






1 MyCat引言
Mycat是开源的、活跃的、基于Java语言编写的MySQL数据库中间件。
可以像使用mysql一样来使用mycat,对于开发人员来说根本感觉不到mycat的存在。
开发人员只需要连接MyCat即可,而具体底层用到几台数据库,每一台数据库服务器里面存储了什么数 据,都无需关心。 具体的分库分表的策略,只需要在MyCat中配置即可。
伪装协议:MyCat伪装了MySQL的协议,所以我们可以将MyCat看做成一台MySQL。
对于应用程序来说,我们完全不用关心其用的是MyCat还是MySQL,应用程序只需要把MySQL连 接换成MyCat连接即可,驱动不用改
优势
1.性能可靠稳定
2.强大的技术团队
3.体系完善
4.社区活跃
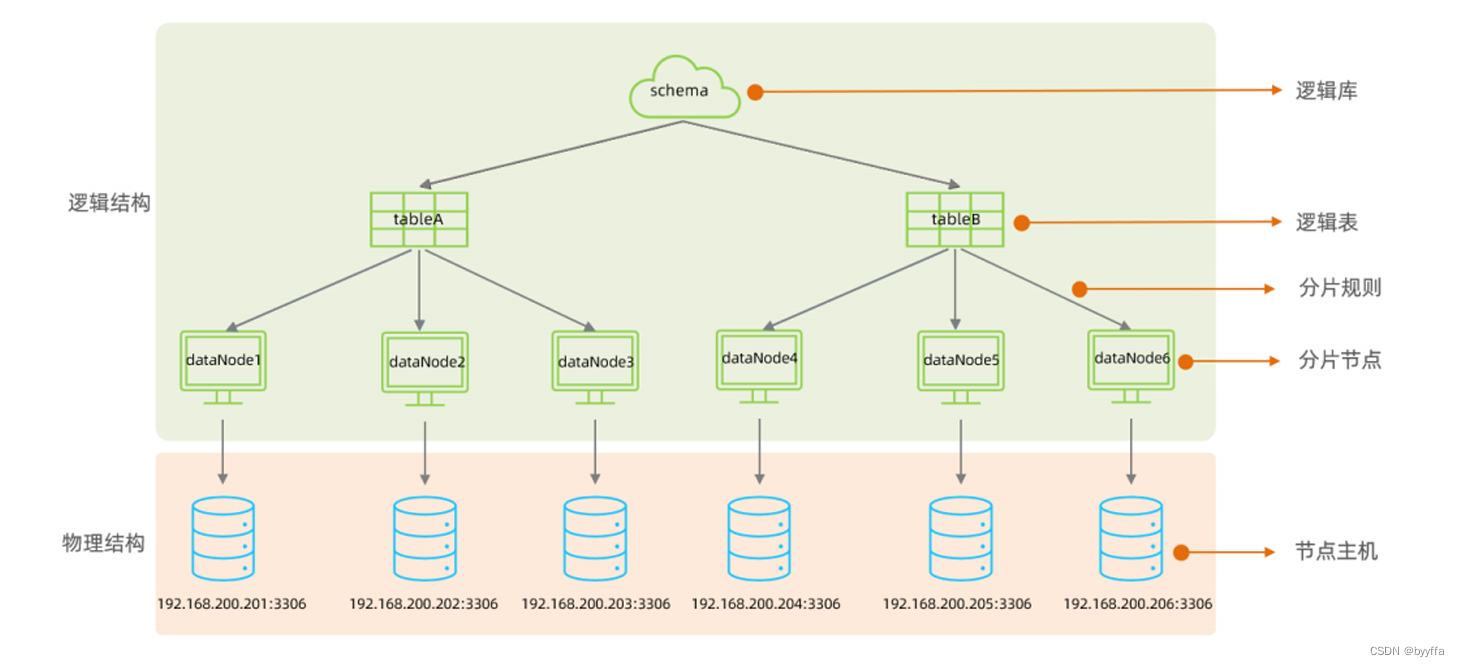
在MyCat的整体结构中,分为两个部分:上面的逻辑结构、下面的物理结构
1.1为什么要读写分离
① 面对越来越大的访问压力,单台的服务器的性能成为瓶颈,需要分担负载
② 主从只负责各自的写和读,极大程度的缓解 X 锁和S 锁争用
③ 从库可配置myisam 引擎,提升查询性能以及节约系统开销
④ 增加冗余,提高可用性
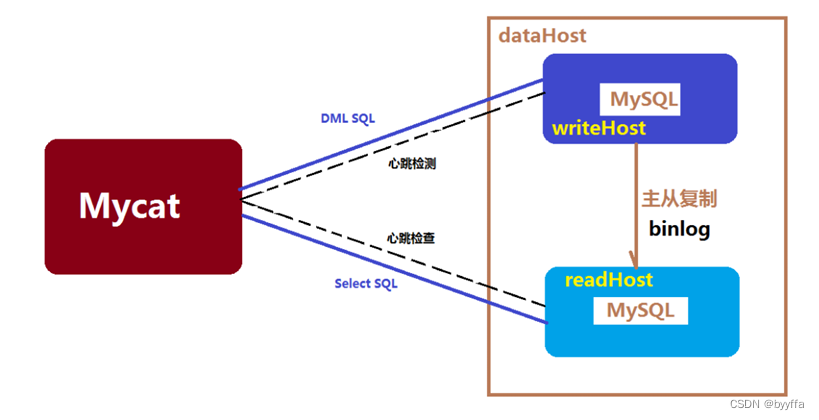
1.2读写分离工作原理
基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理 SELECT 查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库
1.3配置文件
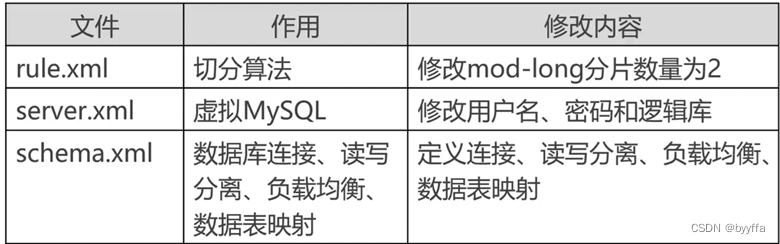
schema.xml
schema
name:对应Server.xml中配置的逻辑库名TESTDB
checkSQLschema:在SQL语句操作时指定了数据库名称,执行时是否自动去除;true:自动去 除,false:不自动去除。当该值设置为true时,如果我们执行语句select * from TESTDB.travelrecord;则MyCat会把语句修改为select * from travelrecord;即把表示schema的字 符去掉,避免发送到后端数据库执行时报(ERROR 1146 (42S02): Table ‘testdb.travelrecord’ doesn’t exist)。
sqlMaxLimit:当该值设置为某个数值时。每条执行的SQL语句,如果没有加上limit语句,MyCat 也会自动的加上所对应的值。例如设置值为100,执行select * from TESTDB.travelrecord;的效果 为和执行select * from TESTDB.travelrecord limit 100;相同设置该值的话,MyCat默认会把查询 到的信息全部都展示出来,造成过多的输出。所以,在正常使用中,还是建议加上一个值,用于减 少过多的数据返回。当然SQL语句中也显式的指定limit的大小,不受该属性的约束。需要注意的 是,如果运行的schema为非拆分库的,那么该属性不会生效。需要手动添加limit语句。
