







Abstract.
本文引入了一个基于度量学习的小样本学习的负边缘损失,负边缘损失显著优于softmax损失,在三个标准的小样本分类基准上实现了最好效果的accuracy。这些结果与度量学习领域的普遍做法相反,普遍做法的边际为零或正。为了理解为什么负边缘损失在小样本分类中表现良好,我们从经验和理论两方面分析了训练类和新类在不同边缘下学习到的特征的可鉴别性(discriminability)。我们发现,负边缘虽然降低了训练类的特征可识别性(discriminability),但也可以避免将相同的新类的样本错误映射到多个峰值或聚类(avoid falsely mapping samples of the same novel class to multiple peaks or clusters),从而有利于新类的识别。
代码在athttps://github.com/bl0/negative-margin.few-shot
这个discriminability是啥含义?需要思考。识别能力?
Keywords: Few-shot classification · Metric learning · Large margin
loss
1 Introduction
度量学习的目标是在base classes学习一个meta-learner并且将它推广到新类。基于度量学习的方法[3,7,25]是一系列重要的元学习方法,在基类中进行度量学习,然后将学到的度量转移到新类中。例如,[3]证明,简单地使用标准softmax损失或余弦softmax损失作为基类的学习度量,可以通过在新类上学习线性分类器,实现最先进的小样本分类性能。
在度量学习领域,一个普遍的观点是标准的softmax损失不足以区分不同的训练类别。之前的一些方法将大的和正的边界整合到softmax损失[22]或余弦softmax损失[6,47],以强制真实标签类的分数比其他类的分数至少大一个边界(enforce the score of ground truth class larger than that of other classes by at least a margin)。这有助于学习具有高度区别性的深度特征,在视觉识别任务中,特别是在人脸识别任务中,性能有显著提高[6,22,47]。

因此,它激励我们在小样本分类采用这种 large-margin softmax损失来学习更好的度量。正如我们所预期的,如图1中的蓝色曲线所示,具有正边距的large-margin softmax所学习的度量在训练类别上更具有识别力,从而在训练类别的验证集上获得更高的小样本分类精度。但在小样本分类的标准 open-set 设置中,如图1中红色曲线所示,我们惊讶地发现在softmax loss中添加正margin会影响性能。
从我们的角度来看,正margin将使学习的度量对训练类别更好识别。而对于新类,正margin会将同一类的样本映射到基类中的多个峰或簇(如图3和图7所示),损害其识别能力。然后我们给了一个理论分析,在适当的假设下,新类中样本的识别能力是关于margin参数单调递减的。相反,适当的负边距可以更好地权衡新类的可分辨性和可转移性,在少镜头分类中获得更好的性能。
主要贡献如下:
- 这是第一次尝试证明带负margin的softmax损失在小样本分类中惊人地有效,这打破了margin只能被限制为正值的固有理解[6,22,47]。
- 我们提供了深刻的直观的解释和理论分析,为什么负margin适用于小样本分类。
- 提出的负margin方法在三个广泛使用的小样本分类基准上取得了最先进的性能。
2 Related Work
Few-Shot Classification.
三种代表方法:gradient-based methods, hallucination-based methods, and metric-based methods.
基于梯度的方法通过学习和任务无关的知识来解决小样本分类问题。[9,27,29,31,39]的研究重点是学习合适的模型参数初始化,使其能够在有限的标记数据和少量的梯度更新步骤的情况下快速适应新任务。另一项工作旨在学习优化器,如基于lstm的元学习器[37]和带有外部存储器的权值更新机制[28],以取代随机梯度下降优化器。然而,这些工作解决双或双层优化问题(dual or bi-level optimization problem)面临挑战,因此在大数据集上的性能不具有竞争力。最近,[1,19]通过像SVM等封闭模型(closed-form)缓解了优化问题,在大数据集的少镜头分类基准上取得了更好的性能。(啥叫大数据集的小样本分类基准?)
基于幻觉的方法试图通过从基类学习图像生成器来解决数据有限的问题,该方法被用于在新类图片中产生幻觉[12,48](which is adopted to hallucinate new images in novel classes)。[12]提出了一种通过从转移基类变异模式对新类产生额外示例的方法。[48]通过对分类器和幻觉器的端到端优化,学习产生幻觉的例子,这例子是对分类有用的。由于基于幻觉的方法可以看作是一种补充,通常与其他少镜头的方法一起使用,所以我们在实验比较中采用[3]排除这些方法,留待以后研究。(没看懂这句话)
基于度量的方法旨在学习可转移的距离度量。MatchingNet[45]计算标记图像和未标记图像嵌入之间的余弦相似度,对未标记图像进行分类。ProtoNet[43]通过类内样本的平均嵌入来表示每个类,并根据到每个类的平均嵌入的距离来进行分类。RelationNet [44] 将 ProtoNet 中的非参数距离替换为参数化的关系模块。最近,[3,7,25]揭示了简单的预训练和微调pipeline(遵循标准迁移学习范式)可以与最先进的少镜头分类方法取得惊人的竞争性能。
基于这个简单的范例,我们的工作是第一次努力明确地将margin参数与softmax损失整合,最重要的是打破了margin只能被限制为正值的固有理解,既有直观的理解,又有理论的分析。
Margin Based Metric Learning.
在实践中,数据点集与决策边界之间的margin对实现较强的泛化性能起着重要的作用。[16]提出了margin理论,并证明了margin损失会导致分类任务的信息泛化边界( informative generalization bound)。在过去的几十年里,基于边缘的(margin-based)度量学习思想在支持向量机[40]、k-NN分类[49]、多任务学习[33]等方面得到了广泛的探索。在深度学习时代,许多基于边缘的度量学习方法被提出,以增强学习到的深度特征的辨别能力,并在许多任务中表现出显著的性能提升[19,20,30],特别是在人脸验证[6,21,41,47]。例如,SphereFace [21], CosFace[47]和ArcFace[6]通过增加余弦softmax损失的边缘来加强类内方差和类间多样性。
但是,由于以往工作的任务是基于闭集(close-set)场景的,他们将margin参数限制为正值[6,21,47],使得深度特征更具有甄别性,可以推广到验证集,提高性能。【通过margin参数,特征更加牛,特征表示加强了?】对于open-set场景,如小样本学习,增加边缘值不会加强类间的多样性,但不幸的是会扩大新类的类内方差,如图2所示,这会影响性能。相反,适当的负边缘可以更好地权衡深度特征在新类中的可鉴别性和可转移性,从而获得较好的小样本分类性能。
3 Methodology
训练数据定义

