







MapReduce 的根源是函数性编程中的 map 和 reduce 函数。它由两个可能包含有许多实例(许多 Map 和 Reduce)的操作组成。Map 函数接受一组数据并将其转换为一个键/值对列表,输入域中的每个元素对应一个键/值对。Reduce 函数接受 Map 函数生成的列表,然后根据它们的键(为每个键生成一个键/值对)缩小键/值对列表。其流程概念图如下:
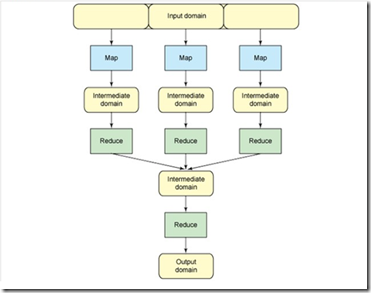
一个典型的Map-Reduce过程如下:
Input->Map->Patition->Reduce->Output
Input Phase
输入的数据需要以一定的格式传递给Mapper的,格式有多种,数据一般分布在多台机器。
Map Phase
对输入的数据进行处理,输出的是key、value的集合。
Partition Phase
把Mapper任务输出的中间结果按key的范围划分成R份(R是预先定义的Reduce任务的个数),默认的划分算法是"(key.hashCode() & Integer.MAX_VALUE) % numPartitions",这样保证了某一范围的key一定是由某个Reducer来处理。
Reduce Phase
Reducer获取Mapper输出的中间结果,作为输入对某一key范围区间进行处理。
Output Phase
Reducer的输出格式和Mapper的输入格式是相对应的,当然Reducer的输出还可以作为另一个Mapper的输入继续进行处理。
MapReduce的优缺点:
主要有两个方面:
1. 通过MapReduce这个分布式处理框架,不仅能用于处理大规模数据,而且能将很多繁琐的细节隐藏起来,比如,自动并行化、负载均衡和灾备管理等,这样将极大地简化程序员的开发工作;
2. MapReduce的伸缩性非常好,也就是说,每增加一台服务器,其就能将差不多的计算能力接入到集群中,而过去的大多数分布式处理框架,在伸缩性方面都与MapReduce相差甚远。而 MapReduce最大的不足则在于,其不适应实时应用的需求















 2701
2701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