dataNode:同时存在,指定默认存储节点,比如建表默认会创建到该节点下,对应dataNode下的 name属性
dataNode
name:节点名称,可随意填写
dataHost:对应dataHost标签中name属性值
database:真实Mysql服务中创建的数据库名称
dataHost
name:主机名称,可随意填写
maxCon:指定每个读写实例连接池的最大连接。也就是说,标签内嵌套的writeHost、readHost 标签都会使用这个属性的值来实例化出连接池的最大连接数。
minCon:指定每个读写实例连接池的最小连接,初始化连接池的大小。
balance:负载均衡类型,目前的取值有3种: balance=”0″, 不开启读写分离机制,所有读操作都 发送到当前可用的writeHost上。 balance=”1″,全部的readHost与stand by writeHost参与select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且M1与 M2互为主备),正常 情况下,M2,S1,S2都参与select语句的负载均衡。balance=”2″,所有读操作都随机的在 writeHost、readhost上分发。balance=”3″,所有读请求随机的分发到wiriterHost对应的 readhost执行,writerHost不负担读压力,注意balance=3只在1.4及其以后版本有,1.3没有。
writeType:负载均衡类型,目前的取值有3种:writeType=”0″, 所有写操作发送到配置的第一个 writeHost,第一个挂了切到还生存的第二个writeHost,重新启动后已切换后的为准,切换记录在 配置文件中:dnindex.properties,writeType=”1″,所有写操作都随机的发送到配置的writeHost, 1.5以后废弃不推荐。
dbType:指定后端连接的数据库类型,目前支持二进制的mysql协议,还有其他使用JDBC连接的 数据库。例如:mongodb、oracle、spark等。
dbDriver:指定连接后端数据库使用的Driver,目前可选的值有native和JDBC。使用native的话, 因为这个值执行的是二进制的mysql协议,所以可以使用mysql和maridb。其他类型的数据库则需 要使用JDBC驱动来支持。从1.6版本开始支持postgresql的native原始协议。 如果使用JDBC的话需 要将符合JDBC 4标准的驱动JAR包放到MYCAT\lib目录下,并检查驱动JAR包中包括如下目录结构的 文件:META-INF\services\java.sql.Driver。在这个文件内写上具体的Driver类名,例如: com.mysql.jdbc.Driver。
switchType: -1 表示不自动切换 1 默认值,自动切换 2 基于MySQL主从同步的状态决定是否切 换 心跳语句为 show slave status 3 基于MySQL galary cluster的切换机制(适合集群)(1.4.1) 心跳语句为 show status like ‘wsrep%’
heartbeat :这个标签内指明用于和后端数据库进行心跳检查的语句。例如,MYSQL可以使用select user(),Oracle可 以使用select 1 from dual等。
