







前言
梯度消失/爆炸是困扰深度神经网络的大问题,ResNet和BatchNormalization的原理在网上已有不少文章介绍,但是从文章的跟帖评论中可以看出,很多细节问题仍存在争论。比如说:(1)梯度消失是由sigmoid引起的吗?(2)BN层可以解决梯度消失/梯度爆炸问题吗?(3)ResNet为什么有效?为了弄清这些问题,我们这次在LeNet基础上改造网络,通过数据试验来分析这些问题。
文章目录
一、试验用的主要代码
我们给第一节(链接)的LeNet的conv2层和fc1之间插入更多的卷积层,把它改造成一个深层网络。为了便于更改网络层数,我们建立一个ResBlock单元,包含两个卷积层和一个shortcut连接,我们通过更改插入的单元数以及删掉shortcut连接等措施来试验不同网络结构的效果。代码如下:
class ResBlock(nn.Module):
def __init__(self):
super().__init__()
self.convres1 = nn.Conv2d(16, 16, 5, padding=2)
self.convres2 = nn.Conv2d(16, 16, 5, padding=2)
#self.bn1 = nn.BatchNorm2d(16)
#self.bn2 = nn.BatchNorm2d(16)
def forward(self, x):
x1 = F.relu(self.convres1(x))
x1 = F.relu(self.convres2(x1))
x = x + x1 #shortcut连接
return x
class LeNet5(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, 5, padding=2)
self.conv2 = nn.Conv2d(6, 16, 5, padding=2)
#建立多层模块
layers = collections.OrderedDict()
for i in range(12): #包含的模块数量
name = 'block%d'%i
layers[name] = ResBlock()
self.resblocks = nn.Sequential(layers)
self.fc1 = nn.Linear(16*7*7, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), (2, 2))
#插入多层模块
x = self.resblocks(x)
x = x.view(-1, 16*7*7)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
二、观察深层网络的梯度消失、梯度爆炸现象
1.使层数变深观察梯度消失
我们先把上面代码中ResBlock中的forward中的shortcut连接一句去掉,并把返回值改为return x1以构成直连的多层网络,为了和后面的relu对比,激活函数先用sigmoid:
def forward(self, x):
x1 = F.sigmoid(self.convres1(x))
x1 = F.sigmoid(self.convres2(x1))
return x1
由于MNIST数据集简单,LeNet的网络的精度已经足够高,再增加更多的网络并不能有更好的效果,我们的目的只是用来观察梯度消失现象。每增加一个模块会增加两个卷积层,增加模块带来的效果见下图。
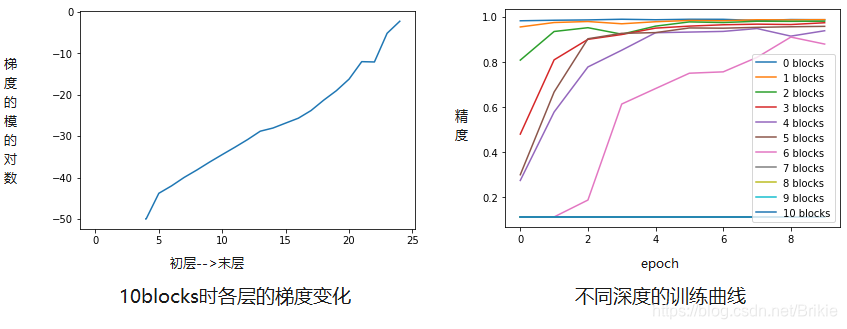
可见:(1)更多的层会使训练更慢,但增加6个模块(12层)之内时,仍可以训练;
(2)增加更多的模块(本例是7个以上),会出现梯度消失,模型根本无法训练。梯度消失是从末层到初层逐渐消失的。
2.观察梯度爆炸
如果把网络参数的初始值改的较大,梯度也会变大,如果梯度的模大于1,随着反向传播梯度会从末层到初层越来越大,层数深时就会出现梯度爆炸。更改参数初始值的代码如下:
def weight_init(m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
nn.init.uniform_(m.weight,a=-0.5,b=0.5)
model.apply(weight_init)
sigmoid会起到梯度缩小作用,更容易梯度消失,为了观察梯度爆炸,我们改成relu。
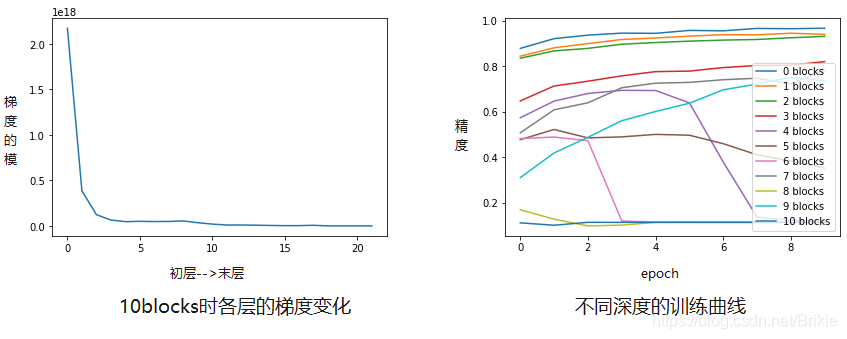
可以看出,参数初始化值较大时,梯度在反向传播时会逐层变的非常大,导致难以训练。
