1、Branch-Train-Mix
【极速前进】20240415-20240421:TR-DPO、压缩与智能的线性关系、模拟伪代码改善算术能力、Many-shot、合成数据综述
一、Chameleon:混合模态早期融合基础模型
论文地址:https://arxiv.org/pdf/2405.09818
Chameleon是一个基于token的早期融合多模态模型,能够理解和生成任意序列的文本或者图像。
1. 预训练
1.1 Tokenization
图像Tokenization。从大小为8192的codebook中奖512*512的图像编码为1024个离散tokens。使用授权图片来训练tokenizer。由于生成人脸的重要性,对人脸图像进行了上采样。该tokenizer的核心弱点是重构具有大量文本的图像,因此遇到需要大量OCR相关的任务会导致模型效果较差。
文本Tokenizer。使用训练数据的子集来训练新的BPE tokenizer,词表大小为65536,其中包含8192个图像codebook tokens,使用sentencepiece库。
1.2 预训练数据
将预训练分为两个阶段,第一个阶段占80%,第二阶段20%。
第一阶段。第一阶段包含大量无监督数据的混合数据集,包括:(1) 大约2.9T tokens的纯文本数据集;(2) 使用大约1.4 B的图文对,其能够产生1.5T的图文tokens;(3) 从互联网收集大约400B tokens的图文交错数据。
第二阶段。降低第一阶段数据的权重为50%并混合高质量数据集,同时维护图像文本token的比例相近。此外,包含了指令调优的部分数据集。
1.3 稳定性
当Chameleon超过8B参数和1T tokens时会遇到稳定性问题,而且不稳定性出现在训练后期。为了解决稳定性问题,采用措施:
架构。模型结构大致类似于LLaMa-2。由于训练中后期输出范数的缓慢增长,LLaMa架构会出现复杂的分歧。最终定位到是由softmax的平移不变性导致的。由于模型权重跨模态共享,每个模态会通过轻微增加范数来与其他模态竞争。虽然训练开始时没有问题,但是随着训练进行超过bf16有效表示范围,就会出现分歧。在单一模态中,该问题称为logit漂移问题。
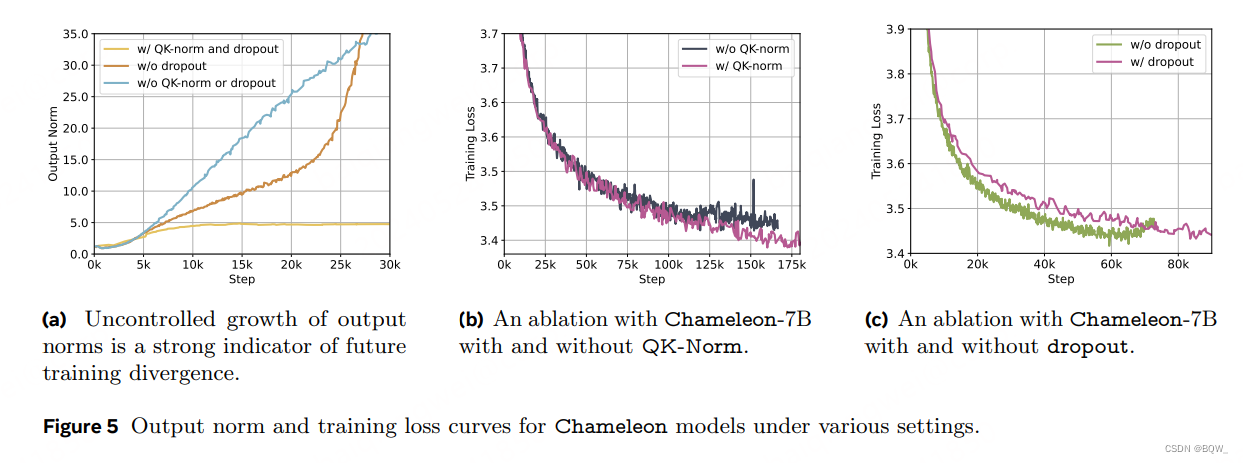
上图5(a)是训练过程中最后Transformer层输出的范数,大约在训练的20%处出现分歧。范数出现不受控增长与loss出现分歧高度相关。在Transformer中Softmax出现在两处:核心注意力机制和logit之后。这里使用QK-Norm来控制softmax输入的范数。此外,除了QK-norm以外,也有必要在注意力和前馈层前引入dropout。但是,该方案对于Chameleon-34B并不足够,其需要额外的范数重排。具体来说,使用Liu et al.的normalization策略。设 h h h表示输入 x x x经过自注意力机制后的隐藏向量,则
Chameleon-34B: h = x + attention_norm ( attention ( x ) ) output = h + ffn_norm ( feed_forward(h) ) Llama2: h = x + attention ( attention_norm ( x ) ) output = h + feed_forward ( ffn_norm ( h ) ) \begin{align} \textbf{Chameleon-34B: }&h=x+\text{attention\_norm}(\text{attention}(x)) \\ &\text{output}=h+\text{ffn\_norm}(\text{feed\_forward(h)}) \\ \textbf{Llama2: }&h=x+\text{attention}(\text{attention\_norm}(x)) \\ &\text{output}=h+\text{feed\_forward}(\text{ffn\_norm}(h)) \\ \end{align} \\ Chameleon-34B: Llama2: h=x+attention_norm(attention(x))output=h+ffn_norm(feed_forward(h))h=x+attention(attention_norm(x))output=h+feed_forward(ffn_norm(h))
此外,发现这种类型的normalization与dropout不能很好的结合,因此训练Chameleon-34B不使用dropout。
