







 在电子商务场景中,存在大量基于商品的应用任务,如下图所示,通常商品会包含图片、标题和结构化的知识,这是一个典型的多模态场景。这张图是产品的多模态数据示例。每个个体都有一个标题、一个图像和一个PKG,PKG通过三元组(<item,property,value>)描述产品的客观属性。PKG是产品知识图谱。
在电子商务场景中,存在大量基于商品的应用任务,如下图所示,通常商品会包含图片、标题和结构化的知识,这是一个典型的多模态场景。这张图是产品的多模态数据示例。每个个体都有一个标题、一个图像和一个PKG,PKG通过三元组(<item,property,value>)描述产品的客观属性。PKG是产品知识图谱。

多模态在电子商务领域的挑战:模态丢失和模态噪声。在实际的电子商务场景中,一些卖家没有上传商品图片(或标题)到平台,一些卖家提供的商品图片(或标题)主题不明确或语义不准确,使得信息特别令人困惑。图中的Item-2和Item-3分别展示了我们场景中的模态噪声和模态丢失示例。

为了解决上述问题,引入了产品知识图谱(PKG),并将其视为一种新模态,称为知识模态。PKG以三元组形式表示,例如<Item-1, Material, Cotton> 表示Item-1的材质是棉花。
引入PKG主要有两个原因:(1) PKG具有高质量。PKG描述了商品的客观属性,结构化且易于管理,通常会进行维护和标准化工作,因此PKG相对干净且可信。(2) PKG与其他模态的信息存在重叠。以图中的Item-1为例,一方面,图片、标题和PKG都说明Item-1是一件长袖T恤。另一方面,PKG显示这件长袖T恤不仅适合秋季,也适合春季,这在图片或标题中是无法得知的。因此,当存在模态噪声或模态丢失时,PKG可以对其他模态进行纠正或补充。

知识图谱与预训练语言模型结合的例子很多,表中的模型都是,然而,目前的KG增强预训练模型主要集中在单一模态,尤其是文本模态。至今为止,这是首个将知识图谱纳入多模态预训练的研究。

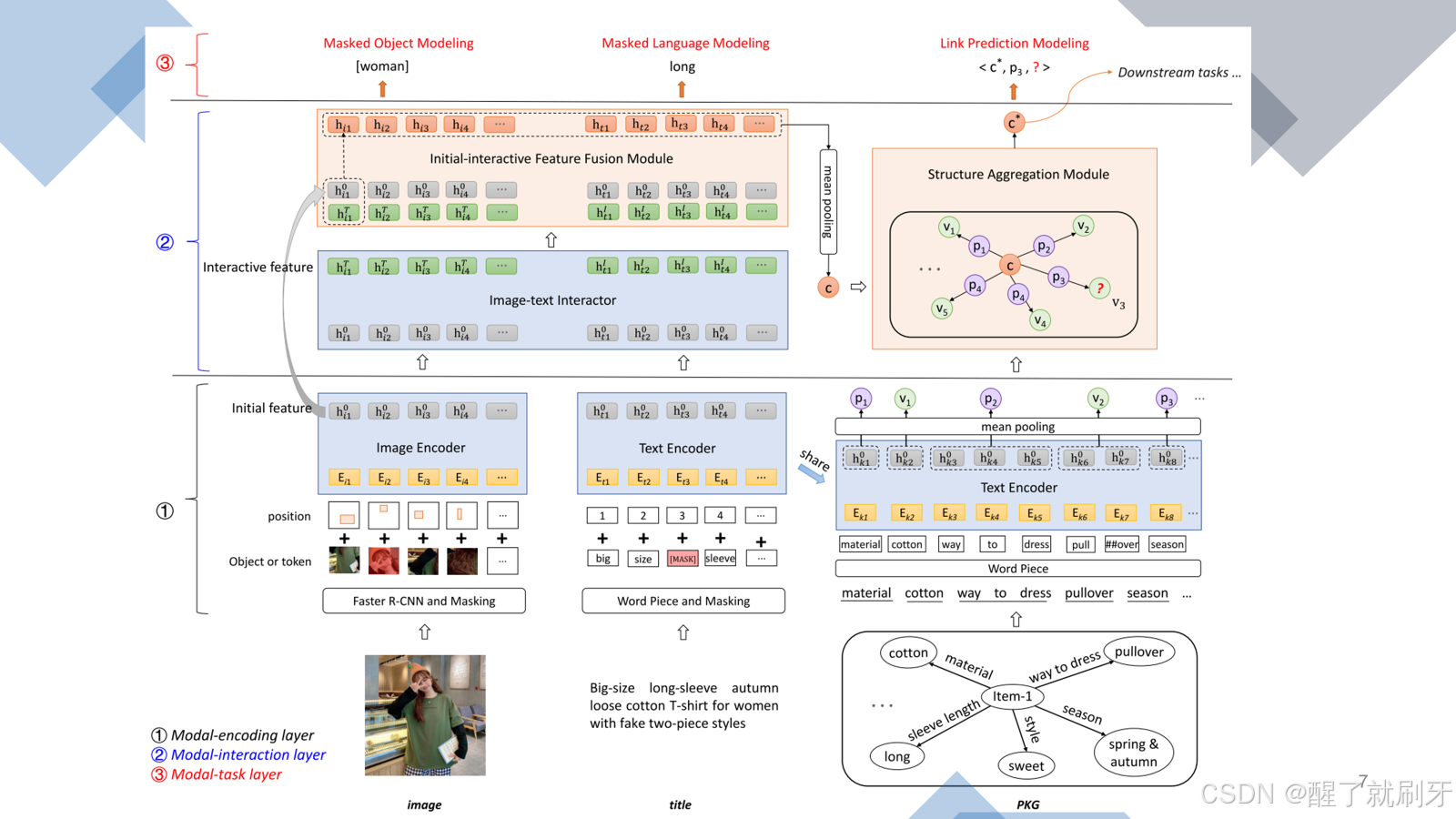
