







 文章讲述了在Nginx监控中,由于Mtail导致的数据延迟和性能问题。通过分析,作者发现Mtail的一个方法在监控对象增多时性能下降,通过优化代码,将查找复杂度降低,从而提高了性能,解决了晚高峰数据延迟和报警延迟的问题。最终,新版本的Mtail在测试环境中表现出显著的性能提升。
文章讲述了在Nginx监控中,由于Mtail导致的数据延迟和性能问题。通过分析,作者发现Mtail的一个方法在监控对象增多时性能下降,通过优化代码,将查找复杂度降低,从而提高了性能,解决了晚高峰数据延迟和报警延迟的问题。最终,新版本的Mtail在测试环境中表现出显著的性能提升。
问题描述
我们当前在用的 Nginx 监控系统主要存在晚高峰数据延迟和偶发性数据断层两个问题,具体表现就是晚高峰时监控数据总是延迟3分钟以上,极端情况下还会出现监控数据完全停止的情况,导致了Nginx短信电话报警中80%都延迟了3分钟以上,严重影响了报警时效性和数据准确性。
原因分析
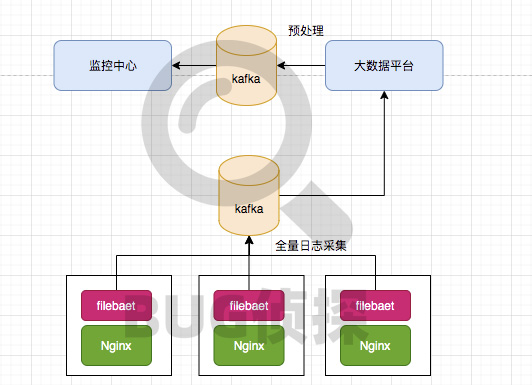
Nginx监控的简化架构大致如下图,可以发现日志数据从 Nginx机器 >>> 大数据计算平台 >>> 监控中心 的传输链路有点长,而大流量的传输往往很容易受内网网络波动影响;预聚合服务则是一个运行在大数据平台上的Flink任务,主要功能是对全量日志数据进行清洗和预聚合, 稳定性易受晚高峰流量突增和宿主机器资源的影响,极端情况下flink任务还会出现宕掉的情况,需重启丢弃数据才能恢复。
优化重构
业界关于Nginx监控的主流的监控方案主要有以下三类:
- 远端处理日志:基于filebeat、logstash之类的日志采集器将nginx日志传输到kafka里,然后使用流式计算任务(flink、storm、spark等)实时消费进行统计。
- 优点:kafka、filebeat、flink都是比较成熟的组件,系统搭建比较简单。
- 缺点:数据传输链路过长、外部依赖太多,稳定性相对较差。
- 本地处理日志:Agent在nginx机器上进行日志解析、计算,然后通过主动上报或开放一个采集端口由采集端拉取两种方式上报到监控中心。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1455
1455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









