






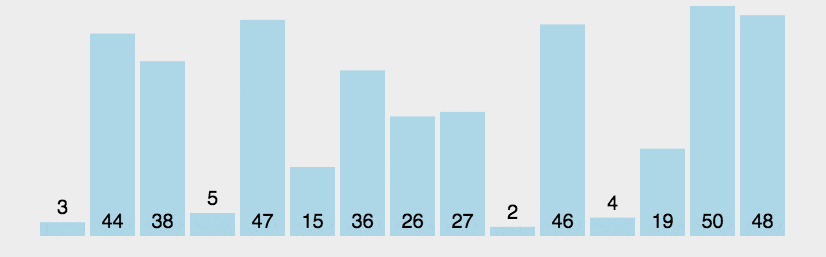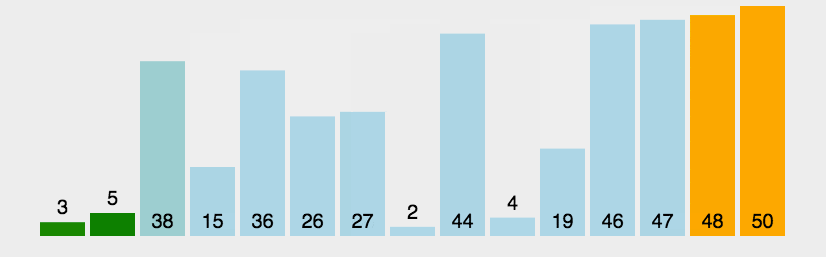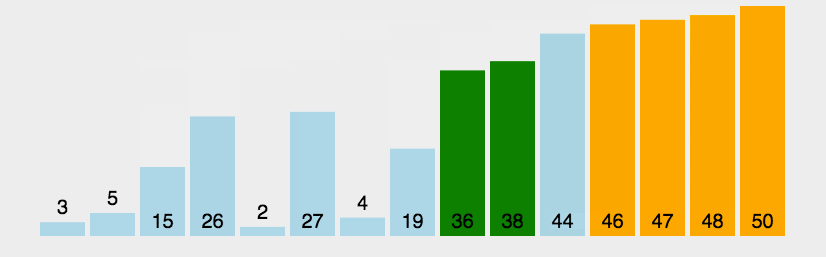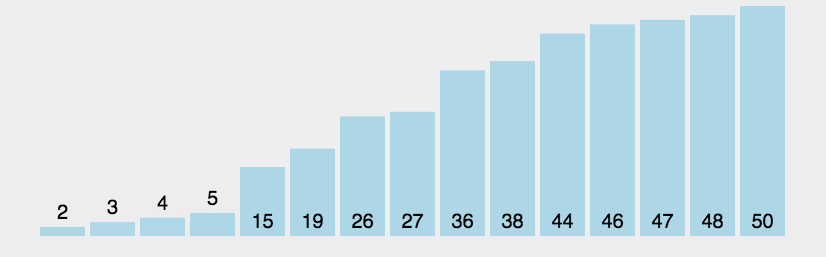
1. 冒泡排序的基本原理
冒泡排序(Bubble Sort)是一种简单的排序算法,它重复地遍历要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。遍历数列的工作是重复进行的,直到没有再需要交换的元素,这意味着数列已经排序完成。这个过程就像水底的气泡一样逐渐上升到水面。
2. 简单的Python冒泡排序代码示例
以下是一个简单的Python冒泡排序的代码示例:
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
# 测试冒泡排序
arr = [3,38,44,15,5,47,36,2,19,48,50,47,27,19]
sorted_arr = bubble_sort(arr)
print("Sorted array:", sorted_arr)
3. 冒泡排序的时间复杂度和空间复杂度
- 时间复杂度:冒泡排序在最坏和平均情况下都是O(n^2),其中n是列表的长度。这是因为它需要双重循环来遍历整个列表。在最好的情况下(即列表已经是有序的),时间复杂度是O(n),但这种情况很少见。
- 空间复杂度:冒泡排序的空间复杂度是O(1),因为它只使用了固定的额外空间来存储临时变量(用于交换)。
4. 冒泡排序的优缺点
优点
- 简单直观,易于实现。
- 是稳定的排序算法(即相等的元素在排序后的序列中保持原有的顺序)。
缺点
- 时间复杂度较高,不适合对大数据集进行排序。
- 在最坏的情况下,需要进行大量的比较和交换操作。
5. 优化后的Python冒泡排序代码示例
以下是一个优化后的冒泡排序代码示例,通过添加一个标志位来减少不必要的比较:
def bubble_sort_optimized(arr):
n = len(arr)
for i in range(n):
swapped = False
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
swapped = True
if not swapped:
break # 如果这一轮没有发生交换,说明数组已经有序,可以提前结束
return arr
# 测试优化后的冒泡排序
arr = [3,38,44,15,5,47,36,2,19,48,50,47,27,19]
sorted_arr = bubble_sort_optimized(arr)
print("Sorted array:", sorted_arr)
根据要求编写代码。
1)随机生成范围在0到10的20个小数(包含0和10,保留小数点后两位),并且输出到控制台上。
2)编写冒泡排序算法,使得随机生成的数按照从大到小的顺序排序,并且输出到控制台。
import random
#定义随机函数random_array
def random_array():
#定义空列表li,用来存储随机数
li = []
#循环执行20次
for i in range(20):
#将随机的数字添加到li列表中
li.append(round(random.uniform(0,10),2))
#返回随机数列表li
return li
#定义列表元素交换函数,将列表索引i和列表索引j的两个元素继续交换
def swap (listI, i ,j):
#定义中间变量temp,保存列表索引i的元素
temp = listI[i]
#将列表索引j的元素放到列表索引为i的位置
listI[i] = listI[j]
#将temp的元素放到列表索引j的位置
listI[j] = temp
#定义冒泡排序函数
def bubble_sort(listI):
#循环遍历列表listI
for i in range(len(listI),1,-1):
#遍历列表,列表中第j个元素与列表中的其他元素对比大小
for j in range(1,i):
#如果当前的第j个元素小于后面的一个元素
if listI[j] < listI[j-1]:
#则交换位置,把当前的元素后移,从大到小的排序
swap(listI,j,j-1)
#循环结束,返回排序后的元素
return listI
#调用random_array函数,执行的结果保存到li中
li = random_array()
#将随机列表li传入bubble_sort函数中进行冒泡排序,最后打印排序的后结果,从大到小的排序
print(bubble_sort(li))


















 5586
5586



 到【灌水乐园】发言
到【灌水乐园】发言