这个标签还有一个connectionInitSql属性,主要是当使用Oracla数据库时,需要执行的初始化SQL语句 就这个放到这里面来。例如:alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss',1.4主从 切换的语句必须是:show slave status
writeHost(写主机)、readHost(读主机): 这两个标签都指定后端数据库的相关配置给mycat,用于实例化后端连接池。唯一不同的是,writeHost 指定写实例、readHost指定读实例,组着这些读写实例来满足系统的要求。
在一个dataHost内可以定义多个writeHost和readHost。但是,如果writeHost指定的后端数据库宕 机,那么这个writeHost绑定的所有readHost都将不可用。另一方面,由于这个writeHost宕机系统会自 动的检测到,并切换到备用的writeHost上去。
2.部署mycat
# 安装1.8以下jdk
# 1.下载mycat
https://github.com/MyCATApache/Mycat-download/blob/master/1.6-RELEASE/Mycatserver-1.6-RELEASE-20161028204710-linux.tar.gz
# 2.解压mycat
tar -zxvf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
2.1配置mycat中conf下的配置schema.xml
<!-- 定义MyCat的逻辑库 -->
<schema name="test_schema" checkSQLschema="false" sqlMaxLimit="100"
dataNode="testNode"></schema>
<!-- 定义MyCat的数据节点 dtHost为mysql集群名 database为真实数据库名-->
<dataNode name="testNode" dataHost="dtHost" database="test1" />
<dataHost name="dtHost" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="-1"
slaveThreshold="100">
<!-- 心跳检测,检测服务器是否宕机 -->
<heartbeat>select user()</heartbeat>
<!--写节点-->
<writeHost host="hostM1" url="192.168.19.60:3306" user="root"
password="Admin@123">
<!--从节点-->
<readHost host="hostS1" url="192.168.19.61:3306"
user="root" password="Admin@123" />
</writeHost>
</dataHost>2.2配置登陆mycat的权限server.xml
<!-- name为mycat的用户名-->
<user name="root">