这是本文K3M模型的框架,分为三大部分,最下面是编码每个模态的单独信息,中间是模态之间的交互,最上面是针对图像模态、文本模态和知识模态的三个预训练任务。

具体来说,参考ViLBERT ,使用Faster R-CNN 从图像中检测出一系列对象也就是,RoI,感兴趣区域,并将这些对象的边界框作为它们的位置信息。和ViLBERT一样15%的对象随机掩码。然后如图所示,对象嵌入和位置嵌入的总和E下标i表示图像image,被输入到基于Transformer的图像编码器中,图像编码器输出图像的初始特征h下标i代表是image图像。ViLBERTViLBERT

参考BERT ,商品的标题title首先通过WordPieces被分词为一个token序列,15%的token被随机掩码。然后如图所示,token嵌入和位置嵌入的总和E,下标t表示title,被输入到基于Transformer的文本编码器中,然后得到标题的特征。
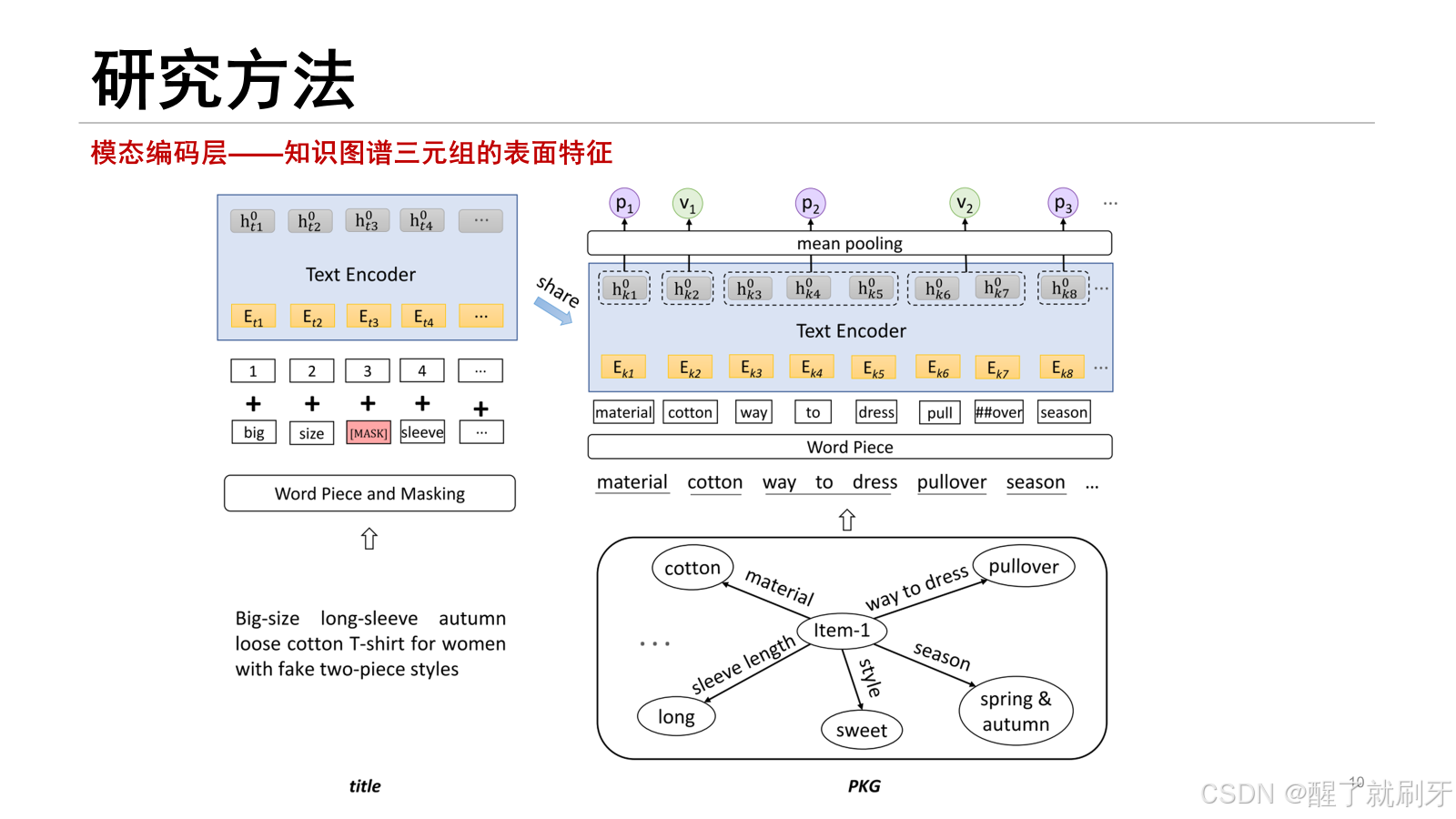
