






 本文详细介绍了SpringCloud中的服务注册中心(Eureka、Zookeeper、Consul、Nacos)及其区别,重点讲解了Eureka的自我保护机制、服务调用、服务降级(Hystrix、Sentinel)、服务网关(Gateway)和分布式事务管理(Seata)。
本文详细介绍了SpringCloud中的服务注册中心(Eureka、Zookeeper、Consul、Nacos)及其区别,重点讲解了Eureka的自我保护机制、服务调用、服务降级(Hystrix、Sentinel)、服务网关(Gateway)和分布式事务管理(Seata)。
根据这两个总结,具体的细节还是在这个
SpringCloud主要由以下几个部分组成:
- 服务注册中心:× Eureka,√ Zookeeper,√ Consul,√ Nacos
- 负载均衡√ Ribbon,√ LoadBalancer
- 服务调用× Feign,√ OpenFeign
- 服务降级× Hystrix,√ resilience4j,√ sentienl
- 服务网关× Zuul,! Zuul2,√ gateway
- 配置中心管理× Config,√ Nacos
- 服务监控× Bus,√ Nacos
服务注册中心
三个注册中心异同点
| 组件名 | 语言CAP | 服务健康检查 | 对外暴露接口 | Spring Cloud集成 |
| Eureka | Java | AP | 可配支持 | HTTP |
| Consul | Go | CP | 支持 | HTTP/DNS |
| Zookeeper | Java | CP | 支持客户端 | 已集成 |
Eureka
Eureka包含两个组件:Eureka Server和Eureka Client,Server把信息注册到注册中心,Client从注册中心获取数据调用服务端服务;
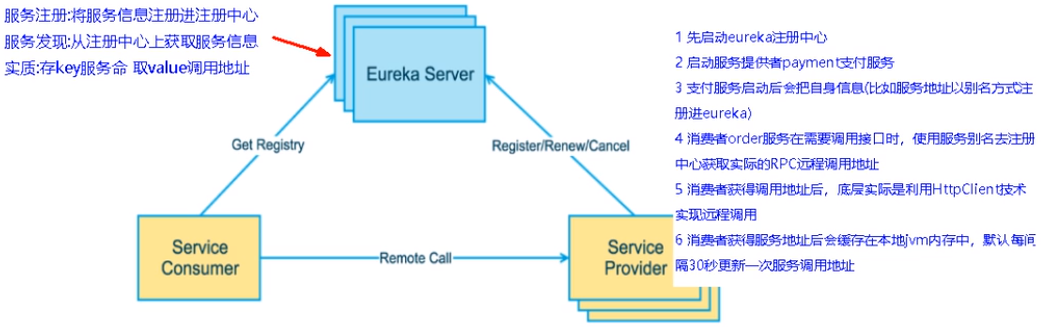
1先启动eureka注主册中心
2启动服务提供者payment支付服务
3支付服务启动后会把自身信息(比服务地址L以别名方式注朋进eureka
4消费者order服务在需要调用接口时,使用服务别名去注册中心获取实际的RPC远程调用地址
5消去者导调用地址后,底屋实际是利用HttpClient技术实现远程调用
6消费者实癸导服务地址后会缓存在本地jvm内存中,默认每间隔30秒更新—次服务调用地址
为什么会产生Eureka自我保护机制
为了EurekaClient可以正常运行,防止与EurekaServer网络不通情况下,EurekaServer不会立刻将EurekaClient服务剔除
什么是自我保护模式
默认情况下,如果EurekaServer在一定时间内没有接收到某个微服务实例的心跳,EurekaServer将会注销该实例(默认90秒)。但是当网络分区故障发生(延时、卡顿、拥挤)时,微服务与EurekaServer之间无法正常通信,以上行为可能变得非常危险了——因为微服务本身其实是健康的,此时本不应该注销这个微服务。Eureka通过“自我保护模式”来解决这个问题——当EurekaServer节点在短时间内丢失过多客户端时(可能发生了网络分区故障),那么这个节点就会进入自我保护模式。
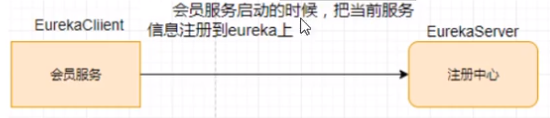
