








MySQL查询手册:
一,常见关键字:
优先级排序:
from + on + join + where + group by + 聚合函数 + having + select + distinct + order by + limit offset + parition by
on & where:可能同时使用的情况
-
左右连接的致命点:
左右连接时,若左表某行和右表某行不能对应,则保留一条左行+空的信息
不可能通过on cul is not null就筛除了一行含有空列的行
-
内连接的优点:
自动过滤含有null的行
-
同时使用join on + where的情况:准备利用null的信息
- join on之后含有空值
- 使用where过滤空值
having:group by的好帮手
-
group by之后,所有的操作默认基于每组的组首一行,要想进入每组内部统计,只能借助having
select * from employees group by emp_no having count(salary) > 15;
in & not in:含 & 非
-
in & =:
//当明确后者的数据集中只有一个数据时,只能使用 = //反之,数据集中有多个元素时使用in
distinct添加的位置:
-
基本位置:select 后
//select的执行优先级高于order by高于limit offset //所以只要 select 先筛一层,order by再排序,limit offset再筛一层,即可 -
内聚函数位置:count()内
select distinct salary from employee e1 where (select count(distinct salary) from employee e2 where e1.salary < e2.salary) = N-1;
group by 和 partition by的关系:
- 语义上:
- group by 之后强调数据整体:每次移动都以一组的首个为单位
- partition by 之后强调数据个体:一个列用于分组 + 按照组内其他列对组内进行排序
- 语法上:
- group by 可以独立使用
- partition by只能搭配内置函数,在over()内部使用
- group by之后非having操作每组只显示首行的实例:
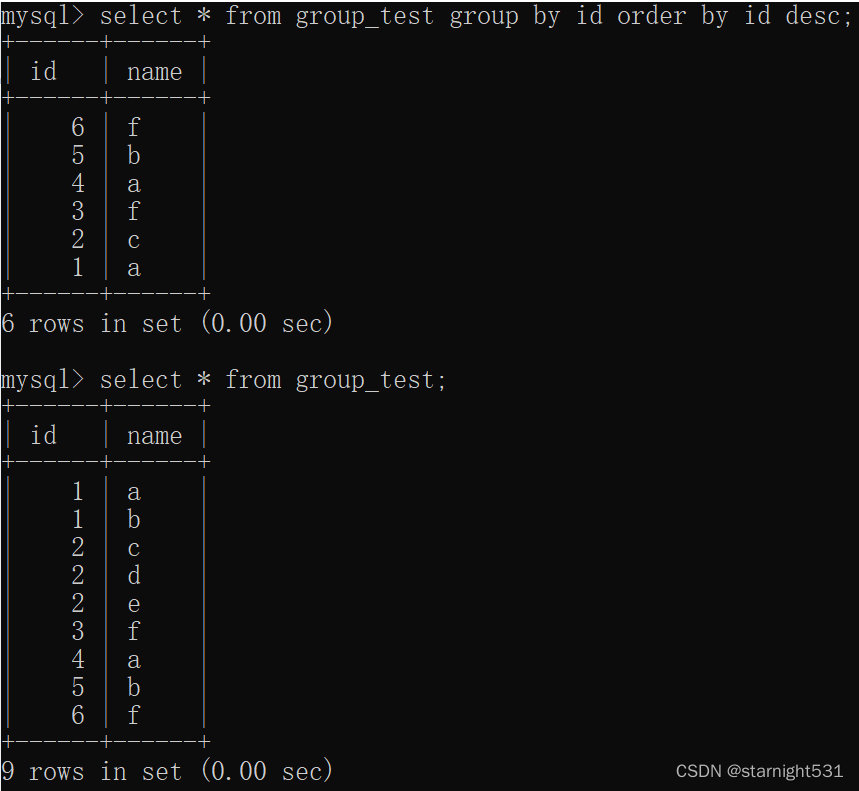
view:
-
语义上:查出一个子表,创建视图来保存,相当于引用
语法上:内部查询子表的sql语句不需要加;
create view view_name as( select * from table1 group by id order by score );
or 和 union:
- 使用 or 会使索引会失效,在数据量较大的时候查找效率较低
- 通常建议使用 union 代替 or
coalesce():
- 参数:多个参数
- 作用:输出从左向右的第一个非空参数
- 应用场景:终止特判
表内某行临时赋值:case
-
语法:
select ( case when mod(id, 2) == 1 and id != sum then id+1 when mod(id, 2) == 1 and id == sum then id else id-1 end ) student, id from seat, (select count(*) sum from seat) sum_table
二,经典模型:
去重 / 不同:
-
法一:desc
select desc salary from salaries order by salary desc; -
法二:group by
select salary from salaries group by salary order by salary desc; -
group by 的内外:
- 内:having 主导审查一组组内多个元素
- 外:select where join on 主导审查一组整体视作一个元素
满足最值:可能不只一行取得
-
满足最值者唯一:排序
select * from employees order by hire_date limit 1; -
满足最值者不唯一:in 子表 或者 = 子表
select * from employees where hire_date in (select MAX(hire_date) from employees); select * from employees where hire_date = (select MAX(hire_date) from employees);
排名第n:
-
rank() over():排序结果作为子表,直接参与查询
# rank()效果为 1 1 3 select * from (select *,rank() over(order by score desc) as 'Rank' from table1) where Rank = n; -
dense_rank() over():排序结果作为子表,直接参与查询,正确的
# dense_rank()效果为 1 1 2 select * from (select *,dense_rank() over(order by score desc) as 'Dense_Rank' from table1) where Dense_Rank = n; -
row_number():排序结果作为子表,直接参与查询
