






刚开始接触深度学习、卷积神经网络的时候非常懵逼,不知道从何入手,我觉得应该有一个进阶的过程,也就是说,理应有一些基本概念作为奠基石,让你有底气去完全理解一个庞大的卷积神经网络:
本文思路:

一、我认为学习卷积神经网络必须知道的几个概念:
1、卷积过程:
我们经常说卷积神经网络卷积神经网络,到底什么才是卷积?网络层卷积过程到底怎么实现?我们在这里借鉴了另一位博客大牛的动态图来给大家演示一下,
图作者文章在此:http://blog.csdn.net/silence1214/article/details/11809947
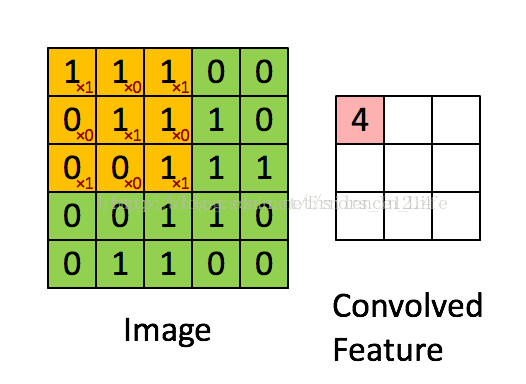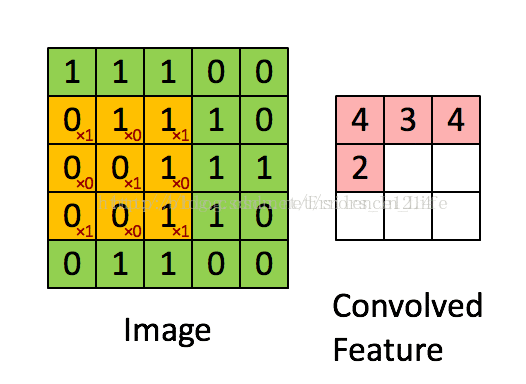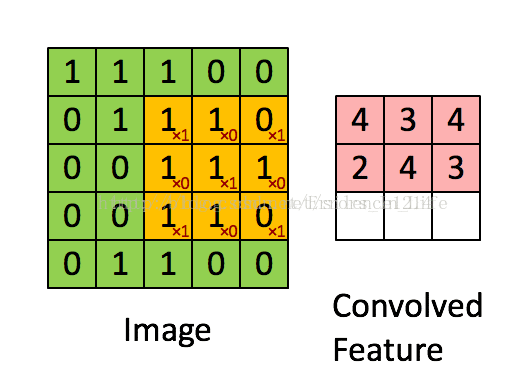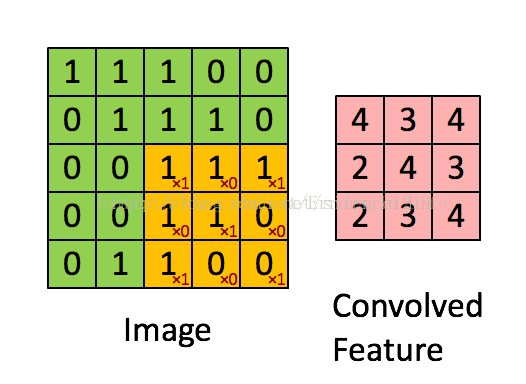
我们可以看到,卷积过程其实还是基于一个固定的矩阵,在另外一个矩阵不断一格一格扫过去的到的数值的和,(注意:这里的一格一格非常重要,因为涉及后面的概念:步长→我们不妨想一想当固定矩阵不是一格一格前进的时候,会发生什么呢?)产生的一个新的矩阵,我们以作为比较会发现:粉红色矩阵和绿色矩阵在根本上有很大不一样,
第一,卷积之后的维数降低了;第二,我们要想想为什么降维了?(思考:降低维度到底有没有规律?)