自我保护机制∶默认情况下EurekaClient定时向EurekaServer端发送心跳包
如果Eureka在server端在一定时间内(默认90秒)没有收到EurekaClient发送心跳包,便会直接从服务注册列表中剔除该服务,但是在短时间( 90秒中)内丢失了大量的服务实例心跳,这时候Eurekaserver会开启自我保护机制,不会剔除该服务(该现象可能出现在如果网络不通但是EurekaClient为出现宕机,此时如果换做别的注册中心如果一定时间内没有收到心跳会将剔除该服务,这样就出现了严重失误,因为客户端还能正常发送心跳,只是网络延迟问题,而保护机制是为了解决此问题而产生的)。
Zookeeper
用法主要是@EnableDiscoveryClient和配置文件
Consul
用法主要是@EnableDiscoveryClient和配置文件
Nacos
nacos可以作为注册中心和配置管理,支持CP也支持AP,默认AP,
Nacos中的治理模式可以通过命名空间(namespace)、分组(group)和服务/数据ID(service/data-id)
命名空间(namespace)是Nacos中的一个隔离单元,用于将服务实例和配置信息进行隔离。
分组(group)是对相同服务的实例进行分类和管理。
服务/数据ID(service/data-id)是在Nacos中用于标识一个具体的服务或配置信息的唯一标识符。
当服务上线时,nacos有两种方式告知消费者,一种是主动通知,一种是消费者定时主动向注册中心获取,nacos默认的是第一种,当服务上线时,nacos获取到实例会通过NotifyCenter这个类通过事件通知订阅者
nacos心跳是客户端通过定时不断的调用服务端的接口,保证客户端有服务端能正常连接,保证客户端在线或下线状态
${spring.application.name)}-${spring.profiles.active}.${spring.cloud.nacos.config.file-extension}
DataID:nacos-config-client-dev.yaml
spring.application.name: nacos-config-client
spring. profiles.active: dev # 表示开发环境
spring.cloud.nacos.config.file-extension: yaml #指定yaml格式的配置
负载均衡
可以通过IRule换负载均衡,也可以通过LoadBalancer接口重新写负载均衡算法(@RibbonClient(name = "CLOUD-PAYMENT-SERVICE", configuration = MySelfRule.class))
- RoundRobinRule 轮询
- RandomRule 随机
- RetryRule 先按照RoundRobinRule的策略获取服务,如果获取服务失败则在指定时间内会进行重
- WeightedResponseTimeRule权重
- BestAvailableRule 会先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后选择一个并发量最小的服务