小样本分类的目的是从基类中丰富的标记数据中学习具有鉴别性和可转移性的特征表示,从而使特征易于适应标记样本较少的新类。
3.1 Negative-Margin Softmax Loss
在图像分类中,softmax损失建立在深度网络zi = fθ(xi) (fθ(·)为参数θ的backbone)及其对应的标签yi和线性变换矩阵W的特征表示之上。最近,在度量学习中,将大的正的边缘参数引入到softmax损失中被广泛研究[6,22,47]。因此,我们直接将边缘参数集成到softmax损失中来学习可转移度量,旨在对新类进行小样本分类。 large-margin softmax loss的一般公式定义为:

m是margin parameter,β表示温度参数,它定义了扩大最大logit和其他logit之间的差距的强度,并且s(·, ·)代表两个输入向量的相似度函数。
这是因为之前的工作主要集中在close-set场景上,较大的边缘损失导致类内方差较小,类间方差较大,这将有助于对同一类中的例子进行分类。在 open-set场景中。对训练类别过于区分的学习度量可能会损害它们在新类别中的适用性【就是对训练类别过拟合了?不够泛化了。因为在close-set场景,训练集测试集都在一个数据集,而在open-set场景,训练集和测试集一分开,再用正margin就行不通了】。
这里我们用不同的相似函数来表示Eq. 1的两个实例。将内积相似度s (zi, Wj) = WjT zi带入Eq. 1,可得到negative-margin softmax loss(简称Neg- Softmax)。通过取余弦相似度s (zi, Wj)带入Eq. 1,我们可以得到negative-margin cosine softmax loss(简称Neg-Cosine)。损失函数的更多细节可以在附录中找到。在预训练阶段采用这两个损失函数。余弦相似度:
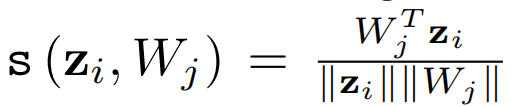
3.2 Discriminability Analysis of Deep Features w.r.t Different
Margins
我们分析了不同边缘的深度模型提取的深度特征的可识别力,以理解为什么负边缘对新类有效。为简便起见,我们只分析了 the cosine softmax loss,将分析和结论推广到标准softmax loss。