优化。应用QK-Norm有助于注意力内的softmax,但对于最后输出层的logit shift问题没有帮助。因此,应用z-loss正则化。具体来说,对softmax的配分函数进行正则化,即对于 σ ( x ) i = e x i Z \sigma(x)_i=\frac{e^{x_i}}{Z} σ(x)i=Zexi中的 Z = ∑ i e x i Z=\sum_i e^{x_i} Z=∑iexi加 1 0 − 5 log 2 Z 10^{-5}\log_2 Z 10−5log2Z。Chameleon-7B使用dropout和z-loss实现稳定性,而Chameleon-34B仅需要z-loss。
2. 对齐
数据。将SFT数据分为以下类别:文本、代码、视觉对话、图像生成、文本/图像交替生成、安全。
微调策略。SFT阶段平衡模态数据比例至关重要。
二、MoRA:用于参数高效微调的高秩更新
论文地址:https://arxiv.org/pdf/2405.12130
LoRA的低秩更新机制可能会限制LLM学习和记忆新知识的能力。本文提出MoRA,能够实现相同可训练参数情况下的高秩更新。
1. 分析低秩更新的影响
给定预训练权重矩阵 W 0 ∈ R d × k W_0\in\mathbb{R}^{d\times k} W0∈Rd×k,LoRA利用两个低秩矩阵来计算权重更新 Δ W \Delta W ΔW:
h = W 0 x + Δ W x = W 0 x + B A x h=W_0x+\Delta Wx=W_0x+BAx \\ h=W0x+ΔWx=W0x+BAx
其中 A ∈ R r × k A\in\mathbb{R}^{r\times k} A∈Rr×k和 B ∈ R d × r B\in\mathbb{R}^{d\times r} B∈Rd×r表示低秩矩阵。为了确保训练开始时 Δ W = 0 \Delta W=0 ΔW=0,LoRA使用高斯分布初始化 A A A并初始化B为0。由于 Δ W \Delta W ΔW被低秩分解为 B A BA BA,则 rank ( Δ W ) ≤ r \text{rank}(\Delta W)\leq r rank(ΔW)≤r。LoRA更新在文本分类或者指令微调上表现出与全秩微调相当的效果,但是在复杂推理或者持续预训上则效果会变差。
基于这些观察,提出假设:低秩更新能够更好利用LLM的原始知识和能力,但是对于需要增强LLM知识和能力的任务来说就很挣扎。经验实验验证,LoRA确实难以学习新知识,即使可以通过增大秩来缓解。
2. MoRA
给定预训练权重 W 0 ∈ R d × k W_0\in\mathbb{R}^{d\times k} W0∈Rd×k,LoRA使用两个低秩矩阵 A A A和 B B B来实现低秩更新,总可训练参数为 ( d + k ) r (d+k)r (d+k)r。在相同可训练参数下,方阵 M ∈ R r ^ × r ^ M\in\mathbb{R}^{\hat{r}\times\hat{r}} M∈Rr^×r^的 r ^ = ⌊ ( d + k ) r ⌋ \hat{r}=\lfloor\sqrt{(d+k)r} \rfloor r^=⌊(d+k)r⌋能够实现最高的秩,因为 r ≪ min ( d , k ) r\ll\min(d,k) r≪min(d,k)。
为了实现该目标,应该缩减 M M M的输入微调并增加输出维度。正式来说,
h = W 0 x + f decomp ( M f comp ( x ) ) h=W_0x+f_{\text{decomp}}(M f_{\text{comp}}(x)) \\ h=W0x+fdecomp(Mfcomp(x))
其中 f comp : R k → R r ^ f_{\text{comp}}:\mathbb{R}^{k}\rightarrow\mathbb{R}^{\hat{r}} fcomp:Rk→Rr^表示将 x x x输入维度从 k k k降低至 r ^ \hat{r} r^的函数, f decomp : R r ^ → R d f_{\text{decomp}}:\mathbb{R}^{\hat{r}}\rightarrow\mathbb{R}^d fdecomp:Rr^→Rd则是将输出维度从 r ^ \hat{r} r^增加到 d d d的函数。此外,这两个函数应该是非参数化的操作且能在线性时间内执行。对于将 M M M转换为 Δ W \Delta W ΔW,对应函数 f comp : R r ^ × r ^ → R r ^ × k f_{\over{\text{comp}}}:\mathbb{R}^{\hat{r}\times\hat{r}}\rightarrow\mathbb{R}^{\hat{r}\times k} fcomp:Rr^×
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