获取三元组特征:从知识图谱中提取关系和尾实体的表面形式特征,但不考虑头实体,因为其表面形式缺乏语义。
拼接知识文本:将三元组的所有关系和尾实体拼接成一段长文本,例如“属性1 值1 属性2 值2 …”。
文本编码:将拼接的知识文本进行分词,然后使用相同的文本编码器提取初始特征。一个关系或尾实体可能被分割为多个token,如图所示
均值池化:最后,通过对最后隐藏层状态的均值池化,计算每个关系和尾实体的表面形式特征,得到的特征用𝑝𝑥和𝑣𝑥表示。

首先,图像-文本交互器应用vilbert的共注意力Transformer ,将图像初始特征和文本初始特征作为输入。具体来说,在交叉注意力Transformer中,每个模态的“key”和“value”传递到另一个模态的注意力块中,进行图像条件的文本注意力和文本条件的图像注意力。之后,图像-文本交互器生成图像的交互特征 [hi1T,hi2T,…,hiM1T和文本的交互特征 [ht1I,ht2I,…,htM2I 然而,通过共注意力Transformer学习模态交互特征时,忽略了单个模态的独立性。当某个模态存在噪声或丢失时,模态交互将对另一个模态产生负面影响,从而破坏模态的交互特征。因此,保持单个模态的独立性是必要的。为了解决这个问题,我们提出保留在模态编码层中学习到的图像初始特征和文本初始特征,并设计一个初始-交互特征融合模块(IFFM),将图像和文本模态的初始特征与它们的交互特征融合。IFFM将对象(或token)的初始特征和交互特征作为输入,并将这两个特征向量融合为一个输出向量。其中,函数 fusion(⋅) 是融合算法,K3M中有三种融合算法:(1) 均值:计算两个输入向量的均值,模型记为“K3M(mean)”。(2) 软采样(Soft-Sampling):[37]中提出的一种用于特征融合的高级采样方法,模型记为“K3M(soft-spl)”。(3) 硬采样(Hard-Sampling):[37]中提出的另一种用于特征融合的高级采样方法,模型记为“K3M(hard-spl)”。