- AvailabilityFilteringRule 先过滤掉故障实例,再选择并发较小的实例
- ZoneAvoidanceRule 默认规则,复合判断server所在区域的性能和server的可用性选择服务器
集中式LB(nginx)
进程内LB(Ribbon)
服务调用
OpenFeign
OpenFeign的@Feignclient可以解析SpringMvc的@RequestMapping注解下的接口,并通过动态代理的方式产生实现类,实现类中做负载均衡并调用其他服务。
服务降级
Hystrix
@EnableHystrix
@HystrixCommand(fallbackMethod = "paymentTimeOutFallbackMethod",commandProperties = {
@HystrixProperty(name="execution.isolation.thread.timeoutInMilliseconds",value="1500")})
Hystrix会监控微服务间调用的状况,当失败的调用到一定阈值,缺省是5秒内20次调用失败,就会启动熔断机制。熔断机制的注解是@HystrixCommand。
sentienl
限流(通过控制qps和线程数)
降级(降级策略RT(平均响应时间),异常数,异常比例)
默认懒加载,要访问一次
流控规则
QPS:控制每秒多少访问量
线程数失败
关联a关联b,b失败了,对导致a失败如支付接口失败,导致下单接口失败
warmup预热,假如设置QPS为10,时间为5秒钟,在前5秒如果每秒QPS达到3以上就会失败,到了5秒后,就可以正常访问了,防止流量一下子暴增,预留因子是3在warmupcontrller这个类
服务降级
rt平均相应,当一秒钟5个相应平均值大于rt,那么接下来的时间窗口服务降级
异常比例,每秒大于5条且比例大于异常比例,那么就在异常窗口服务降级
异常数,当异常数在一分钟内异常数,服务熔断开启
热点key只处理QPS
@SentinelResource和HystrixCommand功能一样
blockHandler处理降级方法
blockHandlerClass用于自定义类
fallback运行时异常
blockHandler是sentinel配置异常
若blockHandler和fallback 都进行了配置,则被限流降级而抛出BlockException时只会进入blockHandler处理逻辑。
服务网关
Gateway(网关)
安全、监控/埋点和限流等等。 它是基于Netty的响应式开发模式。
Route(路由)
路由是构建网关的基本模块,它由ID,目标URI,一系列的断言和过滤器组成,如断言为true则匹配该路由;
Predicate(断言)
参考的是Java8的java.util.function.Predicate,开发人员可以匹配HTTP请求中的所有内容(例如请求头或请求参数),如果请求与断言相匹配则进行路由;
Filter(过滤)
指的是Spring框架中GatewayFilter的实例,使用过滤器,可以在请求被路由前或者之后对请求进行修改。
Config
它主要关注应用程序的配置管理。通过将配置信息存储在外部存储库(如 Git、SVN、本地文件系统等)中,Spring Cloud Config 允许应用程序动态地获取配置。这样,你可以在不重新部署应用程序的情况下,修改配置并使其生效。Spring Cloud Config 还提供了配置文件的分隔、继承和环境特定性等功能,使配置管理更加灵活。
