







目录
六、建模与评价
一、摘要
本文基于kaggle上Give Me Some Credit数据和菜菜的sklearn课堂的处理思路,结合信用卡评分构建原理,采用python语言完成。主要包括特征预处理、特征选择、数据分箱、将特征WOE值映射到数据中、使用逻辑回归进行建模和参数优化。
ps:第一次写,请多指教。
二、数据集介绍
数据集约15W条样本数据,各特征及标签含义如下:
| 特征/标签 | 含义 |
| SeriousDlqin2yrs | 0:好客户 1:坏客户 |
| RevolvingUtilizationOfUnsecuredLines | 贷款以及信用卡可用额度与总额度比例 |
| age | 借款人年龄 |
| NumberOfTime30-59DaysPastDueNotWorse | 两年内35-59天逾期次数 |
| NumberOfTime60-89DaysPastDueNotWorse | 两年内60-89天逾期次数 |
| NumberOfTimes90DaysLate | 两年内90天或高于90天逾期的次数 |
| DebtRatio | 负债比率 |
| MonthlyIncome | 借款人的月收入 |
| NumberOfOpenCreditLinesAndLoans | 开放式信贷和贷款数量 |
| NumberRealEstateLoansOrLines | 不动产贷款或额度数量 |
| NumberOfDependents | 借款人的家属数量(不包括本人在内 |
三、数据探索
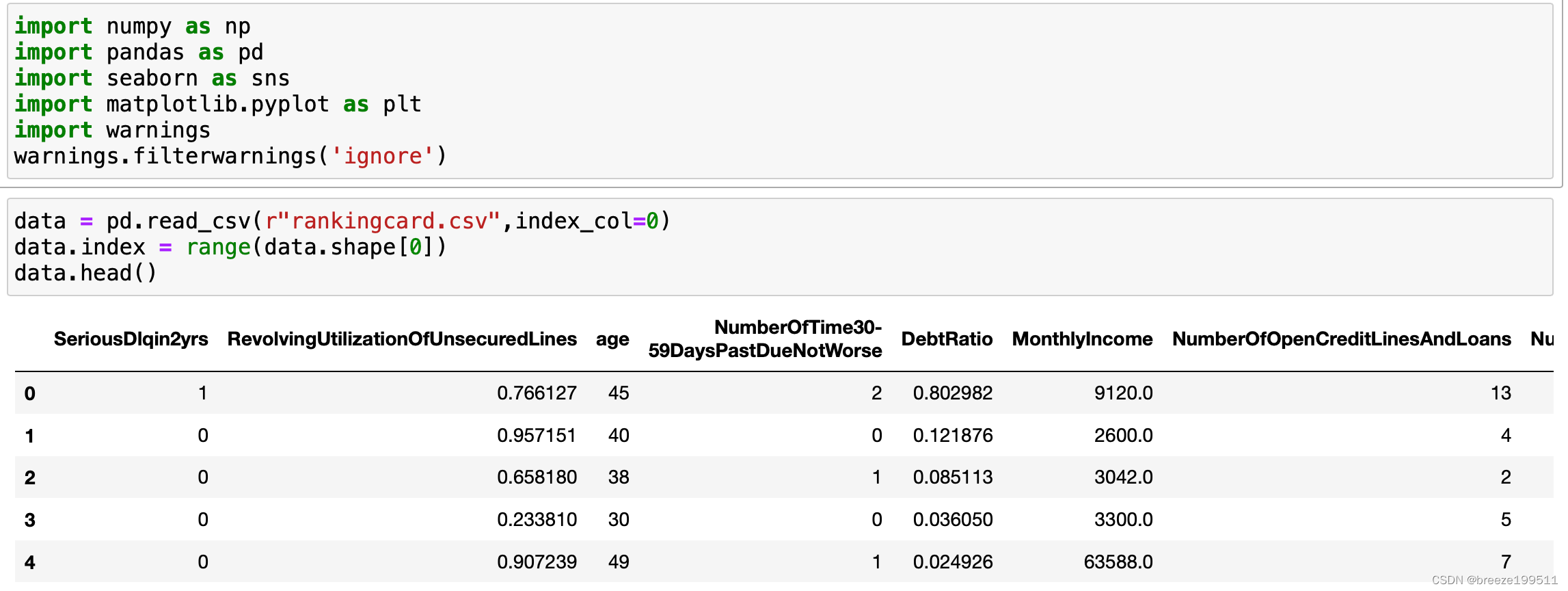
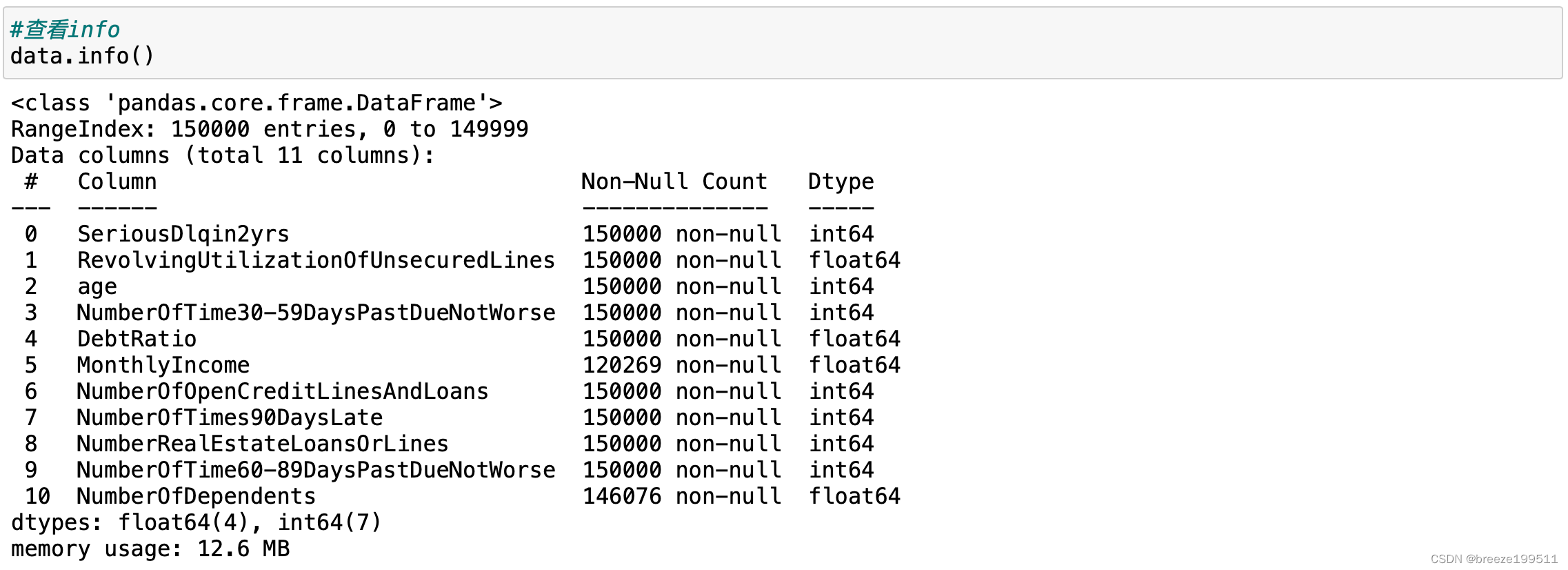
数据集共有150000行,其中MonthlyIncome和NumberOfDependents存在缺失值。
3.1 查看标签
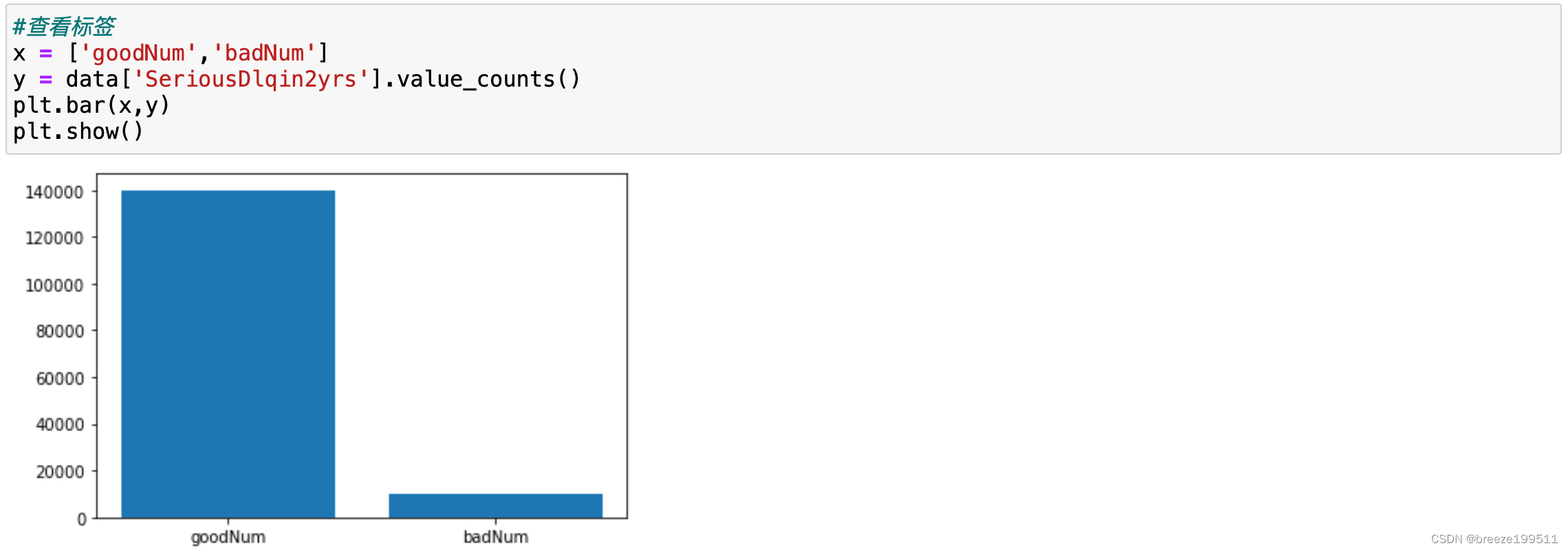
结论:样本分布极其不均衡,稍后通过过采样方式处理。
