一、什么是 Unicode – 字符与十六进制数字的映射表
Unicode(Universal Coded Character Set:国际编码字符集合) 称:统一码、万国码、单一码。
- 由统一码联盟开发,是**计算机科学领域里的一项业界标准**。
- 目的:
- 为全球所有文字系统中的每个****字符分配唯一的数字标识(称为 码点 – codepoint)。
- 从而实现跨平台、跨语言的统一字符表示。
- 码点(codepoint)是指与一个编码表中的某个字符对应的代码值。
- 在 Unicode 标准中,码点采用十六进制书写,并加上前缀 U+ 。
- 示例:
| 字符 | 码点 |
|---|
| A | U+0041 |
| B | U+0042 |
| 汉 | ****U+6C49 |
| 中 | U+4E2D |
| 龘 | U+9F98 |
| 😊 | ****U+1F60A |
Unicode最长可以**使用 4 个字节编码**,也就是 32 个 bit 位。
- 理论上能表示** 232 个字符,可以覆盖全球所有文字系统中的每个****字符**。
二、Unicode 的发展
- 在 1991 年发布了 Unicode 1.0,当时,收集到的字符,仅占用 65536 个**代码值中不到一半**的部分。
- 经过一段时间后,Unicode 中增加了汉语、日语、韩语中的大量表意文字。
- 导致,Unicode 字符超过了 65536 个。
- 2024 年 9 月 10 日发布 Unicode 16.0.0 版本,共包含 154998 个字符。
- Unicode 标准理论最多支持 1114112 个码点(范围 U+0000 ~ U+10FFFF)目前仅使用了约 13.9%。
三、Unicode 标准中码点(Code Point)空间的****划分
- 码点范围是:U+0000 ~ U+10FFFF****。
- 共划分 17 个平面(0 ~ 10)每个平面 65536 个码点(0000 ~ FFFF),总计 1114112 个码点。
- 十六进制下 10 就是 16 。因此,0 ~ 10**** 就是 17 个。
- 17 * 65536 = 1114112 。
- 第 0 个平面:
- 码点范围:U+0000 ~ U+FFFF(共 65,536 个码点)。
- 第 1 个平面:
- 码点范围:U+10000 ~ U+1FFFF(共 65,536 个码点)。
- 第 2 个平面:
- 码点范围:U+20000 ~ U+2FFFF(共 65,536 个码点)。
- 依次类推:
- 第 15 个平面:
- 码点范围:U+F0000 ~ U+FFFFF(共 65,536 个码点)。
- 第 16 个平面:
- 码点范围:U+100000 ~ U+10FFFF(共 65,536 个码点)。
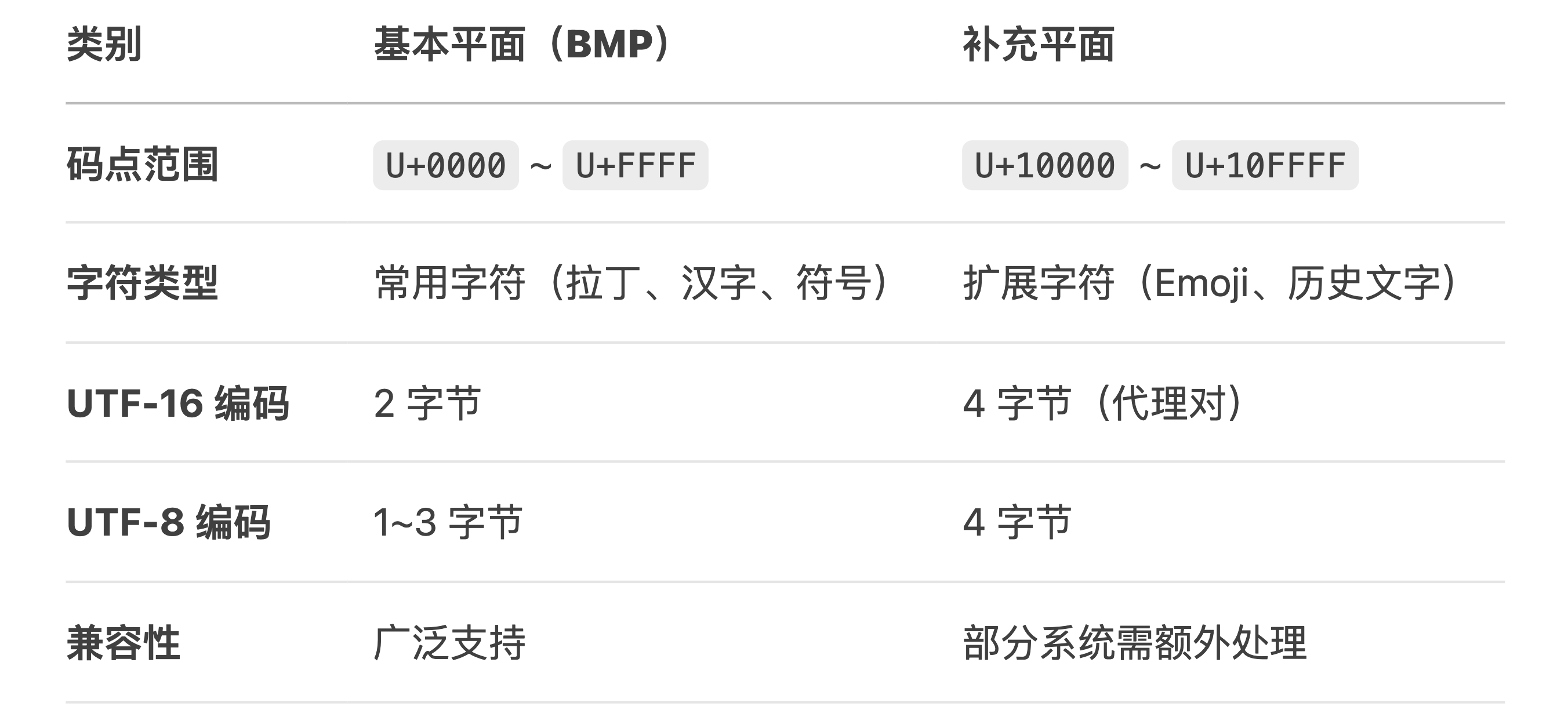
1、基本平面(BMP, Plane 0)

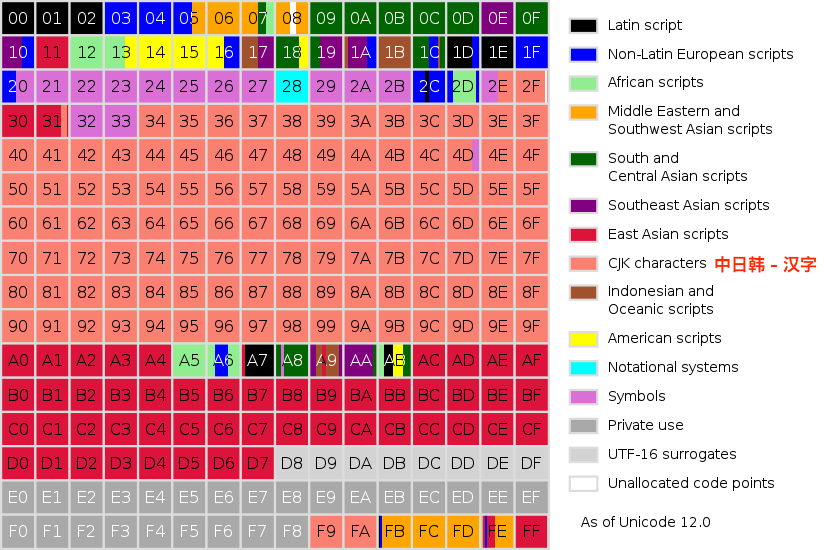
- Java 中的 char 类型用来存储 Unicode 编码基本平面(BMP)范围内的字符****。
2、补充平面(Supplementary Planes)
