






编码生成规则:第一级001-999,第二级在上一级基础上继续加3位
1. 数据库悲观锁来控制生成组织机构编码
首先需要初始化虚节点:id=0的节点,用来给顶层节点生成编码的时候加行锁
/**
* 统一生成编码(支持顶层和子节点)
* @param parentCode 父节点编码(传 null 表示生成顶层节点)
* @return 新生成的编码(如 "001" 或 "001001")
*/
@Transactional(rollbackFor = Exception.class)
public String generateCode(String parentCode) {
if (parentCode == null) {
return generateTopLevelCode();
} else {
return generateChildCode(parentCode);
}
}
// 生成顶层节点编码(如 "001")
private String generateTopLevelCode() {
// 1. 锁定虚拟记录(id=0)
SysDept lockRecord = baseMapper.selectOne(
new LambdaQueryWrapper<SysDept>()
.eq(SysDept::getId, "0")
.last("FOR UPDATE")
);
if (lockRecord == null) {
throw new RuntimeException("虚拟锁记录未初始化");
}
// 2. 查询当前最大顶层编码
String maxCode = baseMapper.selectMaxChildCode(null,"top");
// 3. 计算下一个编码
String nextCode;
if (maxCode == null) {
nextCode = "001"; // 第一个顶层节点
} else {
int currentMax = Integer.parseInt(maxCode);
if (currentMax >= 999) {
throw new RuntimeException("顶层节点数量已达最大值 999");
}
nextCode = String.format("%03d", currentMax + 1);
}
return nextCode;
}
// 生成子节点编码(如 "001001")
private String generateChildCode(String parentCode) {
// 1. 查询父节点并加锁
SysDept parent = baseMapper.selectOne(
new LambdaQueryWrapper<SysDept>()
.eq(SysDept::getDeptCode, parentCode)
.last("FOR UPDATE")
);
if (parent == null) {
throw new RuntimeException("父节点不存在: " + parentCode);
}
// 2. 查询当前父节点的最大子编码
String maxChildCode = baseMapper.selectMaxChildCode(parent.getId(),"child");
// 3. 计算下一个子编码
String nextCode;
if (maxChildCode == null) {
nextCode = parent.getDeptCode() + "001"; // 第一个子节点
} else {
String suffix = maxChildCode.substring(maxChildCode.length() - 3);
int nextNumber = Integer.parseInt(suffix) + 1;
if (nextNumber > 999) {
throw new RuntimeException("子节点数量已达最大值 999");
}
nextCode = parent.getDeptCode() + String.format("%03d", nextNumber);
}
return nextCode;
}
// mapper接口
/**
* 查询当前最大编码
*/
@Select("SELECT MAX(dept_code) FROM sys_dept WHERE (parent_id IS NULL AND #{type} = 'top') OR (parent_id = #{parentId} AND #{type} = 'child')")
String selectMaxChildCode(@Param("parentId") String parentId, @Param("type") String type);
2. 可能的问题和方案:
问题1:
子节点生成中,使用了SELECT FOR UPDATE来锁定父节点记录,以确保同一时间只有一个事务能处理该父节点的子节点。对于顶层节点,可能需要类似的机制,但由于没有父节点,需要锁定整个表或某个特定的虚拟记录。不过,锁定整个表会影响性能,特别是高并发时。
解决方案是,当生成顶层节点时,锁定一个特定的记录或使用某种数据库锁机制。例如,可以创建一个虚拟的父节点记录,代表顶层节点的父节点
这样,生成顶层节点的步骤可能如下:
锁定虚拟记录(id=0)。
查询当前最大的顶层节点编码。
生成新编码(当前最大+1,格式化为两位数)。
插入新记录,parent_id为null。
提交事务,释放锁。

问题2:
为什么不用synchronized锁
原因:

导致事务提交顺序不可控:
线程A获取锁 → 插入记录(事务未提交) → 释放锁 → 事务提交前,线程B获取锁并读取到旧的最大值。
结果:生成重复编码。
分布式部署失效:
两个服务实例同时运行,synchronized 无法跨 JVM 协调。
问题3:
为什么没有看到显式的插入删除修改操作,生成编码的方法还需要加@Transactional注解?
原因:
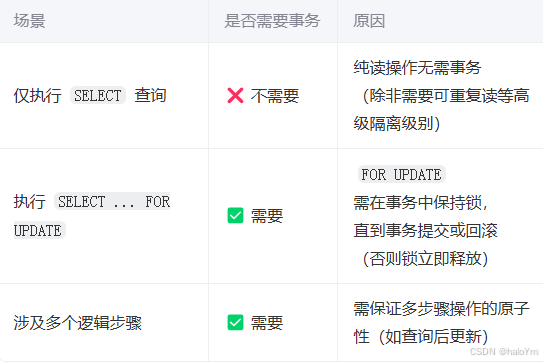
selectOne使用了FOR UPDATE来锁定记录,这属于数据库的写操作(排他锁),因此即使没有插入数据,这个锁定操作本身也需要在事务中执行,否则锁定会在查询后立即释放,无法保持到事务结束
即使没有插入操作,但如果有其他的写操作(如SELECT … FOR UPDATE),事务仍然是必要的,因为FOR UPDATE需要在事务中才能保持锁定直到事务提交或回滚。如果去除了所有的写操作,只剩下读操作,那么事务可能不需要,除非需要可重复读的隔离级别。
问题4
什么时候使用部门id,什么时候使用部门编码
部门id使用场景:
1. 核心业务表关联
场景:员工表、审批流程表、权限配置表等需要长期稳定关联部门的场景。
理由:部门ID永不变化,即使部门被重命名、调整层级或修改编码,业务数据仍有效。
示例:
2. 高频读写操作
场景:订单分部门统计、实时权限校验等需要快速通过ID定位部门的场景。
理由:数字ID的索引查询效率高于字符串编码(如A.01.001)。
部门编码使用场景:
1. 人工可读的展示与报表
场景:导出Excel报表、邮件通知、系统界面展示部门层级。
理由:编码包含业务语义(如HR.001表示人力资源部),比纯数字ID更易理解。
-- 通过ID关联部门表,动态替换为编码或名称
SELECT
e.name AS employee_name,
d.dept_code -- ✅ 展示时使用编码
FROM employee e
JOIN sys_dept d ON e.dept_id = d.id;
2. 与外部系统交互
场景:向第三方系统(如ERP、税务系统)传输部门数据。
理由:外部系统可能依赖固定编码规则,而非内部ID。
3. 简化人工操作
场景:在搜索框输入编码前缀快速过滤部门(如输入IT匹配IT.01, IT.02)。
SELECT * FROM sys_dept WHERE dept_code LIKE 'IT.%';
误区:在权限配置中直接使用部门编码(如code=‘IT.01’)。
风险:编码变更后权限规则失效!
修正:始终用部门ID配置权限,通过编码查询ID再绑定。
误区:在数据库中强制编码包含层级(如A.01.001)。
风险:层级调整需全量更新编码,引发数据混乱。
修正:编码仅作为标签,层级关系通过parent_id动态管理。
终极原则
数据库设计:所有关联用ID,编码仅作为普通字段。
业务逻辑:内部处理用ID,对外交互用编码。
展示层:按需将ID映射为编码或名称,但源头永远保留ID
3. 优化方向
性能影响:高频并发场景下,串行化操作可能成为瓶颈,可通过以下方式优化:
Redis 分布式锁: 将锁机制迁移到 Redis 减少数据库压力。
批量预生成: 预先生成一批编码缓存到内存或 Redis。

















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