答案是有的:我们发现橙色的固定框为3*3,绿色是5*5,出来是三乘三;
所以规律可以得到:粉红色最后的卷积结果矩阵维度=绿色矩阵维数-橙色矩阵维数+1
(我们又应该思考:如果我不想最后减少维度,我只希望卷积,怎么办呢?)
2、两层之间的池化:
我们依然延用博客大牛的另一个动图(再次点赞做的精细准确!)
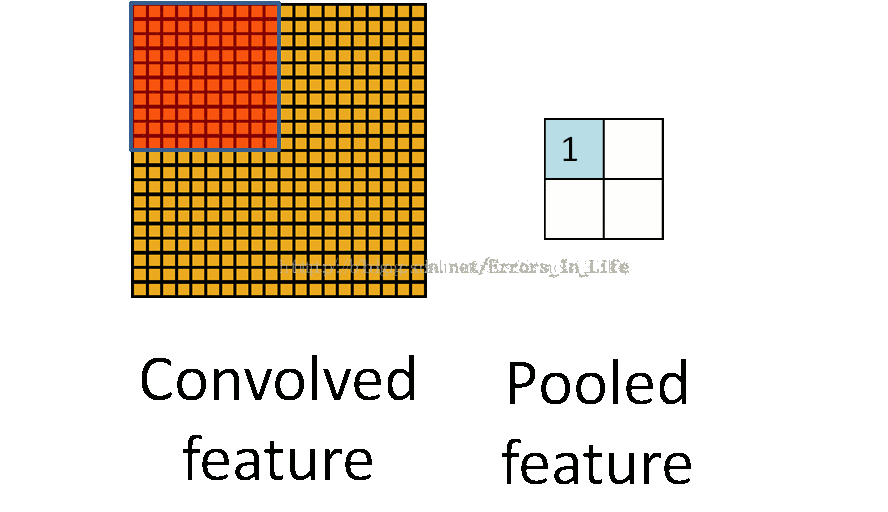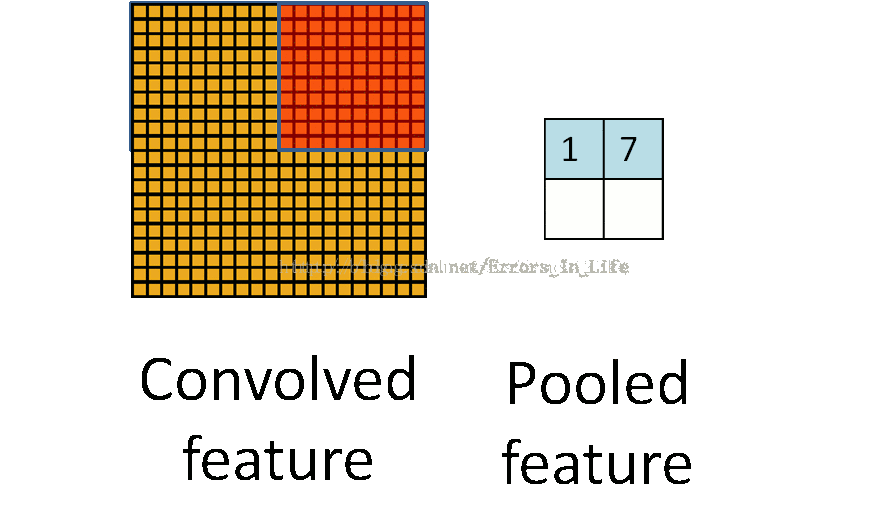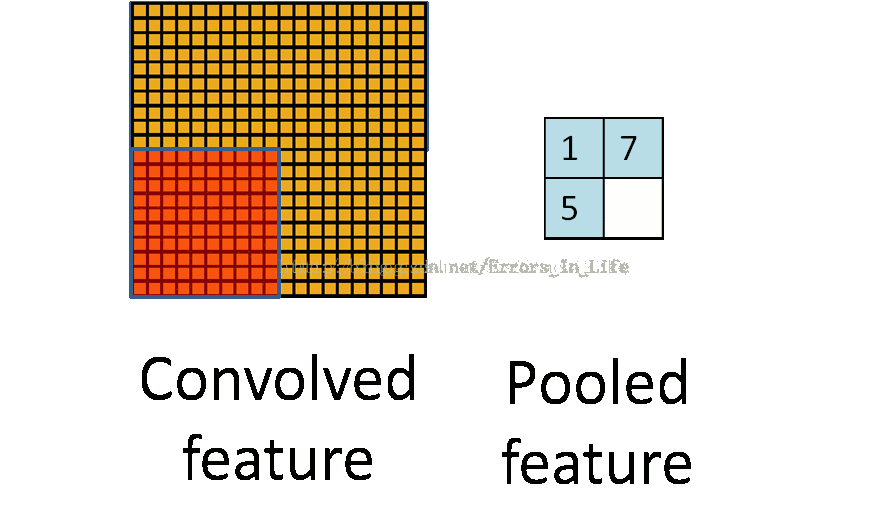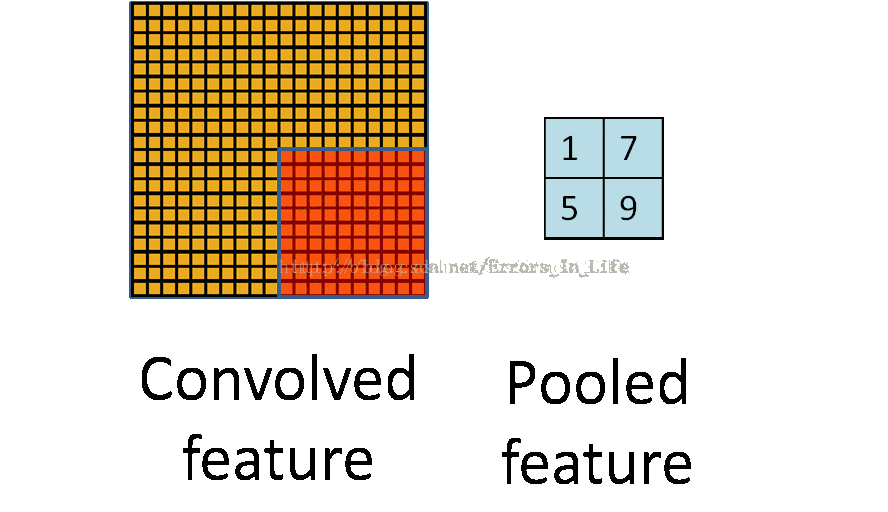
我们可以发现其实跟之前没什么不一样:还是以三个矩阵之间的运算,但是我们很容易发现,它并不是一行一行扫过去的,橙色矩阵维度是黄色矩阵的整数倍,所以池化的最终的结论是要把原来的维度减少到1/n.这是池化最根本的原理(当然也有特殊情况。)
(思考点:我们想象一下如果一个19*19的矩阵做池化,会是一种什么样的体验呢?我们不可以缩小整数倍!!答案会在后面的VGG16里面讲清楚,不急不急 )
)
3、第三个知识点是步长的概念:
卷积核(后面讲到VGG16会介绍)移动的步长(stride)小于卷积核的边长(一般为正方行)时,变会出现卷积核与原始输入矩阵作用范围在区域上的重叠(overlap),卷积核移动的步长(stride)与卷积核的边长相一致时,不会出现重叠现象。
通俗一点其实就是:刚刚说的那个粉红色矩阵,他每一次移动多少格,格子就是步长!!