3.2 查看缺失比例
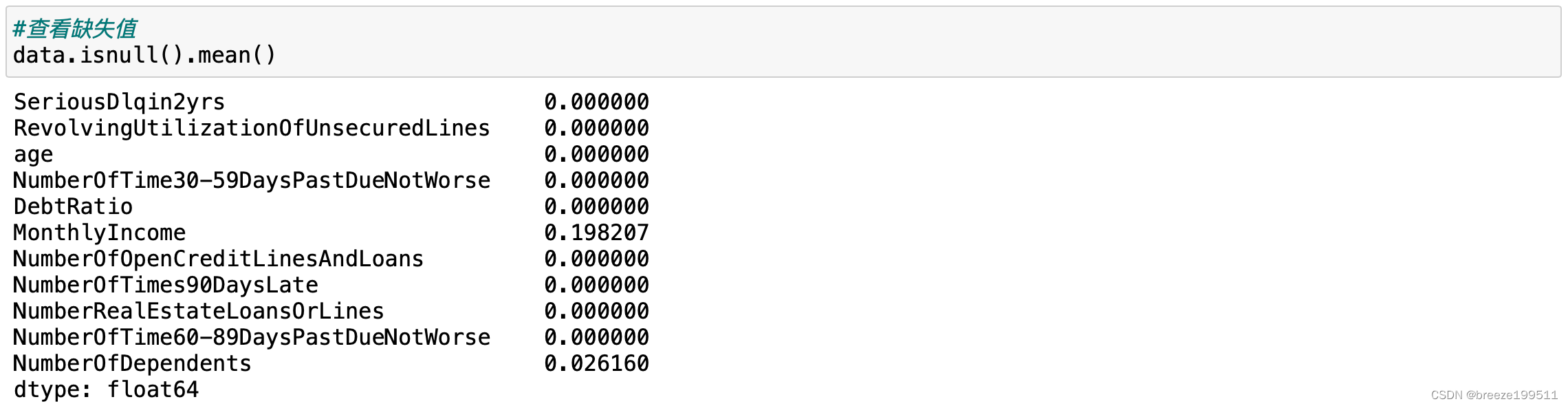
MonthlyIncome缺失较多,NumberOfDependents有部分缺失。
月收入缺失接近20%,这项指标作为借贷的重要参考缺失这么多很反常,应该及时和业务部门沟通。
假设1:因为月收入会影响借贷额,如果收入高自然借贷额高,没有理由不写。考虑是收入低的人群,为了能够借更多而故意隐瞒。如果是这样,就将缺失值都赋值为0处理。
假设2:数据录入异常,这个要结合业务处理。本案例无法结合业务,稍后可采用随机森林填补缺失值。

如果是假设1,那么应当是SeriousDlqin2yrs为1(坏客户)的客户更多,排除假设1,稍后按照假设2处理。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3540
3540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