# row_number()效果为 1 2 3 select * from (select *, row_number() over(order by score desc) as 'Row' from table1) where row_number = n; -
select distinct + order by:加上子表查询
select distinct score from table1 order by score limit 1 offset n-1; -
group by + order by:group by之后一组只留一个,且比order by优先执行
select score from table1 group by score order by score limit 1 offset n-1; -
count + distinct:加上子表查询
select distinct salary from employee e1 where (select count(distinct salary) from employee e2 where e1.salary <= e2.salary)=N+1 -
count + group by:加上联表查询
select distinct e1.salary from employee e1, employee e2 where e1.salary <= e2.salary group by e1.salary having count(distinct e2.salary) = N+1
分组,查询组内信息:
-
having统计组内信息:
select *, count(course) from student group by id having count(course) >= 2; -
group by和count是否冲突:
select title, count(title) s from titles group by title having s>1; 分组依据列可以是count参数 # 虽然group by之后非having操作每组都是对组首操作,但是count()等函数是对整组操作 组内列也可以是count参数 select title, count(emp_no) s from titles group by title having s>1; -
分组作为子表:子表查询所得内容由于是组首,所以不会重复
select Email from Person where id in (select id from Person group by email having count(Email) > 1));
多表连接中的null信息:
-
利用左右连接 + is null,解决查找非XXX的行:
select * from employee e left join depart d on e.dep_no = d.dep_no and e.emp_no = d.emp_no where d.emp_no is null; -
效果等同于not in
select * from employee where emp_no is not in (select distinct emp_no from depart); -
左右连接 + is not null,稍改语义也可以解决问题:
select * from employee e left join depart d on e.dep_no = d.dep_no and e.emp_no != d.emp_no where d.emp_no is not null; -
搭配coalesce()使用:
select s1.id id, coalesce(s2.student, s1.student); from seat s1 left join seat s2 on ((s1.id + 1)^1)-1 = s2.id order by s1.id;
字符串中字符出现次数
-
字符串连接:
concat("MySQL中字符串连接"); -
字符串替换:
replace(string, 'a', 'b'); -
字符串长度:
length(); -
字符串中,出现次数:
select length(string)-length(replace(string, ',', '')) from strings;
并列排名 & 非并列排名:
-
1 1 2:dense_rank()
select dense_rank() over(order by socre) 'dense_rank' from table1; -
1 1 3:rank()
select rank() over(order by desc) 'rank' from table1; -
1 2 3:row_number()
select rank() over(order by desc) 'row_number' from table1;
子表查询和联表查询的区别:
-
子表查询:拿着本表中一行的信息,去另一表中逐行对比
select * from scores s1 where (select count(distinct salary) from scores s2 where s1.score <= s2.score) = N; -
联表查询:先笛卡尔积,再on过滤,再提取信息,null信息也特别有用
select * from scores s1, scores s2 where e1.salary <= e2.salary group by s1.id having count(distinct e2.salary) = N;















 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