- 第 1 ~ 16 个平面 统称 补充平面****。

- Java 使用 代理对(Surrogate Pair)(两个 char 组成一个逻辑字符)。
- 可表示 Unicode 扩展的字符(如:Emoji,U+10000 及以上)。
3、小结
- 通过这种分层设计。
- Unicode 既保证了常用字符的高效处理,又为全球文字和符号的无限扩展提供了可能。
四、Unicode vs utf-8、utf-16、utf-32
- Unicode 是一个字符集,给所有的字符分配一个码值。
- Unicode 码点需转换为字节序列才能在计算机中存储/传输。
- utf-8、utf-16、utf-32 是 Unicode 字符集的编码的实现。
- 即:如何将 Unicode 码点转为字节。
- 它们与字符集中字符的总数无关。
1、Unicode 缺点:
- **常用的文字字符**都是采用 4 个字节 **32 位**编码。
- 这在进行字符存储和网络传输时,消耗的资源是比较大的。
public class Unicode {
public static String getHexString(char param, String charsetName){
byte[] bytes = null;
try {
bytes = String.valueOf(param).getBytes(charsetName);
System.out.println(Arrays.toString(bytes));
StringBuffer buffer = new StringBuffer();
for (byte b : bytes){
buffer.append(String.format("%02X", b));
}
return buffer.toString();
} catch (UnsupportedEncodingException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) {
char param = '汉';
System.out.println(Integer.toHexString((int)param).toUpperCase()+"\n");
System.out.println(getHexString(param, "unicode")+"\n");
System.out.println(String.format("%02X", -70));
System.out.println(String.format("%02X", (byte)-70));
System.out.println(getHexString(param, "GBK")+"\n");
System.out.println(getHexString(param, String.valueOf(StandardCharsets.UTF_8))+"\n");
System.out.println(getHexString(param, String.valueOf(StandardCharsets.UTF_16))+"\n");
}
}
2、UTF
- 为了**节省存储空间、提高网络传输效率**。