4、卷积核:
一个听起来很高大上的词语,我们依然用之前的基础来解释:通俗易懂:就是粉红色矩阵的个数!!因为有时候我们要提取的特征非常多非常广泛,所以需要我们用更多的矩阵来扫(多扫几遍),那么粉红色矩阵的个数就是卷积核个数。
5、Padding:
这个应该是最抽象的概念了:但是也不会特别难呢,就是我们在之前讲到第一点:卷积的时候,我抛下了一个问题:
(我们又应该思考:如果我不想最后减少维度,我只希望卷积,怎么办呢?)(现在知道括号的重要性了吧哈哈? )
)
现在我们来解决这个问题:比如:我们需要做一个300*300的原始矩阵,用一个3*3卷积核(粉红色矩阵)来扫,扫出来,按照之前公式,结果的矩阵应该是:298*298的矩阵,但是这样很难计算,减得也不多,反而增加我计算难度,还不如池化(pooling)来得干脆是吧!那我们就在300*300矩阵外面周围加一圈“0”,记住,是在外面外包一层“0”
重点是:这样的300*300就变成了302*302的矩阵,这样就可以完全避开卷积后那两层的抵消。
6、还有一个就是通道的概念:这个不算知识点,仅仅是一个常识词语,比如一张图片,有RGB三种颜色,对应三个灰度级别,也就是三个通道了:
更加抽象的图可以参照下面的结构:
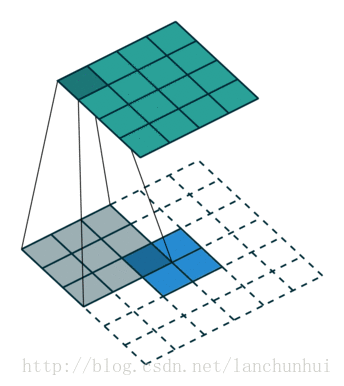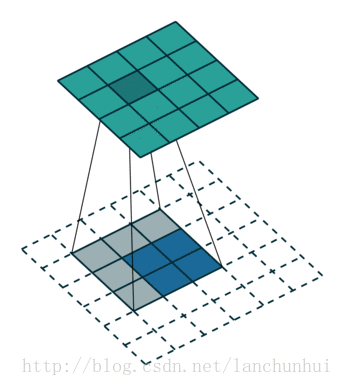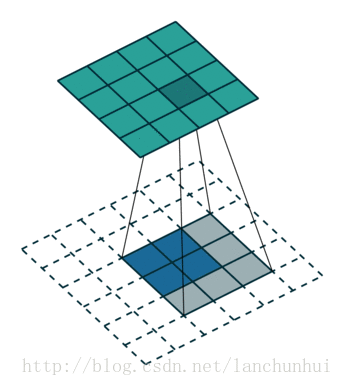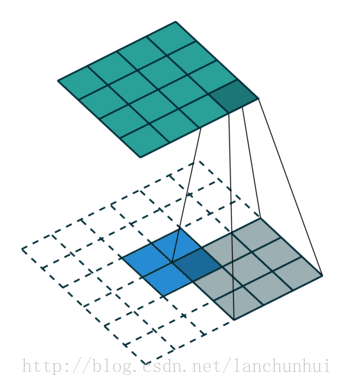
二、等待已久的VGG16:
VGG16分为16层,我们主要讲前面的前几层(越详细越好吧,后面是一样的)
——首先教会大家一个看其他神经网络也是用的办法:官方数据表格:
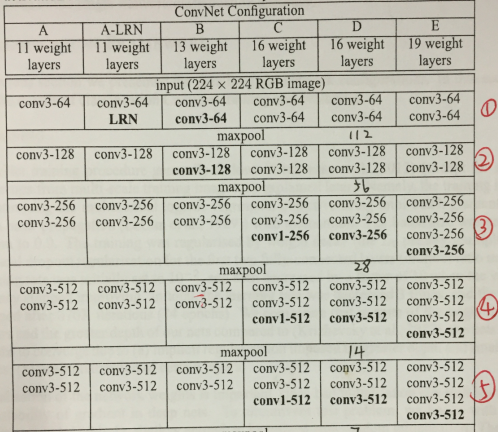
看懂一些式子表达:
Conv3-512 → 第三层卷积后维度变成512;
Conv3_2 s=2 → 第三层卷积层里面的第二子层,滑动步长等于2(每次移动两个格子)
好了,我们有了以上的知识可以考试剖析VGG16卷积神经网络了
三、利用之前的基本概念来解释深层的VGG16卷及网络;
【1、从INPUT到Conv1:】
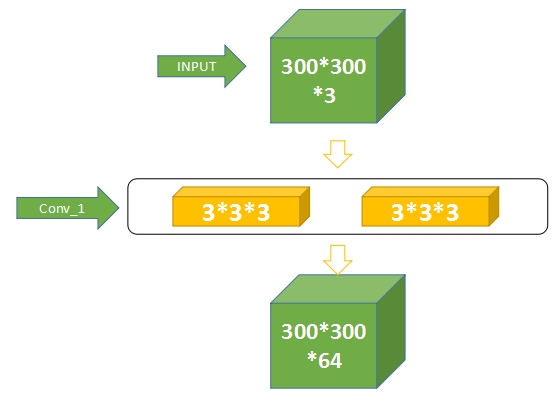
首先两个黄色的是卷积层,是VGG16网络结构十六层当中的第一层(Conv1_1)和第二层(Conv1_2),他们合称为Conv1。
我们主要讲述第一个,也就是第一层(Conv1_1),它怎么把一个300*300*3的矩阵变成一个300*300*64的矩阵?
