






本文为 Qunar 技术沙龙投稿,版权归原作者所有,未经允许,请勿转载。
原文地址:http://mp.weixin.qq.com/s/POHfCj4ioO072S-DcNeM2Q
作者:张雷,2014年加入 Qunar,目前在去哪儿网大住宿事业部用户订单组担任后端开发工程师,从事酒店交易相关研发工作。
【CSDN 有奖征稿啦】技术之路,共同进步,有优质移动开发、VR/AR/MR、物联网原创技术文章欢迎发送邮件至 mobilehub@csdn.net。
Dubbo 是一个分布式服务框架,致力于提供高性能和透明化的 RPC 远程服务调用方案,以及 SOA 服务治理方案。本文简单介绍 Dubbo 底层数据传输模型,以 Dubbo 协议+Hessian2 序列化协议为例,分析调用过程中,消费者和服务提供者间传输对象时底层数据的编解码细节。编解码是实现高性能服务框架的一个关键要素,本文还提出了一些可以提高效率的改进点以供参考。
一、Dubbo 网络传输层
Dubbo 的网络传输层(Transport)依赖数据序列化层(Serialize),负责单向消息传输。
当消费者调用服务提供者的服务时,要向服务提供者传递方法名称和参数等信息,服务提供者执行后,也会将执行结果返给消费者,这些信息以二进制方式传输,两者需要统一的协议对数据进行编码和解码,而这部分逻辑就包含在网络传输层中。在远程调用过程中,依赖网络传输层的上层模型可以不关注传输细节,只处理对象即可。
Dubbo 的网络传输层支持多种传输协议和对象序列化方式,主要有以下几种:
- 传输协议:Dubbo、RMI、Hessain、WebService、Http 等
- 序列化方式:Hessian2、dubbo、JSON、Java 原生等
二、Dubbo 协议
Dubbo 默认使用 Dubbo 协议, Hessian2 序列化方式,适合传入传出参数数据包较小,消费者比提供者个数多的场景。
Dubbo 协议采用经典定长包头+变长包体的协议设计,包头记录了数据的序列化方式,请求状态,数据长度等信息,包体是请求/响应对象序列化后的二进制数据。格式见下图:

网络传输层传输的就是这种二进制数据,基本流程如下:
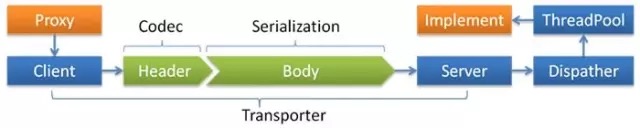
用 Netty 作为传输框架时,图中的 Client 和 Server 分别对应 NettyClient 和 NettyServer,在创建的时候会指定 encoder 和 decoder 完成对象的编码和解码。Dubbo 协议默认 DubboCountCodec 为编解码器,该类的成员 DubboCodec 封装了 Dubbo 协议的编解码逻辑,同时完成对象的序列化或反序列化。
以 Dubbo 协议+Hessian2 序列化协议+Netty 为例。消费者发送请求参数时,参数会经过 InternalEncoder 进行编码:

服务提供者收到数据时通过 InternalDecoder 进行解码。InternalDecoder 每次收到的数据包不一定是完整的 dubbo 协议包,所以 InternalDecoder 内部创建了一个 ChannelBuffer,可以把多个数据包合并成一个完整的 dubbo 协议包。
InternalDecoder 的解码流程如下:

DubboCodec.decode 方法一次只会解析一个完整的 dubbo 协议包,但 Netty 每次收到的数据不一定是完整的 dubbo 协议包,也可能是多个 dubbo 协议包,对此 InternalDecoder 内部创建了一个 ChannelBuffer 来处理这些情况。
收到不完整的 dubbo 协议包
messageReceived 在 decode 之前,会记录当前的读索引 readerIndex,decode 方法在解析不完整的 dubbo 协议包时,会返回 NEED_MORE_INPUT,messageReceived 收到该返回值时,就把读索引回滚到之前保存的位置,然后将待处理的数据赋给 InternalDecoder 的内部 buffer。Netty 下次收到数据包时,同样会调用 messageReceived 方法,此时新的数据会追加在内部 buffer 后面。调用 decode 方法时会传入合并后的数据,完成 dubbo 数据包的解码。
收到多个 dubbo 协议包
messageReceived 是循环调用 decode 方法进行解码,每次 decode 会处理一个 dubbo 协议包。当数据中有多个 dubbo 协议包时,messageReceived 会循环解码,直到所有 dubbo 协议包处理完成,解码结束;或者遇到一个不完整的 dubbo 协议包,按第一种情况处理。
三、Hessian2 序列化协议
Hessian2 序列化协议(http://hessian.caucho.com/doc/hessian-serialization.html)是由 caucho 提供的一种开源协议。Dubbo 的 com.alibaba.com.caucho.hessian.io 包实现了 Hessian2 协议。DubboCodec 在生成/解析完 Dubbo 协议包头之后,会使用 Hessian 序列化/反序列化传输对象。
Hessian2Output 类负责对象的序列化,内部有一个 byte[]缓存,序列化对象时先向缓存中写入数据,当缓存满或者序列化完成时,将数据写入到输出流中。Hessian2Input 类负责对象的反序列化,内部也有一个 byte[]缓存,大小为 256。反序列化时,先处理缓存中的数据,如果处理完成,从输入流中复制待处理的数据到缓存中,直到反序列化完成。
字符串序列化和反序列化
在序列化后的二进制数据中,字符串二进制数据占了很大一部分,接下来分析一下 Hessian 协议对字符串的处理。
Hessian2 字符串编码协议
Hessian2 中的字符都用 UTF-8 编码,长一点的字符串序列化时会被分割为多个块(chunk),x53 (‘S’) 开头代表终止块, x52 (‘R’) 开头代表非终止块,每个标记字节后面都跟有一个 16 位的无符号整数来表示块长度。这个长度是字符数,而不是编码后的二进制数组长度。
协议说明:

Hessian2 字符串处理
Java 中的 char 使用 UTF-16 编码,Hessian2 协议中的字符都是 UTF-8 编码,序列化时需要进行一次转换。Hessian2Output 中的 printString 方法循环遍历字符串中的每个字符,将编码后的字符写入缓存。
反序列化字符串时,Hessian2Input 中的 readString 方法首先解析标记字节,获得字符串中的字符个数,然后循环调用 parseChar 处理数据,将二进制数组解码。parseChar 实际调用 parseUTF8Char,而 parseUTF8Char 就是上面 printString 编码逻辑的逆向操作。parseUTF8Char 每次从缓存中读入一个字节,根据编码规则判断是否需要读入新字节,最后完成单个字符的解码。
四、改进点
减少数组复制
HessianInput 优化
Dubbo 的 InternalDecoder 内部在解码数据包时,会把数据包复制到一个 ChannelBuffer 中,这个 ChannelBuffer 会传给 HessianInput 进行反序列化。HessianInput 内部也维护了一个缓存,大小为 256 字节,反序列化时首先从缓存中读入数据, 读完后再从 ChannelBuffer 里复制最多 256 字节的数据。
HessianInput 默认数据来源是 InputStream,增加内部缓存的本意是减少 IO,提高反序列化效率。但是对 ChannelBuffer 来说,其内部数据已经是完整的序列化数组,HessianInput 增加缓存反而导致了额外的数据复制,降低了效率。如果需要提高 Dubbo 反序列化的效率,可以去掉 HessianInput 内部的缓存,直接使用 ChannelBuffer 进行反序列化,省掉额外的数据复制操作。
使用 Netty4
Netty4 中引入了 ByteToMessageDecoder,封装了通用的数据解码流程,不同的协议实现只要继承 ByteToMessageDecoder,实现自己的解析逻辑即可。
ByteToMessageDecoder 内部创建了一个 ByteBuf 类型的缓存 cumulation,在解码底层数据时,ByteToMessageDecoder 会循环调用子类的 decode 方法解析收到的数据,decode 方法处理后剩余的数据会留在 cumulation 中,等下一次收到数据时共同处理。cumulation 默认支持堆外内存,读取网络传输数据时会减少一次内存复制,提高处理性能。因此,Dubbo 的 InternalDecoder 可以基于 ByteToMessageDecoder 实现,不但代码更简洁,效率也会更好。
压缩二进制数据
Hessian2 序列化协议还支持数据压缩,降低网络占用。用线上一个订单数据测试,内容包括数字,中英文字符。使用 Java 序列化后的数据为 10320 字节,使用 Hessian2 序列化后的数据为 6844 字节,使用 Hessian2 的 Deflation 类压缩后的数据为 3915 字节,压缩后的数据占普通 Hessian2 序列化数据的 57%。但是开启压缩会明显增加序列化耗时。将同一个订单分别进行 10000 次 Hessian2 的普通序列化和压缩序列化,普通序列化平均耗时 0.15ms,压缩序列化平均耗时 0.33ms。如果网络传输比较慢,可以考虑使用 Hessian2 的压缩,结合实际场景进行优化。
选择其他序列化方式
Hessian2 是一个比较旧的跨语言序列化协议,官网的 Java 实现在 2013 年后就没有更新了。最近几年又出现了多种序列化方式,性能优秀,包括:
- Java 语言:Kryo,FST 等
- 跨语言:ProtoBuf,Thrift 等
这些新序列化方式多数优于 Hessian2,因此提升 Dubbo 的性能可以将 Hessian2 序列化方式替换为其他高性能序列化方式。当当开源的 dubbox 就引入了 Kryo 和 FST 两种序列化实现,取代默认的 Hessian2,以提升 Dubbo 的性能。
多种序列化方式性能测试(https://dangdangdotcom.github.io/dubbox/serialization.html)















 256
256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









