
import numpy as np
from utils import *
import random
from random import shuffle

data = open('dinos.txt', 'r').read()
data= data.lower()
chars = list(set(data))
data_size, vocab_size = len(data), len(chars)
print('There are %d total characters and %d unique characters in your data.' % (data_size, vocab_size))
There are 19909 total characters and 27 unique characters in your data.

char_to_ix = { ch:i for i,ch in enumerate(sorted(chars)) }
ix_to_char = { i:ch for i,ch in enumerate(sorted(chars)) }
print(ix_to_char)
{0: '\n', 1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e', 6: 'f', 7: 'g', 8: 'h', 9: 'i', 10: 'j', 11: 'k', 12: 'l', 13: 'm', 14: 'n', 15: 'o', 16: 'p', 17: 'q', 18: 'r', 19: 's', 20: 't', 21: 'u', 22: 'v', 23: 'w', 24: 'x', 25: 'y', 26: 'z'}



### GRADED FUNCTION: clip
def clip(gradients, maxValue):
'''
Clips the gradients' values between minimum and maximum.
Arguments:
gradients -- a dictionary containing the gradients "dWaa", "dWax", "dWya", "db", "dby"
maxValue -- everything above this number is set to this number, and everything less than -maxValue is set to -maxValue
Returns:
gradients -- a dictionary with the clipped gradients.
'''
dWaa, dWax, dWya, db, dby = gradients['dWaa'], gradients['dWax'], gradients['dWya'], gradients['db'], gradients['dby']
### START CODE HERE ###
# clip to mitigate exploding gradients, loop over [dWax, dWaa, dWya, db, dby]. (≈2 lines)
for gradient in [dWax, dWaa, dWya, db, dby]:
np.clip(gradient, -maxValue, maxValue, out = gradient)
### END CODE HERE ###
gradients = {"dWaa": dWaa, "dWax": dWax, "dWya": dWya, "db": db, "dby": dby}
return gradients
np.random.seed(3)
dWax = np.random.randn(5,3)*10
dWaa = np.random.randn(5,5)*10
dWya = np.random.randn(2,5)*10
db = np.random.randn(5,1)*10
dby = np.random.randn(2,1)*10
gradients = {"dWax": dWax, "dWaa": dWaa, "dWya": dWya, "db": db, "dby": dby}
gradients = clip(gradients, 10)
print("gradients[\"dWaa\"][1][2] =", gradients["dWaa"][1][2])
print("gradients[\"dWax\"][3][1] =", gradients["dWax"][3][1])
print("gradients[\"dWya\"][1][2] =", gradients["dWya"][1][2])
print("gradients[\"db\"][4] =", gradients["db"][4])
print("gradients[\"dby\"][1] =", gradients["dby"][1])
gradients["dWaa"][1][2] = 10.0
gradients["dWax"][3][1] = -10.0
gradients["dWya"][1][2] = 0.2971381536101662
gradients["db"][4] = [10.]
gradients["dby"][1] = [8.45833407]
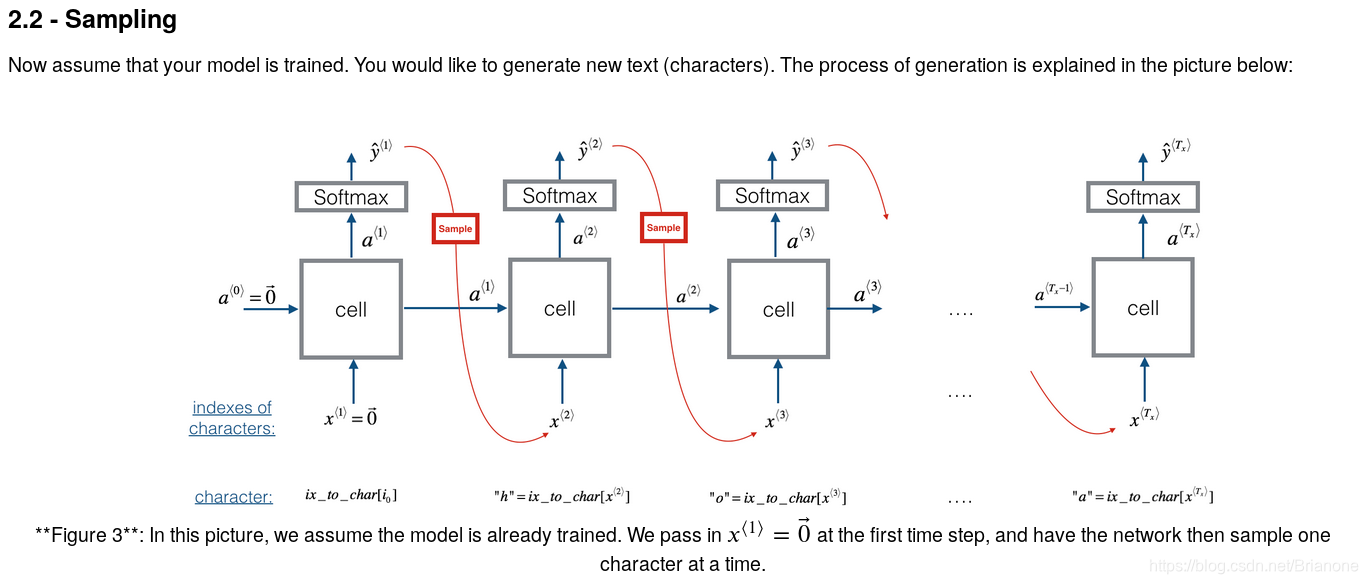