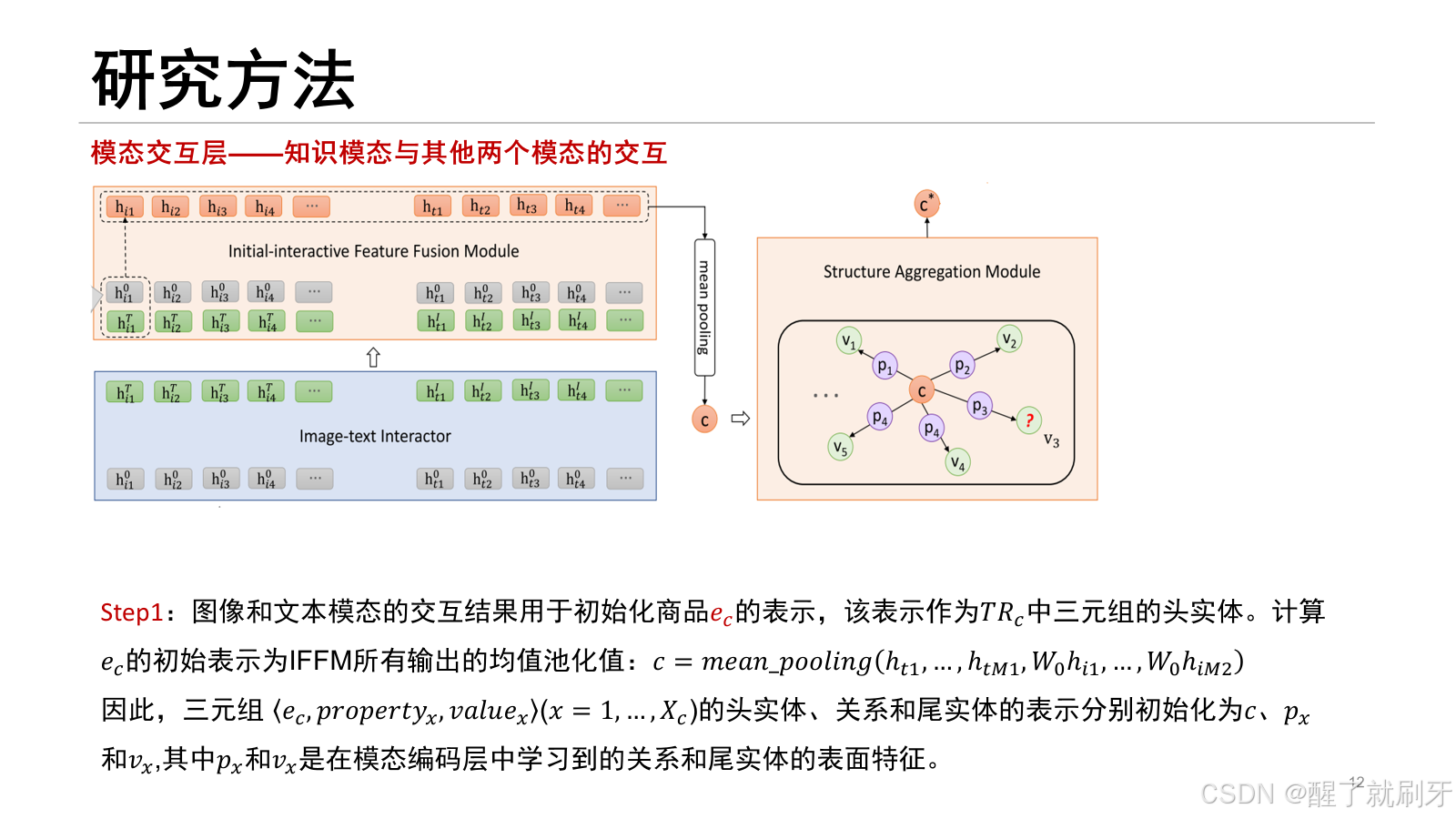
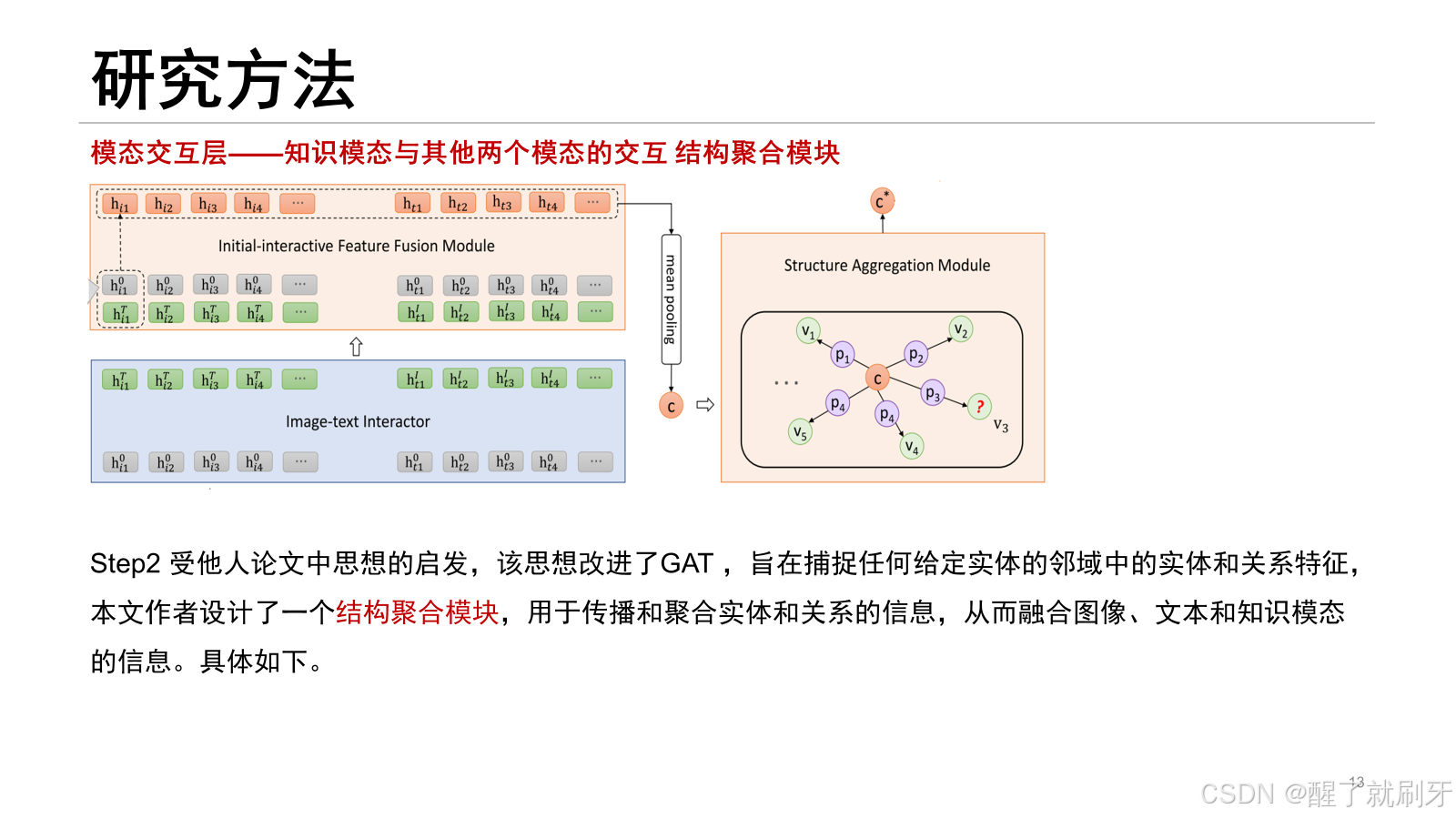
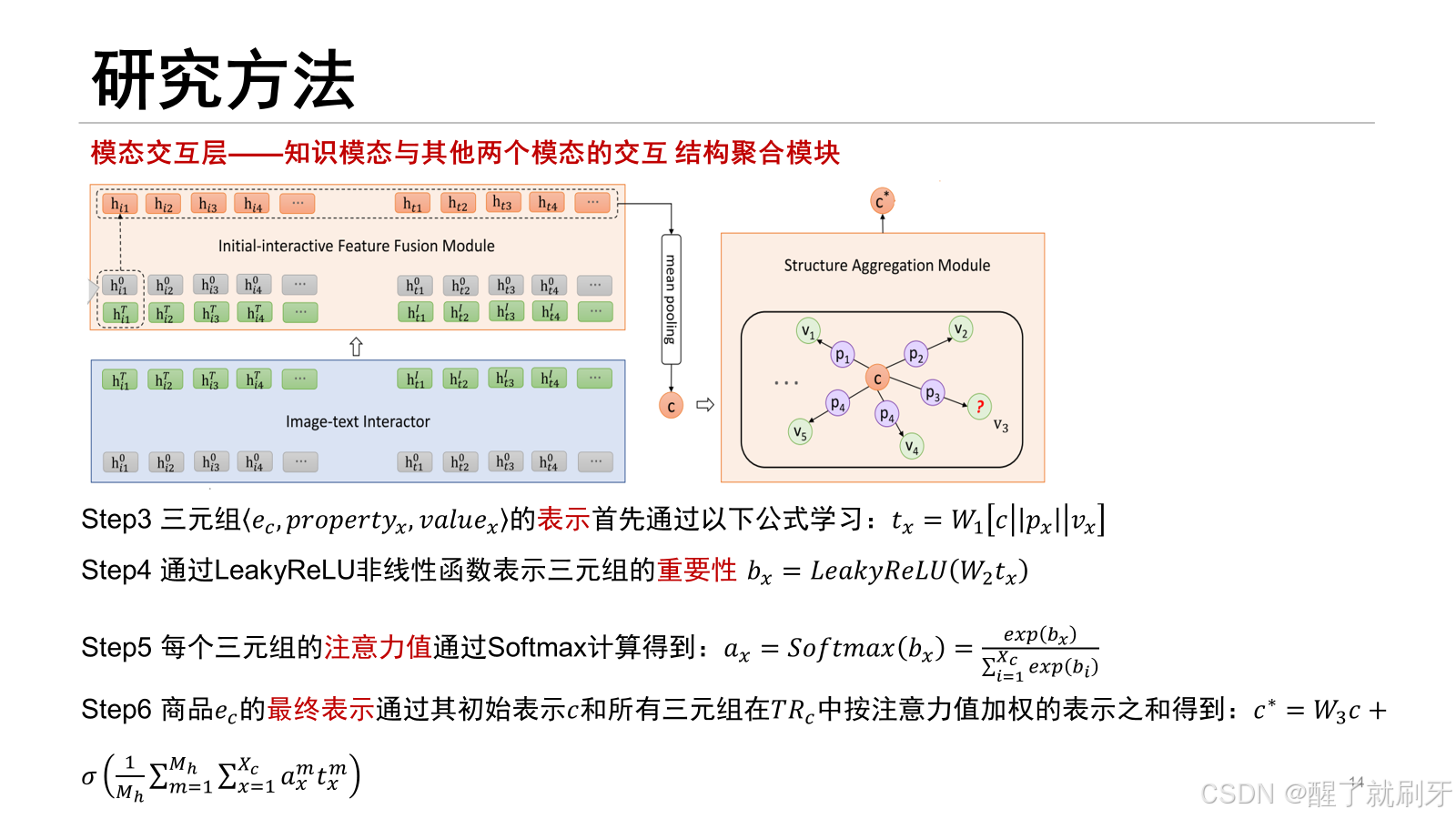



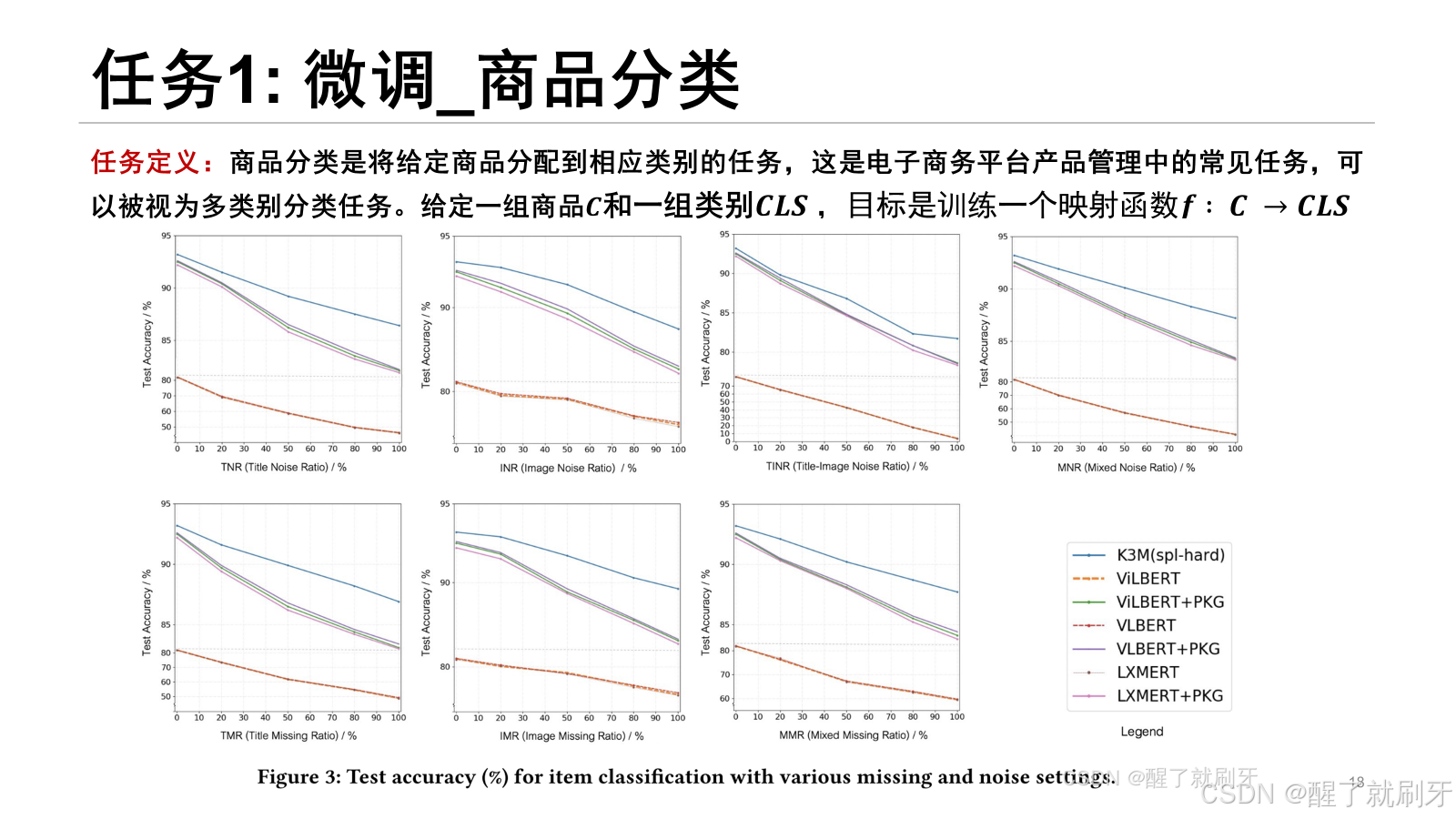
图3显示了项目分类的各种模型的结果,从中我们可以观察到:(1)当存在模态缺失或模态噪声时,基线模型严重缺乏鲁棒性。对于“仅标题缺失”,与TMR= 0%相比,当TMR增加到20%、50%、80%和100%时,“ViLBERT”、“LXMERT”和“VLBERT”的性能平均下降10.2%、24.4%、33.1%和40.2%。(2)与图像模态相比,缺失和噪声的文本模态对性能的影响更大。比较3个基线的“仅标题噪声”和“仅图像噪声”,随着TNR的增加,模型性能下降了15.1%-43.9%,而随着INR的增加,模型性能下降了2.8%-10.3%,这表明文本信息在其中起着更重要的作用。