Nacos
nacos可以作为注册中心和配置管理,支持CP也支持AP,默认AP,
Nacos中的治理模式可以通过命名空间(namespace)、分组(group)和服务/数据ID(service/data-id)
命名空间(namespace)是Nacos中的一个隔离单元,用于将服务实例和配置信息进行隔离。
分组(group)是对相同服务的实例进行分类和管理。
服务/数据ID(service/data-id)是在Nacos中用于标识一个具体的服务或配置信息的唯一标识符。
当服务上线时,nacos有两种方式告知消费者,一种是主动通知,一种是消费者定时主动向注册中心获取,nacos默认的是第一种,当服务上线时,nacos获取到实例会通过NotifyCenter这个类通过事件通知订阅者
nacos心跳是客户端通过定时不断的调用服务端的接口,保证客户端有服务端能正常连接,保证客户端在线或下线状态
${spring.application.name)}-${spring.profiles.active}.${spring.cloud.nacos.config.file-extension}
DataID:nacos-config-client-dev.yaml
spring.application.name: nacos-config-client
spring. profiles.active: dev # 表示开发环境
spring.cloud.nacos.config.file-extension: yaml #指定yaml格式的配置
服务监控
Bus
它是一个事件、消息传递系统,用于在分布式系统中传播状态变化。尽管其中一个用例是用于配置刷新,但它的范围更广。通过 Spring Cloud Bus,你可以发送消息来触发多个服务的配置刷新,这对于一次性刷新多个服务的配置非常有用。它还可以用于在微服务架构中传播其他类型的事件,如通知、广播等。
Nacos
nacos可以作为注册中心和配置管理,支持CP也支持AP,默认AP,
Nacos中的治理模式可以通过命名空间(namespace)、分组(group)和服务/数据ID(service/data-id)
命名空间(namespace)是Nacos中的一个隔离单元,用于将服务实例和配置信息进行隔离。
分组(group)是对相同服务的实例进行分类和管理。
服务/数据ID(service/data-id)是在Nacos中用于标识一个具体的服务或配置信息的唯一标识符。
当服务上线时,nacos有两种方式告知消费者,一种是主动通知,一种是消费者定时主动向注册中心获取,nacos默认的是第一种,当服务上线时,nacos获取到实例会通过NotifyCenter这个类通过事件通知订阅者
nacos心跳是客户端通过定时不断的调用服务端的接口,保证客户端有服务端能正常连接,保证客户端在线或下线状态
${spring.application.name)}-${spring.profiles.active}.${spring.cloud.nacos.config.file-extension}
DataID:nacos-config-client-dev.yaml