# GRADED FUNCTION: sample
def sample(parameters, char_to_ix, seed):
"""
Sample a sequence of characters according to a sequence of probability distributions output of the RNN
Arguments:
parameters -- python dictionary containing the parameters Waa, Wax, Wya, by, and b.
char_to_ix -- python dictionary mapping each character to an index.
seed -- used for grading purposes. Do not worry about it.
Returns:
indices -- a list of length n containing the indices of the sampled characters.
"""
# Retrieve parameters and relevant shapes from "parameters" dictionary
Waa, Wax, Wya, by, b = parameters['Waa'], parameters['Wax'], parameters['Wya'], parameters['by'], parameters['b']
vocab_size = by.shape[0]
n_a = Waa.shape[1]
### START CODE HERE ###
# Step 1: Create the one-hot vector x for the first character (initializing the sequence generation). (≈1 line)
x = np.zeros(( vocab_size, 1))
# Step 1': Initialize a_prev as zeros (≈1 line)
a_prev = np.zeros(( n_a, 1))
# Create an empty list of indices, this is the list which will contain the list of indices of the characters to generate (≈1 line)
indices = []
# Idx is a flag to detect a newline character, we initialize it to -1
idx = -1
# Loop over time-steps t. At each time-step, sample a character from a probability distribution and append
# its index to "indices". We'll stop if we reach 50 characters (which should be very unlikely with a well
# trained model), which helps debugging and prevents entering an infinite loop.
counter = 0
newline_character = char_to_ix['\n']
while (idx != newline_character and counter != 50):
# Step 2: Forward propagate x using the equations (1), (2) and (3)
a = np.tanh( np.dot(Waa, a_prev) + np.dot(Wax, x) + b)
z = np.dot(Wya, a) + by
y = softmax(z)
# for grading purposes
np.random.seed(counter+seed)
# Step 3: Sample the index of a character within the vocabulary from the probability distribution y
idx = np.random.choice(vocab_size, p = y.ravel())
# Append the index to "indices"
indices.append(idx)
# Step 4: Overwrite the input character as the one corresponding to the sampled index.
x = np.zeros(( vocab_size, 1))
x[idx,:] = 1
# Update "a_prev" to be "a"
a_prev = a
# for grading purposes
seed += 1
counter +=1
### END CODE HERE ###
if (counter == 50):
indices.append(char_to_ix['\n'])
return indices
np.random.seed(2)
n, n_a = 20, 100
a0 = np.random.randn(n_a, 1)
i0 = 1 # first character is ix_to_char[i0]
Wax, Waa, Wya = np.random.randn(n_a, vocab_size), np.random.randn(n_a, n_a), np.random.randn(vocab_size, n_a)
b, by = np.random.randn(n_a, 1), np.random.randn(vocab_size, 1)
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "b": b, "by": by}
indices = sample(parameters, char_to_ix, 0)
print("Sampling:")
print("list of sampled indices:", indices)
print("list of sampled characters:", [ix_to_char[i] for i in indices])
Sampling:
list of sampled indices: [18, 2, 26, 0]
list of sampled characters: ['r', 'b', 'z', '\n']