(3)知识图的引入可以有效地改善模态缺失和模态噪声问题。有PKG的基线实验结果明显优于无PKG的基线实验结果。对于“仅标题缺失”,在没有PKG的基线基础上,当TMR从0%增加到100%时,“ViLBERT+PKG”、“LXMERT+PKG”和“VLBERT+PKG”获得了13.0%、22.2%、39.9%、54.4%和70.1%的平均改善。(4)我们的方法在这些性能指标评测中实现了最先进的性能。它进一步改善了“ViLBERT+PKG”、“LXMERT+PKG”和“VLBERT+PKG”的结果,在各种模态缺失和模态噪声设置下改善了0.6%到4.5%之间。
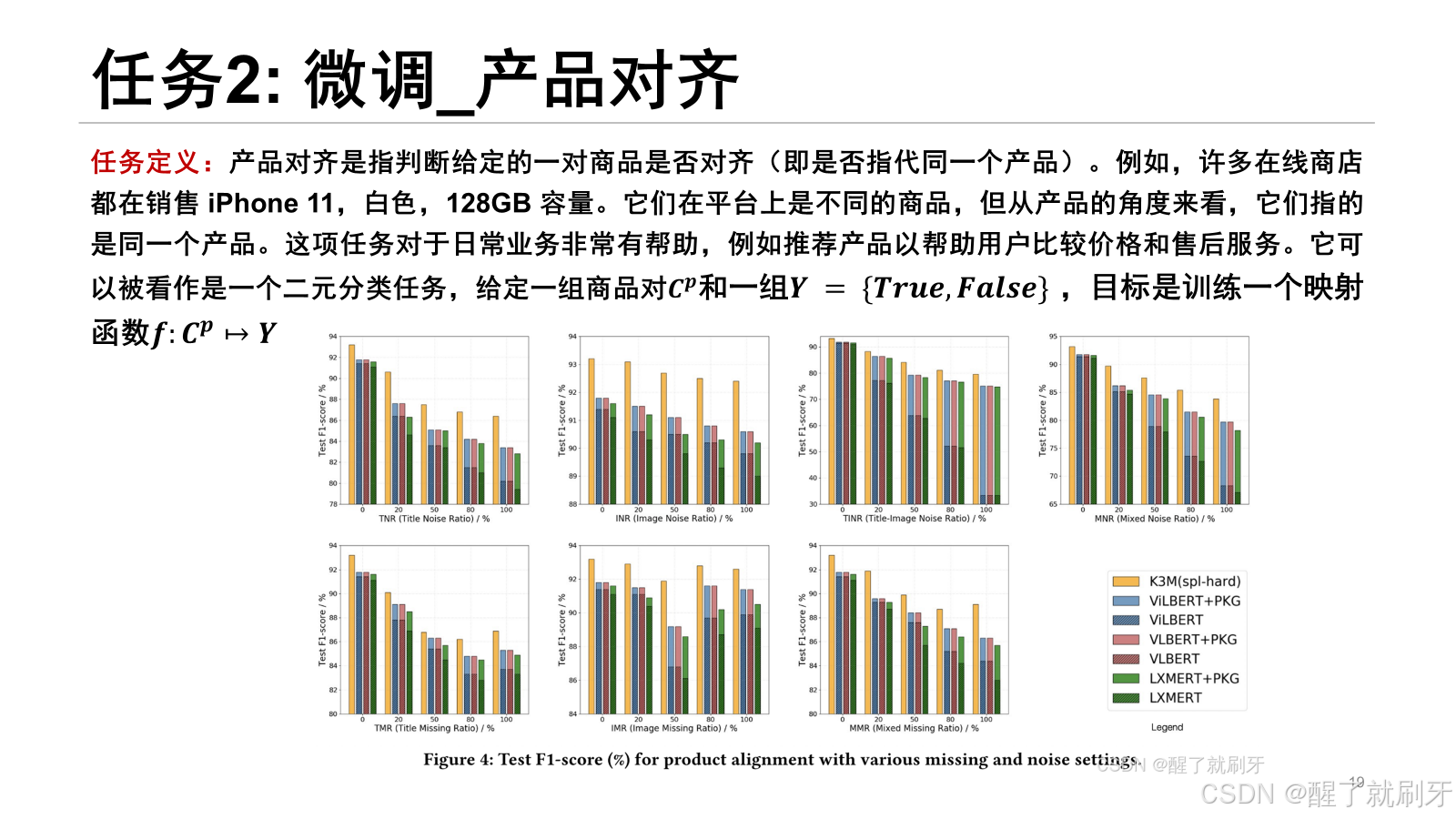
该任务的评估指标为 F1-score。图 4 显示了产品对齐任务的测试 F1-score。在这个任务中,我们可以得到与商品分类任务类似的观察结果。