







相关博客
【极速前进】20240804:Case2Code提升归纳推理能力、归纳推理和演绎推理、LLM Patch-level训练、LLM内部冲突和上下文冲突
【极速前进】20240706-24240714:用于Agent的树搜、理解LLM的语种困惑、事实知识抽取微调、Quiet-STaR
【极速前进】20240615-20240623:Zipper融合模态、VideoLLM视频理解、WebAgent可以自我改善、Nemotron-4、AnyGPT统一模态
【极速前进】20240608-20240610:评估模型Prometheus 2、CoPE、DITTO:使用示例反馈对齐LLM、CoA:利用多Agent解决长文本、Qwen2在线合并优化器
【极速前进】20240524-20240526:Meta多模态模型Chameleon、参数高效微调MoRA、跨层注意力降低KV Cache、Octopus v4、SimPO
【极速前进】20240423-20240428:Phi-3、fDPO、TextSquare多模态合成数据、遵循准则而不是偏好标签、混合LoRA专家
【极速前进】20240422:预训练RHO-1、合成数据CodecLM、网页到HTML数据集、MLLM消融实验MM1、Branch-Train-Mix
【极速前进】20240415-20240421:TR-DPO、压缩与智能的线性关系、模拟伪代码改善算术能力、Many-shot、合成数据综述
一、Case2Code:利用合成数据学习归纳推理
论文名称:Case2Code: Learning Inductive Reasoning with Synthetic Data
论文地址:https://arxiv.org/pdf/2407.12504
1. 简介
- 大多数LLM擅长演绎(deductive)推理,例如CoT等;
- 本文希望探索LLM的归纳推理能力,即LLM通过示例样本来推断潜在的规则;
- 提出Case2Code任务并利用合成数据探索归纳推理能力;
- 实验显示,通过合成的归纳推理代码数据不但能够提高Case2Code任务上的效果,而且也能增强LLM的代码能力;
2. 方法
问题形式化。对于一个程序 P \mathcal{P} P,有 n n n个输入-输出样本构成的集合 S P = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x n , y n ) } \mathcal{S}_{\mathcal{P}}=\{(x_1,y_1),(x_2,y_2),\dots,(x_n,y_n)\} SP={(x1,y1),(x2,y2),…,(xn,yn)},其中 y i = P ( x i ) , i = 1 , 2 , … , n y_i=\mathcal{P}(x_i),i=1,2,\dots,n yi=P(xi),i=1,2,…,n。Case2Code的目标是实现程序 P ′ \mathcal{P}' P′,其能够基于输入-输出样例 S P \mathcal{S}_{\mathcal{P}} SP来捕获程序 P \mathcal{P} P的功能。对于任意新的输入 x new ∉ S P x_{\text{new}}\notin\mathcal{S}_{\mathcal{P}} xnew∈/SP,实现的程序 P ′ \mathcal{P}' P′应该满足 P ( x new ) = P ′ ( x new ) \mathcal{P}(x_{\text{new}})=\mathcal{P}'(x_{\text{new}}) P(xnew)=P′(xnew)。