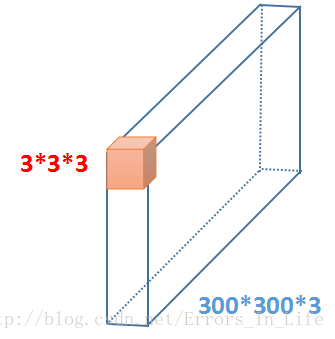
我们假设蓝色框是一个RGB图像,橙色是一个3*3*3的卷积核,我们对一个三维的27个数求和,然后扫过去,按照第一部分算的得出来的是一维的298*298的矩阵(因为卷积核也是三维所以结果是一维);
然后回想一下什么是Padding、前面也讲过它的概念了;所以不了一圈的圆,回到了300*300*1;
然后,VGG16这一层安置有64个卷积核,那么,原来的300*300*1变成300*300*64
于是我们的到了想要的东西;最后的绿色框;
【1、从Conv1到Conv2之间的过度:】
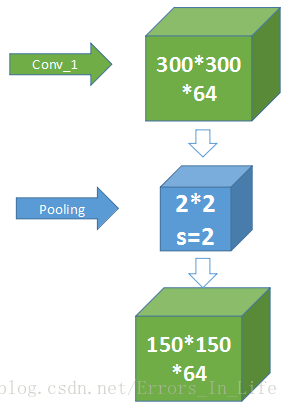
这一步用的Pooling是:2*2*64 s=2;
也就是说,步长是二,滑动的矩阵本身没有重叠;刚好减半,第三维度64不变;
【3、顺利来到Conv2并且结构完全一样进入Conv3:】
我们知道原来INPUT是300*300*3过了第一层出来时150*150*64
那么第二层仍然有池化有128个卷积核,联想推理:
出来的应该是75*75*128;这一步没有问题,我们继续往下分析:
【4、进入Conv3的推演:】
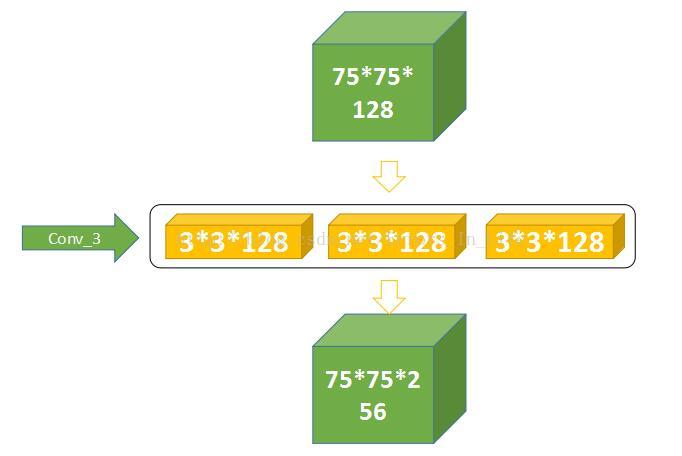
可以知道第三层有256个卷积核,包含三层小的卷基层:
【5、从Conv3到Conv4之间的过度:】
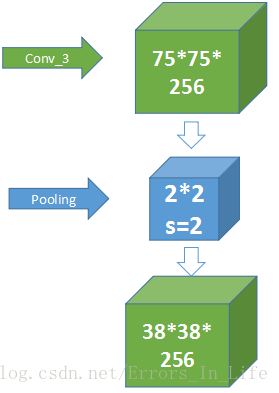
池化没有问题,但是这里75不是一个偶数怎么弄,还记得我们第一部分前面的括号吗?