进一步分析各层梯度(内容略,只说结论),会发现训练之初梯度随反向传播,从末层到初层逐渐缩小,网络层数越多,初层的梯度越小。但是网络层数不太多时,随着训练的增加,初层的梯度会恢复正常,而网络层数多到一定程度后,梯度无法恢复,会逐渐到0彻底消失,导致网络无法训练。(多说一句,也就是说梯度消失/爆炸实质上是由于某种正反馈机制造成的,如果能够引入某种负反馈控制机制也许也能解决,这个问题暂时放这。)
三、试验解决梯度消失/爆炸的各种方法
1.更换激活函数
把sigmoid换成relu,不同模块数对应的训练曲线如下图,发现relu也同样会造成梯度消失,但是能够承受的网络层数确实更多了一些(10模块以上发生梯度消失)。
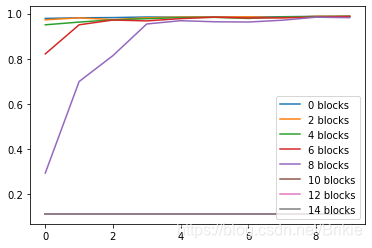
可以认为:(1)造成梯度消失或梯度爆炸的主要原因是由于卷积层每层参数的模小于1或大于1,层数过多时累积造成的。(2)sigmoid激活函数能够使梯度缩小,所以更容易造成梯度消失现象。
2.使用梯度剪裁
在训练中每次计算完梯度后加入torch.nn.utils.clip_grad_norm_或者torch.nn.utils.clip_grad_value_可以把过大的梯度裁掉。梯度剪裁去掉了过大的梯度,可以控制梯度爆炸,但对于梯度消失没有用,试验也证实了这一点(试验数据略)。
一个自然的想法是,反过来,我们能不能通过限制过小梯度的方法来限制梯度消失呢?我们可以把小于某个阈值的梯度强制置为阈值进行试验,代码如下
def clear_small_grad_value_(parameters, threshold=1e-10):
if isinstance(parameters, torch.Tensor):
parameters = [parameters]
clip_value = float(clip_value)
for p in filter(lambda p: p.grad is not None, parameters):
p.grad.data[(p.grad.data>=0) & (p.grad.data<threshold)] = threshold
p.grad.data[(p.grad.data<=0) & (p.grad.data>-threshold)] = -threshold
#下面一句放到训练代码loss.backward()后
clear_small_grad_value_(model.parameters(), threshold=1e-10)
试验失败。发现网络变的无法训练,分析其原因是:梯度往往呈现一种均值在0左右的正态分布,也就是说多数参数在0附近,少数较大,因此改变大的参数值不会影响模型优化的大方向,仍可逐渐训练,但改变0附近的值将改变多数参数,会导致梯度不再指向优化的正确方向,导致模型无法训练。
3.加入BN层
给增加模块的每个卷积层后面再加上BN层,它可以使每层输出的数据保持到固定的均值和标准差,这样会避免数值过小或过大,梯度也就会比较规范,因此可以避免梯度消失或爆炸。但BN层并不能直接控制梯度的大小,仍有一定概率使某些层出现梯度过小或过大,过多层累积后仍有可能梯度消失或爆炸。试验效果如下(图略):
(1)模块数60以下,解决梯度消失或爆炸;
(2)模块数60以上,发生梯度消失或爆炸。
4.加入ResNet的shortcut连接
试验发现,加入shortcut之后完全解决了梯度消失现象,甚至增加模块数达到1000时(这时加上原来LeNet的5层总共有2005层!)仍然能够正常训练而没有发生梯度消失现象。这是因为shortcut提供了恒等映射,保证梯度有一条通路可以不经衰减或增强直接从末层到首层,所以不会出现梯度消失或爆炸现象。
我们也许会产生一个担心,shortcut提供了一种短路连接,使得反向传播时梯度可以不经卷积层而直接恒等映射,那这个短路连接会不会使得正向传播时数据流也被短路,卷积层实际上也失效了呢?我们通过试验分析这个问题。
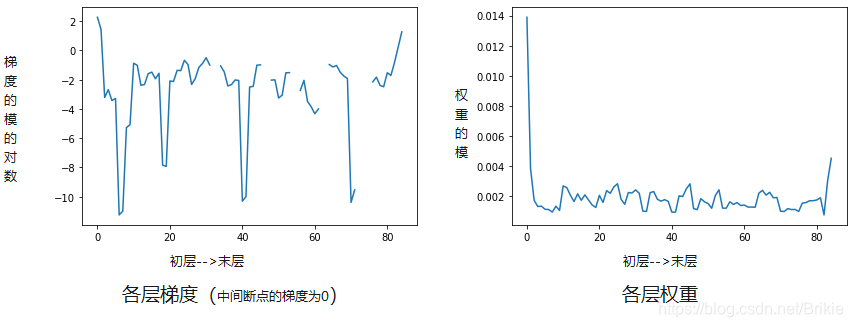
以插入40个模块为例,这时共有85层,训练10个epoch后,画出各层的权重和权重的梯度如上图。发现,确实有一些层的梯度已经为0或者非常小,但这些层的梯度并没有影响其他层,也就是说梯度为0的层在反向传播时被短路了,0梯度没有扩散造成梯度消失。但是各层的权重仍然是正常的,没有出现权重为0的情况,所以正向传播时数据流并不会被短路,各层都能发挥作用。正向传播走的是各层权重,反向传播走的是各层权重的梯度,shortcut只是在梯度上呈现短路效果,正向传播走权重不短路。反而正向传播时shortcut还能起到多路并联的效果,相当于集成学习,所以效果更好了。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









