







环境(python3.6)
thread模块和锁对象
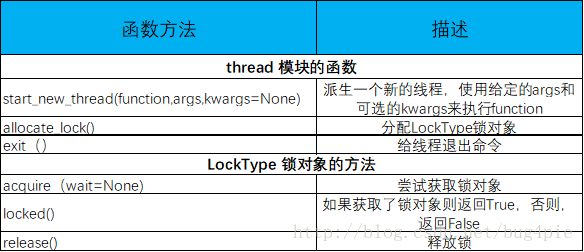
不使用锁结构
代码
import _thread as thread
from time import sleep,ctime
def loop0():
print('\nstart loop 0 at:',ctime())
sleep(4)
print('loop 0 done at:',ctime())
def loop1():
print('\nstart loop 1 at:',ctime())
sleep(2)
print('loop 1 done at:',ctime())def main():
print ('starting at : ',ctime())
thread.start_new_thread(loop0,())
thread.start_new_thread(loop1,())
sleep(7)
print('all DONE at',ctime())
main()结果输出
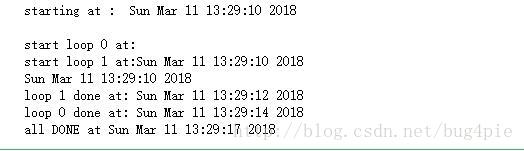
thread的弊端
从代码运行结果可以看到,睡眠4秒和睡眠2秒的代码片段是并发执行的,这样有助于减少整体的运行时间。可以看到loop1 是在loop0之前结束的。
注意:在这里增加了一个sleep(6)用来控制主线程必须在子线程未终止前,不可结束。否则将出现如下结果
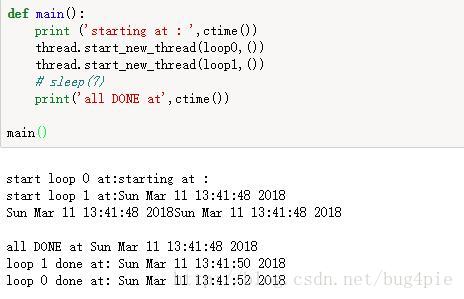
由图片可以看出 “all done” 是优先于loop* done先执行的。导致主线程先一步结束。(在python2.7版本的thread模块中,主线程结束,是会强制使子线程直接终止,在python3.6默认使用的是threading模块(threading模块没有thread的这种弊端),虽然在此调用的_thread模块,貌似没有起到直接终止的作用。)
使用锁结构
thread模块的这种预先估计最大子线程运行时间的方法并没有使程序整体的运行时间减少,可以考虑到如果循环有独立且不同的执行时间要怎么办呢?我们可能会过早或者过晚的退出主线程。
import _thread as thread
from time import sleep,ctime
loops=[2,4] #定时任务
def loop(nloop,nsec,lock):
print('\nstart loop',nloop,' at:',ctime())
sleep(nsec)
print('\nloop ',nloop,' done at:',ctime())
lock.release()def main():
print('starting at :',ctime())
locks = []
nloops=range(len(loops))
for i in nloops:
lock = thread.allocate_lock()
lock.acquire()
locks.append(lock)
for i in nloops:
print('线程 {0} 启动\n'.format(i))
thread.start_new_thread(loop,(i,loops[i],locks[i]))
print('线程 {0} 启动结束\n'.format(i))
for i in nloops:
while locks[i].locked():
print('线程 {0} 还未结束'.format(i))
print('\nall DONE at :',ctime())
main()代码运行结果
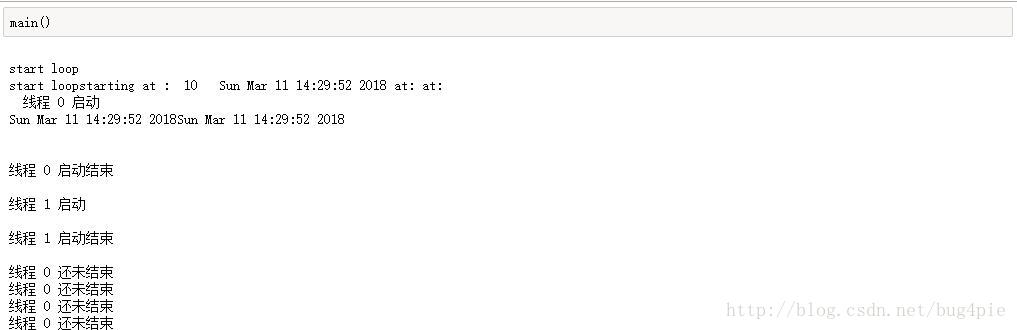
从代码可以看出,使用了锁机制的代码,已经克服了代码运行主线程有可能比子线程更早结束的弊端。在代码中使用
for i in nloops:
while locks[i].locked():
print('线程 {0} 还未结束'.format(i))用来实时的循环判断子线程是否全部结束,进而关闭主线程。
代码运行效果


结束语
thread的使用并不常见,常见的是使用更高级点的threading 。
















 1794
1794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