就是这样,我们在75这里相加了一个一,使之成为76,变成一个偶数,还有一种方法是通过步长的设置这里先不展开来讲了;
【6、后续的步骤】
后面的方法很简单,根据我给的那个VGG16的表格查找每一层里面有什么卷积核?多少个?池化的大小?步长多少?是否需要Padding?解决这些问题,你的VGG16就已经完全可以从头到尾说清楚了!!!
【7、Faster Rcnn的例子】
http://blog.csdn.net/errors_in_life/article/details/70916583
____________后续我将介绍一些基于VGG16深度学习的图像分类知识,一个爱分享自己错误和经验的师兄,多多指教!
<li class="tool-item tool-active is-like "><a href="javascript:;"><svg class="icon" aria-hidden="true"> <use xlink:href="#csdnc-thumbsup"></use> </svg><span class="name">点赞</span> <span class="count">128</span> </a></li> <li class="tool-item tool-active is-collection "><a href="javascript:;" data-report-click="{"mod":"popu_824"}"><svg class="icon" aria-hidden="true"> <use xlink:href="#icon-csdnc-Collection-G"></use> </svg><span class="name">收藏</span></a></li> <li class="tool-item tool-active is-share"><a href="javascript:;"><svg class="icon" aria-hidden="true"> <use xlink:href="#icon-csdnc-fenxiang"></use> </svg>分享</a></li> <!--打赏开始--> <!--打赏结束--> <li class="tool-item tool-more"> <a> <svg t="1575545411852" class="icon" viewBox="0 0 1024 1024" version="1.1" xmlns="http://www.w3.org/2000/svg" p-id="5717" xmlns:xlink="http://www.w3.org/1999/xlink" width="200" height="200"><defs><style type="text/css"></style></defs><path d="M179.176 499.222m-113.245 0a113.245 113.245 0 1 0 226.49 0 113.245 113.245 0 1 0-226.49 0Z" p-id="5718"></path><path d="M509.684 499.222m-113.245 0a113.245 113.245 0 1 0 226.49 0 113.245 113.245 0 1 0-226.49 0Z" p-id="5719"></path><path d="M846.175 499.222m-113.245 0a113.245 113.245 0 1 0 226.49 0 113.245 113.245 0 1 0-226.49 0Z" p-id="5720"></path></svg> </a> <ul class="more-box"> <li class="item"><a class="article-report">文章举报</a></li> </ul> </li> </ul> </div> </div> <div class="person-messagebox"> <div class="left-message"><a href="https://blog.csdn.net/Errors_In_Life"> <img src="https://profile.csdnimg.cn/1/2/5/3_errors_in_life" class="avatar_pic" username="Errors_In_Life"> <img src="https://g.csdnimg.cn/static/user-reg-year/1x/3.png" class="user-years"> </a></div> <div class="middle-message"> <div class="title"><span class="tit"><a href="https://blog.csdn.net/Errors_In_Life" data-report-click="{"mod":"popu_379"}" target="_blank">Errors_In_Life</a></span> </div> <div class="text"><span>发布了22 篇原创文章</span> · <span>获赞 221</span> · <span>访问量 29万+</span></div> </div> <div class="right-message"> <a href="https://im.csdn.net/im/main.html?userName=Errors_In_Life" target="_blank" class="btn btn-sm btn-red-hollow bt-button personal-letter">私信 </a> <a class="btn btn-sm bt-button personal-watch" data-report-click="{"mod":"popu_379"}">关注</a> </div> </div> </div>















 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