# GRADED FUNCTION: optimize
def optimize(X, Y, a_prev, parameters, learning_rate = 0.01):
"""
Execute one step of the optimization to train the model.
Arguments:
X -- list of integers, where each integer is a number that maps to a character in the vocabulary.
Y -- list of integers, exactly the same as X but shifted one index to the left.
a_prev -- previous hidden state.
parameters -- python dictionary containing:
Wax -- Weight matrix multiplying the input, numpy array of shape (n_a, n_x)
Waa -- Weight matrix multiplying the hidden state, numpy array of shape (n_a, n_a)
Wya -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a)
b -- Bias, numpy array of shape (n_a, 1)
by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1)
learning_rate -- learning rate for the model.
Returns:
loss -- value of the loss function (cross-entropy)
gradients -- python dictionary containing:
dWax -- Gradients of input-to-hidden weights, of shape (n_a, n_x)
dWaa -- Gradients of hidden-to-hidden weights, of shape (n_a, n_a)
dWya -- Gradients of hidden-to-output weights, of shape (n_y, n_a)
db -- Gradients of bias vector, of shape (n_a, 1)
dby -- Gradients of output bias vector, of shape (n_y, 1)
a[len(X)-1] -- the last hidden state, of shape (n_a, 1)
"""
### START CODE HERE ###
# Forward propagate through time (≈1 line)
loss, cache = rnn_forward(X, Y, a_prev, parameters)
# Backpropagate through time (≈1 line)
gradients, a = rnn_backward(X, Y, parameters, cache)
# Clip your gradients between -5 (min) and 5 (max) (≈1 line)
gradients = clip(gradients, 5)
# Update parameters (≈1 line)
parameters = update_parameters(parameters, gradients, learning_rate)
### END CODE HERE ###
return loss, gradients, a[len(X)-1]
np.random.seed(1)
vocab_size, n_a = 27, 100
a_prev = np.random.randn(n_a, 1)
Wax, Waa, Wya = np.random.randn(n_a, vocab_size), np.random.randn(n_a, n_a), np.random.randn(vocab_size, n_a)
b, by = np.random.randn(n_a, 1), np.random.randn(vocab_size, 1)
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "b": b, "by": by}
X = [12,3,5,11,22,3]
Y = [4,14,11,22,25, 26]
loss, gradients, a_last = optimize(X, Y, a_prev, parameters, learning_rate = 0.01)
print("Loss =", loss)
print("gradients[\"dWaa\"][1][2] =", gradients["dWaa"][1][2])
print("np.argmax(gradients[\"dWax\"]) =", np.argmax(gradients["dWax"]))
print("gradients[\"dWya\"][1][2] =", gradients["dWya"][1][2])
print("gradients[\"db\"][4] =", gradients["db"][4])
print("gradients[\"dby\"][1] =", gradients["dby"][1])
print("a_last[4] =", a_last[4])
Loss = 126.50397572165379
gradients["dWaa"][1][2] = 0.1947093153471512
np.argmax(gradients["dWax"]) = 93
gradients["dWya"][1][2] = -0.007773876032002509
gradients["db"][4] = [-0.06809825]
gradients["dby"][1] = [0.01538192]
a_last[4] = [-1.]