spring.application.name: nacos-config-client
spring. profiles.active: dev # 表示开发环境
spring.cloud.nacos.config.file-extension: yaml #指定yaml格式的配置
Seata
Seata之原理简介
2019年1月份蚂蚁金服和阿里巴巴共同开源的分布式事务解决方案。
Simple Extensible Autonomous Transaction Architecture,简单可扩展自治事务框架。
2020起始,用1.0以后的版本。Alina Gingertail
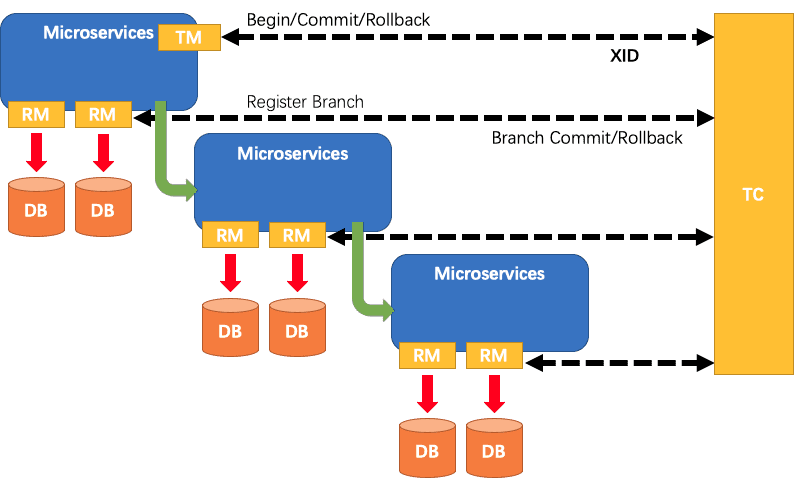
分布式事务的执行流程
- TM开启分布式事务(TM向TC注册全局事务记录) ;
- 按业务场景,编排数据库、服务等事务内资源(RM向TC汇报资源准备状态) ;
- TM结束分布式事务,事务一阶段结束(TM通知TC提交/回滚分布式事务) ;
- TC汇总事务信息,决定分布式事务是提交还是回滚;
- TC通知所有RM提交/回滚资源,事务二阶段结束。
- AT模式如何做到对业务的无侵入
是什么
前提
- 基于支持本地 ACID 事务的关系型数据库。
- Java 应用,通过 JDBC 访问数据库。
整体机制
两阶段提交协议的演变:
- 一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
- 二阶段:
-
- 提交异步化,非常快速地完成。
- 回滚通过一阶段的回滚日志进行反向补偿。
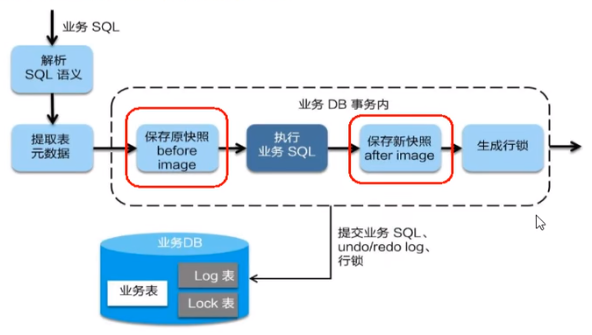
一阶段加载
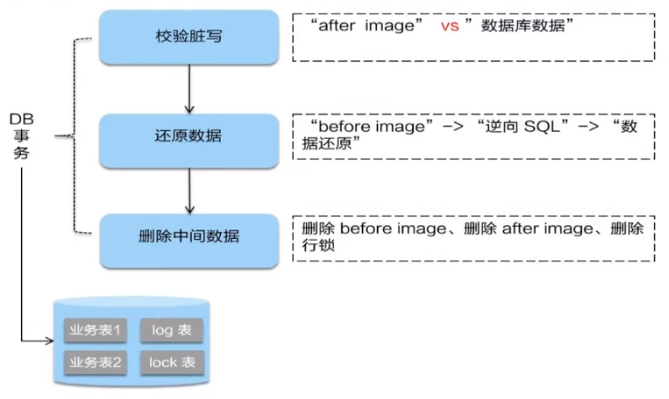
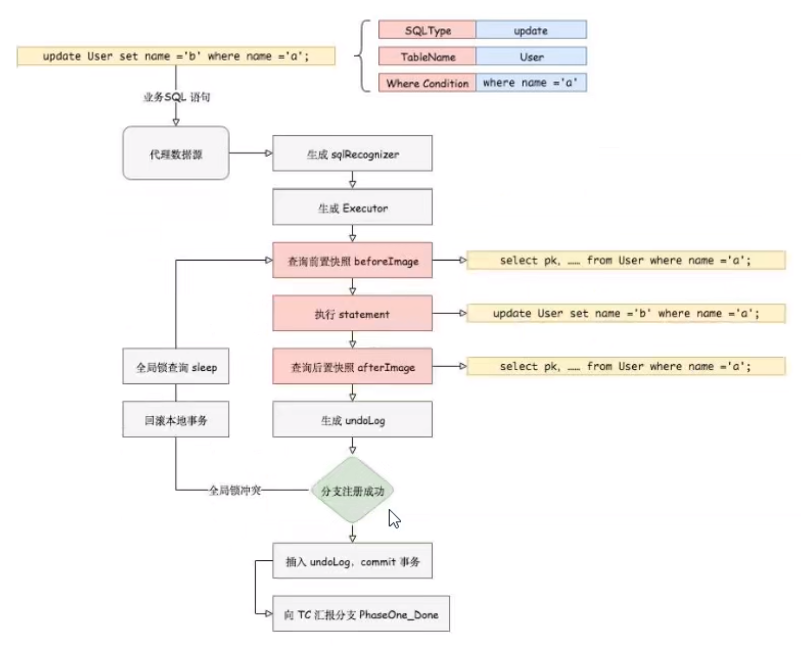
在一阶段,Seata会拦截“业务SQL”
解析SQL语义,找到“业务SQL" 要更新的业务数据,在业务数据被更新前,将其保存成"before image”
执行“业务SQL" 更新业务数据,在业务数据更新之后,
其保存成"after image”,最后生成行锁。
以上操作全部在一个数据库事务内完成, 这样保证了一阶段操作的原子性。
- 二阶段提交
二阶段如果顺利提交的话,因为"业务SQL"在一阶段已经提交至数据库,所以Seata框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。
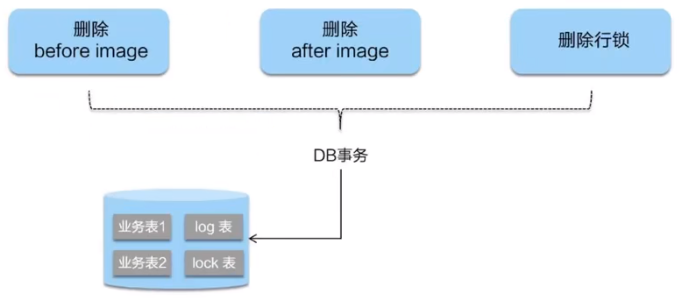
二阶段回滚
二阶段如果是回滚的话,Seata 就需要回滚一阶段已经执行的 “业务SQL",还原业务数据。
回滚方式便是用"before image"还原业务数据;但在还原前要首先要校验脏写,对比“数据库当前业务数据”和"after image"。
如果两份数据完全一致就说明没有脏写, 可以还原业务数据,如果不一致就说明有脏写, 出现脏写就需要转人工处理。
雪花算法
结构
雪花算法的几个核心组成部分:

号段解析:
















 260
260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