框架概览。目标是自动化生产大规模且多样的Case2Code数据。先基于规则过滤来收集多样性的程序。利用LLM构造样本输入,并利用代码解释器生成输出。最终,基于输出过滤低质量程序,并转换为三元组(program,inputs,outputs)。
收集程序。从TheStack中采样有效的Python函数。
生成输入。在收集大规模函数后,接下来就是获得对应的输入和输出。利用LLM为每个函数生成合适的输入样例。
获得输出。在获得高质量程序和输入,可以利用代码解释器获得输出。由于LLM生成的输入可能包含错误,利用规则和返回的输出过滤无效的输入和函数。
后处理。最后的步骤是将函数和对应的输入-输出转换为Case2Code风格数据。对于一个给定的函数 P \mathcal{P} P和 n n n个测试用例 S P = { ( x 1 , y 1 ) , … , ( x n , y n ) } \mathcal{S}_{\mathcal{P}}=\{(x_1,y_1),\dots,(x_n,y_n)\} SP={(x1,y1),…,(xn,yn)}。随机采样 m m m个样例作为观测集 S P ′ \mathcal{S}'_{\mathcal{P}} SP′。利用LLM在 S P ′ \mathcal{S}'_{\mathcal{P}} SP′上执行归纳推理来重构给定的函数 P \mathcal{P} P。
3. 实验
总计构造了130万的数据,留出500条进行评估。实验分为三种训练变体:(1) 直接微调;(2) 混合预训练;(3) 混合微调。
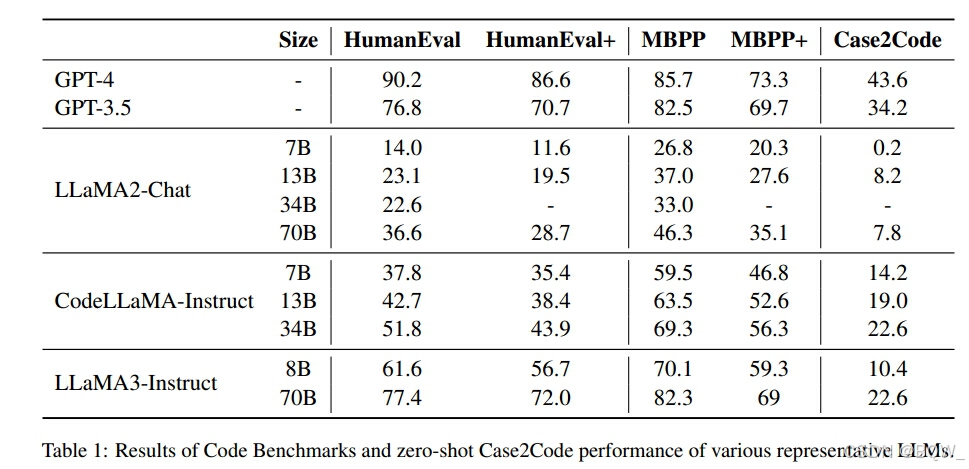
上表了各个baseline模型在代码基准和Case2Code任务上的表现。代码能力越强,在Case2Code任务上的效果越好。

使用Case2Code数据微调模型后,不但在Case2Code任务是有显著改善,且对于其他代码任务也有显著提高。
二、归纳还是演绎?重新思考LLM的推理能力
论文名称:Inductive or Deductive? Rethinking the Fundamental Reasoning Abilities of LLMs
论文地址:https://arxiv.org/pdf/2408.00114
1. 简介
推理包含两种类型:演绎(deductive)推理和归纳(inductive)推理。大多数LLM的推理研究都没有清晰区分演绎和归纳两种推理。那么LLM更擅长演绎推理还是归纳推理?演绎推理在LLM已经有比较多的研究,但是归纳推理没有被充分探索。为了深入研究LLM的归纳推理能力,提出了框架SolverLearner。该框架可以使LLM学习到将输入(x)映射至输出(y)的映射。研究发现,基于SolverLearner,LLM展现了卓越的归纳推理能力,在大多数样例中ACC接近于1。令人惊奇的是,尽管LLM有很强的归纳推理能力,但是缺乏演绎推理能力,特别是反事实推理。
2. 任务定义
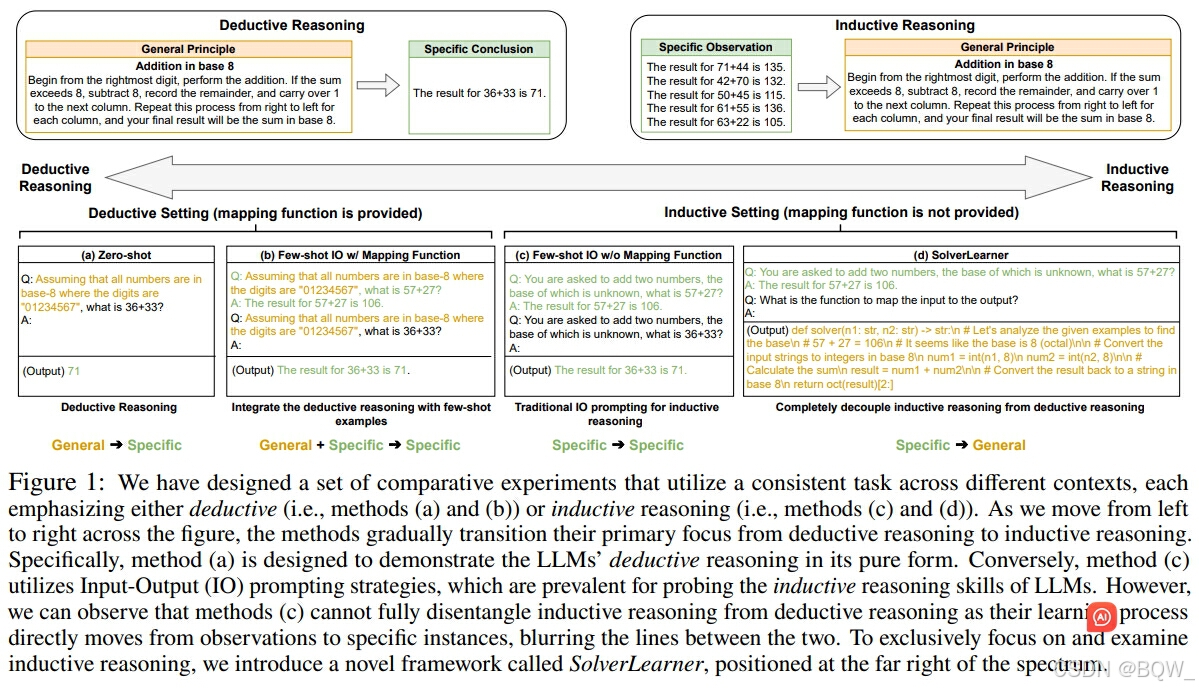
演绎和归纳推理之间的主要区别为是否为模型提供输入-输出映射。正式来说,可以描述映射为函数 f w : X → Y f_w:X\rightarrow Y fw:X→Y,其中输入 x ∈ X x\in X x∈X被转换为输出 y ∈ Y y\in Y y∈Y。区别演绎和归纳推理如下:
- 演绎推理:给模型直接提供输入-输出映射,即 f w f_w fw;
- 归纳推理:仅向模型提供少量的输入-输出样例,而不提供
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1291
1291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











