







删除列
df.drop(labels=[“列名1”, “列名2”], axis=1, inplace=True)
df.drop(df.columns[[0, 1,2,3,4,5,6,7,8,9,10]], axis=1, inplace=True)
第二种删除列的方式需要注意的是,如果你读取的是csv或者excel,且指定了index_col=0,即第一列为索引列,则df.columns[[0]]则为实际的第二列
- 只要某些列
df = df.loc[(pd.isnull(df[" CompanyNumber"]) == False), [" CompanyNumber", “IncorporationDate”, “Accounts.NextDueDate”]]
- 将列的某些值进行替换
df[“CompanyStatus”].replace(“Active”, “postive”, inplace=True)
- 某字段的值为null或者空字符则不要
df = df.fillna(“”)
df = df[df[‘DISTRIBUTOR_NAME’].apply(lambda x: x.strip())!=‘’]
- 将指定列包含指定内容的数据保留
df(df[“SICCode.SicText_1”].str.contains(“47749 -|5232 -”))
- assign函数
将两列数据拼接,并生成新的一列 Adress
df = df.assign(Address=lambda x:x[‘RegAddress.Country’] + " | " + x[‘RegAddress.County’])
- apply函数
## 这里的apply是对DataFrame进行操作,因此进入匿名函数的x是DataFrame的每行数据,类型为Series
df.loc[:,"xxx"] = df.apply(lambda x:print(type(x))
## 这里的df.loc[:,"xxx"]是Series 类型的数据, 因此每次进入匿名函数的x是该列的具体数据
df["xxx"] = df.loc[:, "xxx"].apply(lambda x:print(type(x))
- 条件筛选
df.loc[df[‘高温’]-df[‘低温’]>=15,‘type’] = ‘高温差’
df.loc[df[‘高温’]-df[‘低温’]<15,‘type’] = ‘低温差’
- 更改列名
df.rename(columns={“CompanyName”: “title”}, inplace=True)
df.rename(columns={" CompanyNumber": “DISTRIBUTOR_ID”}, inplace=True)
- 分组聚合(groupby)
# 可以实现对dataframe的company列进行分组,然后得到几个分组后的df,再对salary列进行取平均值,然后赋值给avg_salary列
data['avg_salary'] = data.groupby('company')['salary'].transform('mean')
访问指定行列的几种方法
pandas加载的对象的Dataframe类型对象,即多行多列
当通过for循环 df.iterrows(),得到每行rows,这个rows为Series类型对象, Series类型对象[‘列名’]就是那个单元格的数据
注意:
一列多行,和一行多列数据都是 Series类型对象
loc
df可以通过loc来获取行区间的数据
df.loc[1]: df.loc[1] 获取第一行数据,为 Series类型对象,因此可以通过 df.loc[1, ‘列名’] 来查看指定行列的数据
df.loc[:2]:df.loc[:2]为 0到1行的数据,为 DataFrame对象, 可以通过 df.loc[:2, ‘列名’] 来查看前两行指定列的数据
注意:
loc和iloc的用法差不多,只是 loc指定列的方式列名放在[]里面 例如:
df.loc[:1,“车次”] ,而iloc为 df.loc[:1][“车次”]
at
df.at[1, '列名] 与 df.loc[1, ‘列名’] 一样都能查看指定行列的数据,并且也支持赋值操作,可更改掉原df内数据
iloc
iloc可以用来获取区域行的数据
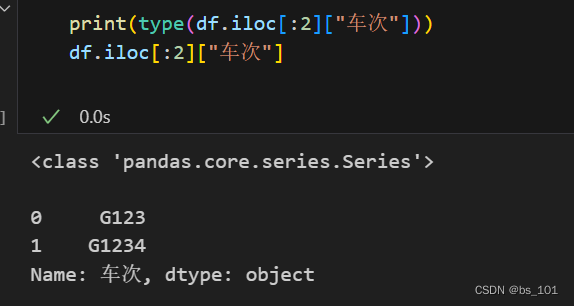
df.iloc[:2]获取前两行的数据,df.iloc[:2][“车次”]获取前两行并且列为 ”车次“的数据
注意:df.iloc[:2]还是DataFrame类型, df.iloc[:2][“车次”]是Series类型数据
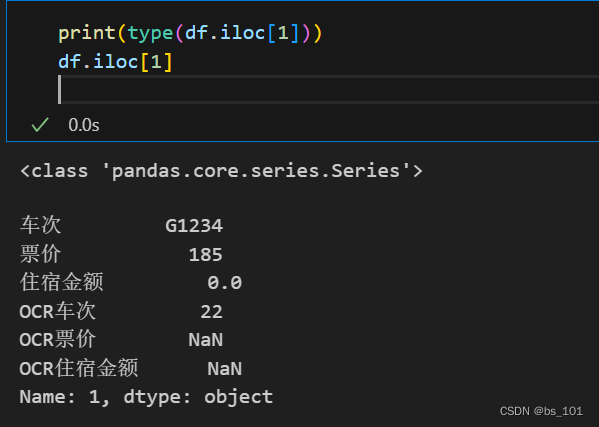
df.iloc[1]为获取第二行的数据,类型为Series















 2414
2414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