我们将用边缘参数m训练的预训练backbone网络表示为fθ(m)。对于基类或新类中的类j,将带有标签类j的一组样本表示为Ij = {(xi, yi)|yi = j}.我们计算类j的中心
为L2正规化过的特征嵌入的均值:

数据集定义:

类间方差和类内方差:

对于每两个类,类间的方差是类中心之间L2距离的平方。对于每个类,类内方差是这个类中每个样本到类中心的L2距离的平方。
当类间方差变大或类内方差变小时,深度特征的判别性更强。因此,我们根据[26]定义判别函数φ(I,m)为类间方差除以类内方差:

为了测量不同边缘下的深度特征的可判别性,我们分别在mini-ImageNet的基类和新类上绘制了关于边缘m的类间方差Dinter、类内方差Dintra和判别函数φ 。如图2所示,对于基类(红色曲线),随着margin的增加,类间方差增加很多,同时类内方差变化不大,因此基类的特征变得更具辨别力。 这在以前的工作中被广泛观察到[6,22,47],并促使他们在close-set中引入大的和正的margin到softmax损失。
但对于新类(蓝色曲线),情况正好相反。随着边缘值的增加,类间方差变化不大,但类内方差增加很多,基类特征的discriminability减弱。这表明,较大的边缘可能会损害新类别的分类。这一点在真实的小样本分类任务中也得到了验证,如图1中的红色曲线所示,较大的正的边缘会导致新类的小样本分类性能较差。相反,适当的负边际可以达到最佳的性能,这可能导致更好的权衡discriminability和可转移性的新类。
3.3 Intuitive Explanation

为了更好地理解边缘是如何工作的,我们对MNIST1上训练的角空间中的数据分布进行可视化,如图3。我们选择了七个类作为基类来进行预训练,另外三个类作为新类。我们首先用在基类上使用具有不同边缘的余弦softmax损失来训练带有二维输出特征的深度模型。使用不同边缘训练的模型,然后我们对二维特征进行标准化,以获得每个数据点的方向,并在基类(第一行)和新类(第二行)上可视化每个方向(也称为角空间中的数据分布)的计数。
如图3第一行所示,随着从左到右的边缘增大甚至为正,每个训练类别的聚类变细变高,不同类中心之间的角度差也变大。这与我们之前在图2中的观察相吻合,即扩大边缘导致基类上的类内方差较小,类间方差较大。
但是,然而,随着margin越大,远离所有中心的空间中的数据点就会越少,这在一定程度上使得输出空间更窄【这句话不懂】。如图3第二行右侧所示,由于novel类与base类不同,因此有较大margin的模型或许将novel类中同一类的数据点映射到属于不同base类的多个峰值或簇。因此新类的类内方差也随之增大,使得新类的分类更加困难。相反,如图3第二行左侧所示,适当的负边缘不会使novel类中的数据点过于靠近training center【训练中心是啥?】,可以缓解multipeak问题,有利于novel类的分类。
【小样本分类问题始终是分类问题,如何更好的区分不同的类,如何让类内方差不要太大,在训练集上让不同的类区分的更好,然后将学到的通用知识用到测试集上。】
3.4 Theoretical Analysis
 将在边缘为 m 的基类上联合主干预训练的分类器的参数表示为W(m)【这句话也不懂】,通过预训练的特征提取器fθ(m)和分类器W(m),新类别j中的样本被分类为基类k的概率为:【新类别中的样本怎么可能分类为基类,他俩的类别根本不一样啊?】
将在边缘为 m 的基类上联合主干预训练的分类器的参数表示为W(m)【这句话也不懂】,通过预训练的特征提取器fθ(m)和分类器W(m),新类别j中的样本被分类为基类k的概率为:【新类别中的样本怎么可能分类为基类,他俩的类别根本不一样啊?】

s(·, ·)代表相似度函数。同一新类别j中的一对样本被归入同一基类的概率为:



Proposition.(命题)
假设基类的判别函数φ(Ib, m)是关于边距参数m的单调递增函数,然后我们表示

【-1是啥意思?反函数?左边式子因为m1<m2,函数递增,所以为负;右边为正,怎么可能相等】
其中m2 > m1并且r > 0是一个比例(scale)变量。

是一个单调递减函数,并且我们表示

【上面等式也是左为正右为负】
然后

我们有:

在适当的假设和基类与新类相似度的可测条件下【什么意思???】,用P^s证明了新类上的φ(In, m)的判别函数是一个w.r.t m单调递减函数。该命题表明,适当的“负”边距值可以很好地用于识别新类别的样本。
图4显示了mini-ImageNet数据集的实际行为。首先,在mini-ImageNet上,我们根据同一新类j中的样本对分类为同一基类的概率Pjs(为清晰起见,每3个类别中的一个被绘制),对36个新类进行排序。新类中样本被划分为64个基类的直方图如图4(a)【a图也不懂!!!】。图4(b)显示了不同平均值P^s的新类在不同边距下的精度曲线。
Ps【P^s代表啥嘛?】越小,新类的直方图越多样化(如图4(a)),准确率越低(如图4(b))。重要的是,大多数新类的子集倾向于负边距,这意味着命题中的条件并不难达到。
3.5 Framework
按照标准迁移学习范式[8,52],我们采用两阶段的训练管道进行小样本分类,包括pre-training阶段对基类中丰富的标记数据进行度量学习,以及fine - tuning阶段学习分类器识别新类。这种pipeline在最近的小样本学习方法中被广泛采用[3,7,25]。
在预训练阶段,我们的目标是在基类中具有丰富标记数据Ib的条件下,训练backbone网络fθ(·),由度量学习损失驱动,如[3]中的softmax损失。在本文中,我们采用负边距的软最大损失,它可以学习到更多的可转移的表示。在微调阶段,由于在In中只有很少的标记样本用于训练(例如:5-way 1-shot 学习只包含5个训练样本),我们按照[3]确定主干fθ(·)的参数,并且只通过 softmax 损失从头开始训练一个新的分类器。需要注意的是,softmax loss 中相似度(如内积相似度或余弦相似度)的计算与预训练阶段相同。
4 Experiments
4.1 Setup
Implementation Details.
为了公平比较,我们用四种常用的骨干网来评估我们的模型,即conv4[45]、ResNet-12[32]、ResNet-18[3]和WRN-28-10[25,53]。除了网络深度和结构上的差异外,con -4和ResNet-12的预期输入大小为84×84, ResNet-18的预期输入大小为224×224,而WRN-28-10以80×80的图像作为输入。
我们的实现基于PyTorch[34]。在训练阶段,backbone网络和分类器从头开始训练,批量大小为256. 模型分别在CUB、miniImageNet和mini-ImageNet→CUB中训练200、400和400个epochs。我们采用Adam[15]优化器带有初始学习率3e-3和余弦学习率衰减[23]。我们使用与[3]相同的数据增强,包括随机裁剪、水平翻转和颜色抖动。【预训练阶段的监督学习是元学习的训练吗?】
在微调阶段,每episode包含5个类,每个类包含1或5张支持集图像,从头训练一个新的分类器,以及16张查询集图像,测试准确率。最终性能报告为 95% 置信区间的 600 个随机采样episodes的平均分类准确率。注意,所有超参数都是由验证集的性能决定的【嗯哼,这透漏了什么?】。
4.2 Results
4.3 Analysis
Effects of Negative Margin.
通过采用适当的负margin,负softmax和负余弦在所有三个基准上都比标准softmax损失和余弦softmax损失产生显著的性能增益。有趣的是,neg- cos在域内设置(如mini-ImageNet和CUB)的性能优于NegSoftmax,而NegSoftmax在跨域设置(如mini-ImageNet和CUB)的性能优于NegSoftmax。这在[3]中也可以观察到。
Various Regularization Techniques.
表5显示了正则化对负余弦的重要性,从表中可以看出,在miniImageNet基准上,综合各种正则化技术可以稳步提高 1-shot 和 5-shot的测试精度。
 More Shots.
More Shots.
我们做了一个实验,改变从1(少量)到300(大量),并报告图6中mini-ImageNet数据集上验证集的分类精度。结果表明,从1-shot到 300-shot的场景margin=−0.3的测试精度始终高于margin=0的测试精度,这证明了负边距可能有利于有更多shots 的 open-set 场景。

5 Conclusion
在本文中,我们不寻常地提出采用适当的负边距 softmax 损失来进行小样本分类,这在小样本分类的 open-set 场景中令人惊讶地工作得很好。然后我们提供了直观的解释和理论证明,以理解为什么负边际适用于少拍分类。这一说法也通过充分的实验得到了证明。通过负边距softmax损失,我们的方法在所有三个标准基准上实现了最先进的性能少镜头分类。在未来,负边际可能被应用于更一般的 open-set 场景,不限制新类的样本数量。















 2210
2210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