此外,对于模态缺失,模型性能不一定随着缺失比例的增加而下降,反而波动:当缺失比例(TMR、IMR 和 MMR)为 50% 或 80% 时,模型性能有时甚至低于 100% 时的性能。实际上,这个任务的本质是学习一个模型来评估两个商品的多模态信息的相似性。从直觉上看,当对齐商品对中的两个商品同时缺少标题或图片时,它们的信息看起来比当一个缺少标题或图片而另一个没有缺失时更相似。
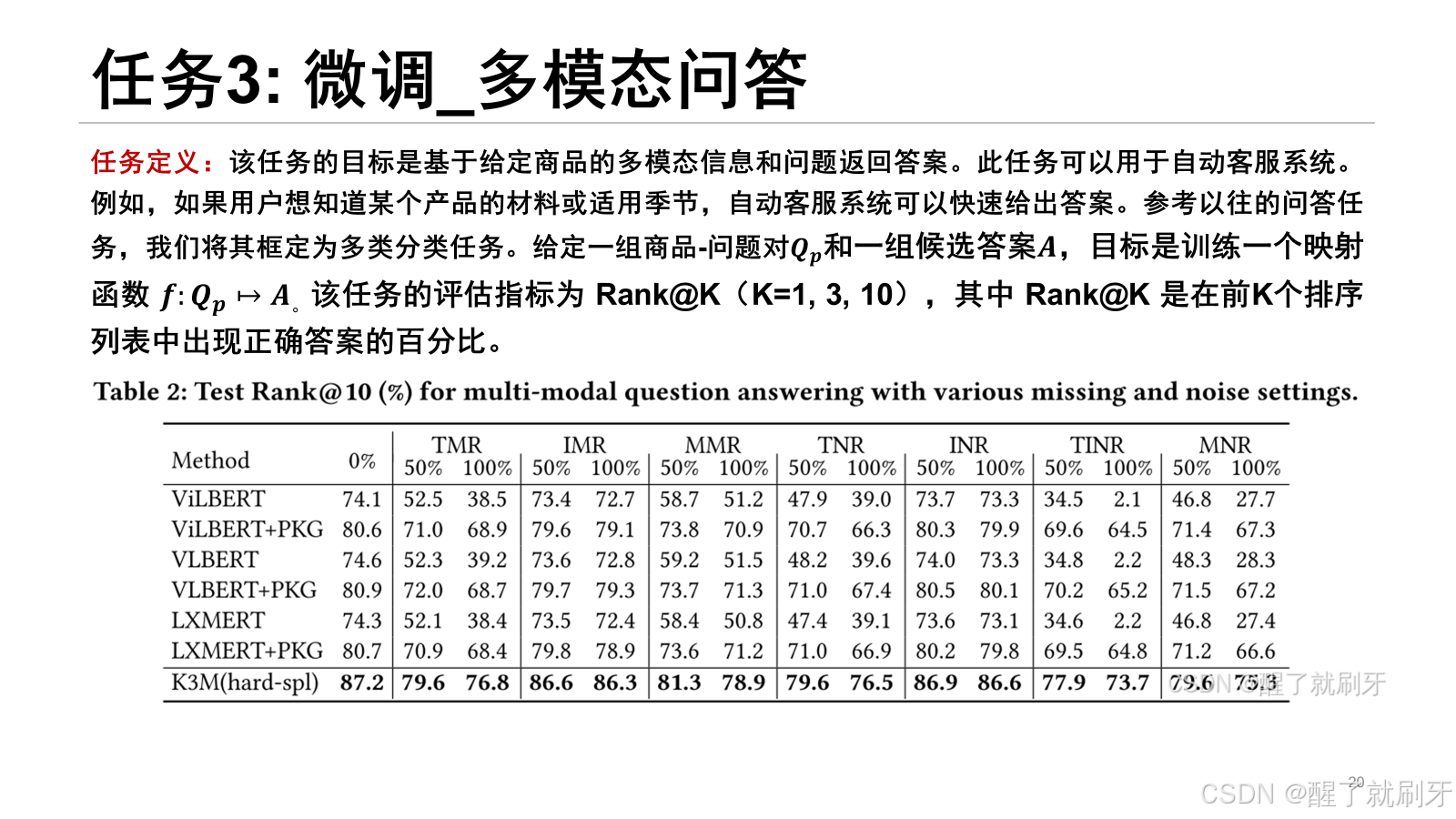
在这个任务中,可以得到与商品分类任务类似的观察结果。
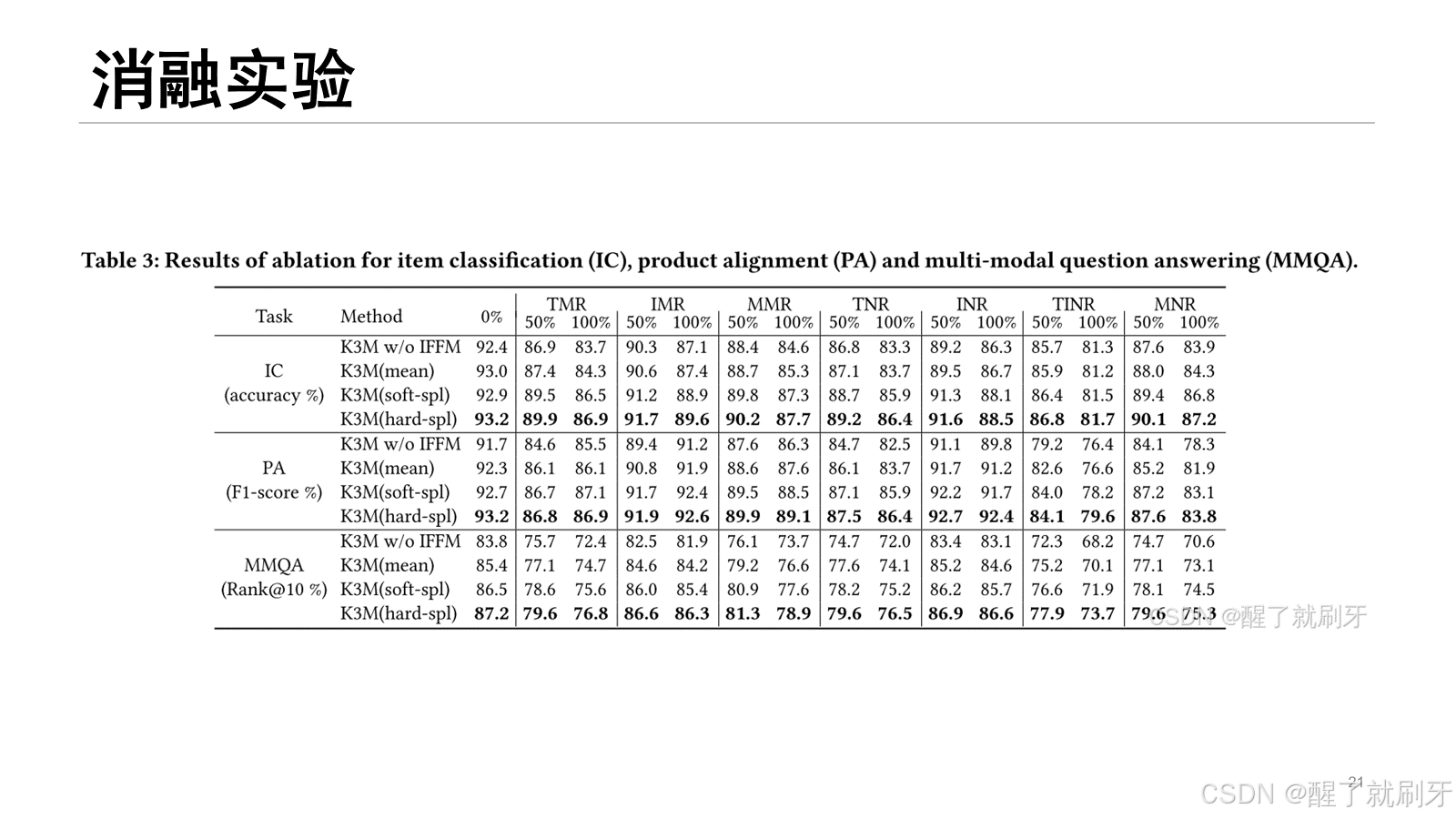
表 3 显示了三个下游任务的结果。我们可以看到,带有 IFFM 的 K3M 应用不同的融合算法时,其表现均优于没有 IFFM 的 K3M,这表明我们提出的初始特征和交互特征的融合确实能够通过保持文本和图像模态的独立性进一步提升模型性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