- 提出了** Unicode 转换格式**(Unicode Transformation Format),简称 UTF。
- UTF-32、UTF-16、UTF-8 都是为了**转换 Unicode 码所制定的各种转换方案【编码方式**】。
3、UTF-8、UTF-16、UTF-32 区别
- 1、UTF 8
- 可变长的编码方式,长度从 1 个字节到 4 个字节不等。能够完全兼容 ASCII 码。

- 如:汉字中,“汉”的 Unicode 码点为:U+6C49。
- 十六进制 6C49 → 二进制 0110 1100 0100 1001。
- 按 UTF-8 三字节格式填充:
- 11100110 10110001 10001001 → 十六进制 E6 B1 89。
- 2、UTF-16
- 2 个字节 或 4个字节 来表示。
- unicode 的基本平面(BMP)范围内的编码,占用两个字节,char 类型变量也是占用两个字节
- BMP(基本多文种平面) 范围内的字符使用 UTF-16 编码,占用 2 个字节;
- 所以,Java 中的 char 类型使用 UTF-16 编码的代码单元(code unit)来存储字符。
- 3、UTF-32
- UTF-32 对 Unicode 中的**每个字符都用 4 个字节来表示**,占用的空间比其他编码要多的多。
- 正是这个原因,人们才用的很少。
- 理解:类似于 🍎 的 编码
- 汉语拼音表示:pingguo 。
- 英语表示:apple 。
五、总结
- 1、字符集是多个字符组成的集合。
- 字符编码是把字符集转换为计算机可识别的二进制数字的转换规则。
- 2、ASCII 字符集和字符编码是美国人最早使用计算机时发明的。
- 它只包含了英文、标点和一些控制字符。
- 用 1 个字节就可以表示。
- 3、GB2312 字符集和字符编码是中国人制定的汉字字符标准。GB【国标的首字母】
- 后来又扩展和修订出 GBK 和 GB18030 标准,目前 GB18030 是最全的汉字字符集。
- 用 2 个字节就可以表示。
- 4、Unicode 字符集是为了覆盖世界各国字符文字而制定的。
- 它的编码规则能够使得任何一个字符都对应一个唯一的二进制码位。
- 5、由于 Unicode 字符编码是定长编码,每个字符占用的空间较大,对于存储和传输产生很大浪费。
- 于是推出了 Unicode 转换格式,即 UTF 。
- UTF-32、UTF-16、UTF-8 都是为了转换 Unicode 码所制定的各种转换方案。
- 它们都是对 Unicode 码点,进行不同的二进制编码。
- 6、UTF-8 只是 Unicode 的一种实现方式,UTF-8 是编码方式,而 Unicode 是字符集合。
- 7、UTF-8 采用**变长字节进行字符编码,1 到 4 个字节不等**,并且它能够完全兼容 ASCII 码。
- 根据 Unicode 字符范围进行不同字节的编码方案,大大减少编码字节的大小,提升了使用效率

























 1628
1628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









