







参考:https://www.cnblogs.com/pinard/p/6744056.html
import pandas as pd
import numpy as np
import jieba
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import TfidfVectorizer
%matplotlib inline
一、数据加载
数据使用小说《白夜行》
document = pd.read_csv("./Data/BYX.txt",encoding="GBK",header=None)
document.columns = ['sentences'] # 重命名列名
document['sentences'] = document['sentences'].apply(lambda x: x.strip()) # 去除文本前后的空白
document['lens'] = document['sentences'].apply(len) # 统计文本长度
document = document[document['lens']>1] # 去除文本长度小于等于1的文本
document.index = np.arange(len(document))
document.head()
| sentences | lens | |
|---|---|---|
| 0 | 第一章 | 3 |
| 1 | 出了近铁布施站,沿着铁路径直向西。已经十月了,天气仍闷热难当,地面也很干燥。每当卡车疾驰而过... | 66 |
| 2 | 笹垣润三的脚步说不上轻快。他今天本不必出勤。很久没休假了,还以为今天可以悠游地看点书。为了今... | 63 |
| 3 | 公园出现在右边,大小足以容纳两场三垒棒球开打,丛林越野游戏、秋千、滑梯等常见的游乐设施一应俱... | 67 |
| 4 | 公园后面有一栋兴建中的七层建筑,乍看之下平淡无奇,但笹垣知道里面几乎空无一物。在调到大阪警察... | 67 |
二、文本长度分析
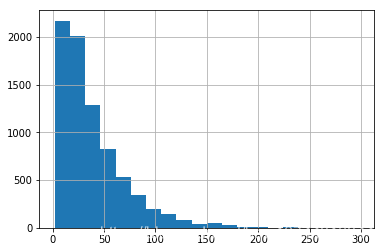
document['lens'].describe()
count 7741.000000
mean 38.602248
std 33.024336
min 2.000000
25% 15.000000
50% 29.000000
75% 52.000000
max 298.000000
Name: lens, dtype: float64
document['lens'].hist(bins=20)
三、去除特殊字符
punct = "/-'?!.,#$%\'()*+-/:;<=>@[\\]^_`{|}~`" + '""“”’' + '∞θ÷α•à−β∅³π‘₹´°£€\×™√²—–&'
def clean_special_chars(text, punct):
for p in punct:
text = text.replace(p, ' ')
return text
document['sentences'] = document['sentences'].apply(lambda x:clean_special_chars(x,punct))
四、分词
这里使用结巴分词
先尝试对某句文本进行分词
'/'.join(jieba.cut(document['sentences'][2]))
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.914 seconds.
Prefix dict has been built succesfully.
'笹垣润/三/的/脚步/说不上/轻快/。/他/今天/本/不必/出勤/。/很久没/休假/了/,/还/以为/今天/可以/悠游/地/看点/书/。/为了/今天/,/他/特地/留着/松本/清张/的/新书/没/看/。'
可以发现对文本中的日本人名分词并不准确,因此手动加入一些词汇
jieba.suggest_freq('桐原亮司',True)
jieba.suggest_freq('桐原洋介',True)
jieba.suggest_freq('笹垣润三',True)
jieba.suggest_freq('桐原弥生子',True)
jieba.suggest_freq('唐泽雪穗',True)
jieba.suggest_freq('唐泽礼子',True)
jieba.suggest_freq('园村友彦',True)
jieba.suggest_freq('松浦勇',True)
jieba.suggest_freq('寺崎忠夫',True)
jieba.suggest_freq('田川敏夫',True)
jieba.suggest_freq('秋吉雄一',True)
jieba.suggest_freq('西口奈美江',True)
1
人名分词结果正常了
'/'.join(jieba.cut(document['sentences'][2]))
'笹垣润三/的/脚步/说不上/轻快/。/他/今天/本/不必/出勤/。/很久没/休假/了/,/还/以为/今天/可以/悠游/地/看点/书/。/为了/今天/,/他/特地/留着/松本/清张/的/新书/没/看/。'
对所有文本进行分词
document['sentences'] = document['sentences'].apply(lambda x: ' '.join(jieba.cut(x)))
分词结果
document.head()
| sentences | lens | |
|---|---|---|
| 0 | 第一章 | 3 |
| 1 | 出 了 近 铁 布施 站 , 沿着 铁路 径直 向西 。 已经 十月 了 , 天气 仍 闷热... | 66 |
| 2 | 笹垣润三 的 脚步 说不上 轻快 。 他 今天 本 不必 出勤 。 很久没 休假 了 , 还... | 63 |
| 3 | 公园 出现 在 右边 , 大小 足以 容纳 两场 三垒 棒球 开打 , 丛林 越野 游戏 、... | 67 |
| 4 | 公园 后面 有 一栋 兴建 中 的 七层 建筑 , 乍看之下 平淡无奇 , 但 笹垣 知道 ... | 67 |
五、引入停用词
一些出现频率高,但是本身没什么含义的词通常会被作为停用词,例如“的”。这里使用常用的1208个停用词的停用词表。停用词下载地址
with open('./Data/stop_words.txt','r',encoding='GBK') as f:
stop_words = f.read().splitlines()
六、向量化与TF-IDF
corpus = document['sentences'].values
vector = TfidfVectorizer(stop_words=stop_words)
tfidf = vector.fit_transform(corpus)
array = tfidf.toarray()
array就一个二维矩阵,每一行代表一条文本
array.shape
(7741, 14729)
再来看一些的tf-idf值
wordlist = vector.get_feature_names() # 获得词袋模型中的所有词
for i in range(3): # 第i行文本,为了简便这里是看前3行文本
for j in range(len(wordlist)):
if array[i][j] != 0:
print(wordlist[j])
print(array[i][j])
第一章
1.0
十月
0.24989685349204657
卡车
0.22914002088030233
向西
0.2651939249707691
地面
0.24989685349204657
天气
0.22914002088030233
尘土
0.2773358936823855
已经
0.13796942335803583
布施
0.2069221287718632
干燥
0.2651939249707691
径直
0.2398209300952238
扬起
0.23582222845889703
疾驰
0.2773358936823855
皱眉
0.2565790610706412
眼睛
0.15844240759363126
铁路
0.24989685349204657
闷热
0.2651939249707691
难当
0.2773358936823855
今天
0.4389572155556546
以为
0.16140224516974414
休假
0.22732527856527882
出勤
0.25792099995568085
很久没
0.22732527856527882
悠游
0.23861724899849351
新书
0.25792099995568085
松本
0.25792099995568085
清张
0.25792099995568085
特地
0.2037285196918468
留着
0.24662902952246618
看点
0.25792099995568085
笹垣润三
0.22732527856527882
脚步
0.17121138644786196
说不上
0.2193134980413062
轻快
0.23861724899849351
七、词云
def show_wordcloud(data, title = None):
wordcloud = WordCloud(
background_color='white',
stopwords=stop_words,
max_words=50,
max_font_size=40,
scale=5,
random_state=1,
font_path = "./Fonts/msyh.ttf" # 指定一个看显示中文的字体,不然会有显示问题(字体可以下载)
).generate(str(data))
fig = plt.figure(1, figsize=(10,10))
plt.axis('off')
if title:
fig.suptitle(title, fontsize=20)
fig.subplots_adjust(top=2.3)
plt.imshow(wordcloud)
plt.show()
cloud_corpus = document[document['lens']>10]['sentences'].values # 选择长度大于10的文件当做词云的语料
show_wordcloud(cloud_corpus,title="wordcloud")




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