# GRADED FUNCTION: model
def model(data, ix_to_char, char_to_ix, num_iterations = 35000, n_a = 50, dino_names = 7, vocab_size = 27):
"""
Trains the model and generates dinosaur names.
Arguments:
data -- text corpus
ix_to_char -- dictionary that maps the index to a character
char_to_ix -- dictionary that maps a character to an index
num_iterations -- number of iterations to train the model for
n_a -- number of units of the RNN cell
dino_names -- number of dinosaur names you want to sample at each iteration.
vocab_size -- number of unique characters found in the text, size of the vocabulary
Returns:
parameters -- learned parameters
"""
# Retrieve n_x and n_y from vocab_size
n_x, n_y = vocab_size, vocab_size
# Initialize parameters
parameters = initialize_parameters(n_a, n_x, n_y)
# Initialize loss (this is required because we want to smooth our loss, don't worry about it)
loss = get_initial_loss(vocab_size, dino_names)
# Build list of all dinosaur names (training examples).
with open("dinos.txt") as f:
examples = f.readlines()
examples = [x.lower().strip() for x in examples]
# Shuffle list of all dinosaur names
shuffle(examples)
# Initialize the hidden state of your LSTM
a_prev = np.zeros((n_a, 1))
# Optimization loop
for j in range(num_iterations):
### START CODE HERE ###
# Use the hint above to define one training example (X,Y) (≈ 2 lines)
index = j % len(examples)
X = [None] + [ char_to_ix[ch] for ch in examples[index]]
Y = X[1:] + [char_to_ix["\n"]]
# Perform one optimization step: Forward-prop -> Backward-prop -> Clip -> Update parameters
# Choose a learning rate of 0.01
curr_loss, gradients, a_prev = optimize(X, Y, a_prev, parameters)
### END CODE HERE ###
# Use a latency trick to keep the loss smooth. It happens here to accelerate the training.
loss = smooth(loss, curr_loss)
# Every 2000 Iteration, generate "n" characters thanks to sample() to check if the model is learning properly
if j % 2000 == 0:
print('Iteration: %d, Loss: %f' % (j, loss) + '\n')
# The number of dinosaur names to print
seed = 0
for name in range(dino_names):
# Sample indices and print them
sampled_indices = sample(parameters, char_to_ix, seed)
print_sample(sampled_indices, ix_to_char)
seed += 1 # To get the same result for grading purposed, increment the seed by one.
print('\n')
return parameters
parameters = model(data, ix_to_char, char_to_ix)


from __future__ import print_function
from keras.callbacks import LambdaCallback
from keras.models import Model, load_model, Sequential
from keras.layers import Dense, Activation, Dropout, Input, Masking
from keras.layers import LSTM
from keras.utils.data_utils import get_file
from keras.preprocessing.sequence import pad_sequences
from shakespeare_utils import *
import sys
import io

print_callback = LambdaCallback(on_epoch_end=on_epoch_end)
model.fit(x, y, batch_size=128, epochs=10, callbacks=[print_callback])
# Run this cell to try with different inputs without having to re-train the model
generate_output()
Write the beginning of your poem, the Shakespeare machine will complete it. Your input is: It is a nice town
Here is your poem:
It is a nice town
where loigh, that nothing end griand, hos the canness.
mide that my duelsy and predsies seefise,
thy raqeesaon ride ford, thou sum the prase,
of live to tomp, therefore o bucutain, youth
bemave is swist amtuin ap is mes thy clay,
where soming hid but this stime me sistersed
of fayce, thy mate and prowin that fade,,
doth fiting sy orthers that to srank,
nom a one a secherares and showeared make?
a






















 7161
7161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