<property name="password">root</property>
<!-- schemas中的数据库名是schema.xml中schema标签的name属性-->
<property name="schemas">test_schema</property>
</user>注意:如果就一个用户,需要手动把文件自带的用户配置信息删到,这样不会报错。
2.3启动mycat
进入bin目录
./mycat console2.4查看日志
tail -f ../logs/mycat.log数据库连接配置,测试 mycat端口实例默认8066
3.rule.xml
rule.xml中定义所有拆分表规则,在使用过程中可以灵活的使用分片算法,或者对同一个分片算法使用 不同的参数,它让分片过程所配置化
分片一共有三种:范围分片,取模分片,一致性hash
3.1范围分片
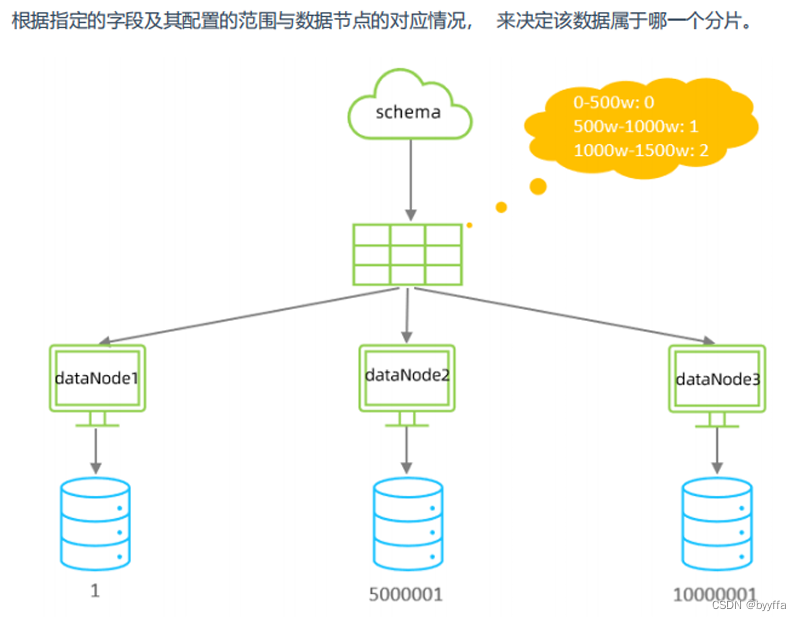
在分片的时候我们指定了columns id字段进行分片,并且指定了算法algorithm rang-long
如果我们想自定义范围,我们只需要修改autopartition-long.txt文件
例子
#schema配置
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="test_schema" checkSQLschema="true" sqlMaxLimit="100"
>
<table name="ababa" dataNode="testNode1,testNode2" rule="auto-sharding-long" />
</schema>
<dataNode name="testNode1" dataHost="dtHost1" database="ccc" />
<dataNode name="testNode2" dataHost="dtHost2" database="ccc" />
<dataHost name="dtHost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="-1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!--写节点-->
<writeHost host="hostM1" url="192.168.99.50:3306" user="lpd"
password="1234">
<!--从节点-->
<readHost host="hostS1" url="192.168.99.51:3306"
user="root" password="1234" />
</writeHost>
</dataHost>
<dataHost name="dtHost2" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="-1"
slaveThreshold="100">因为这题我们只有两个分组,只需要两个,我们把第三个注释了
vim autopartition-long.txt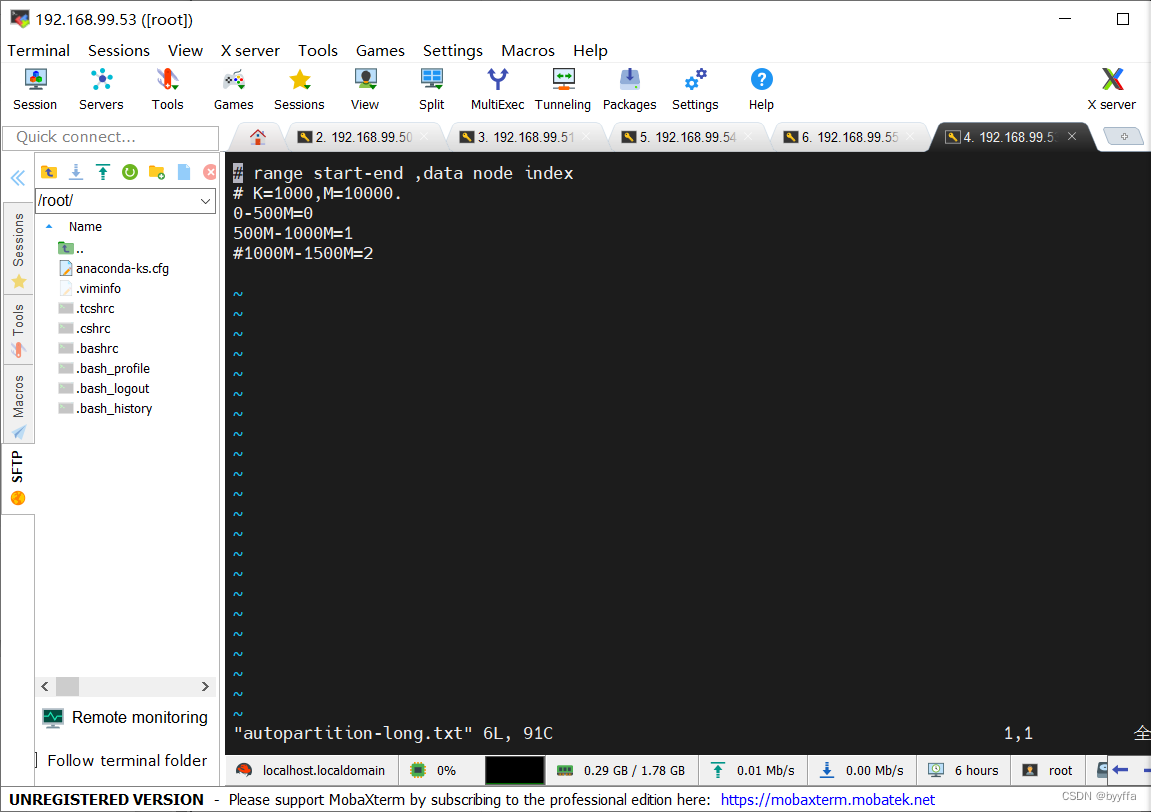
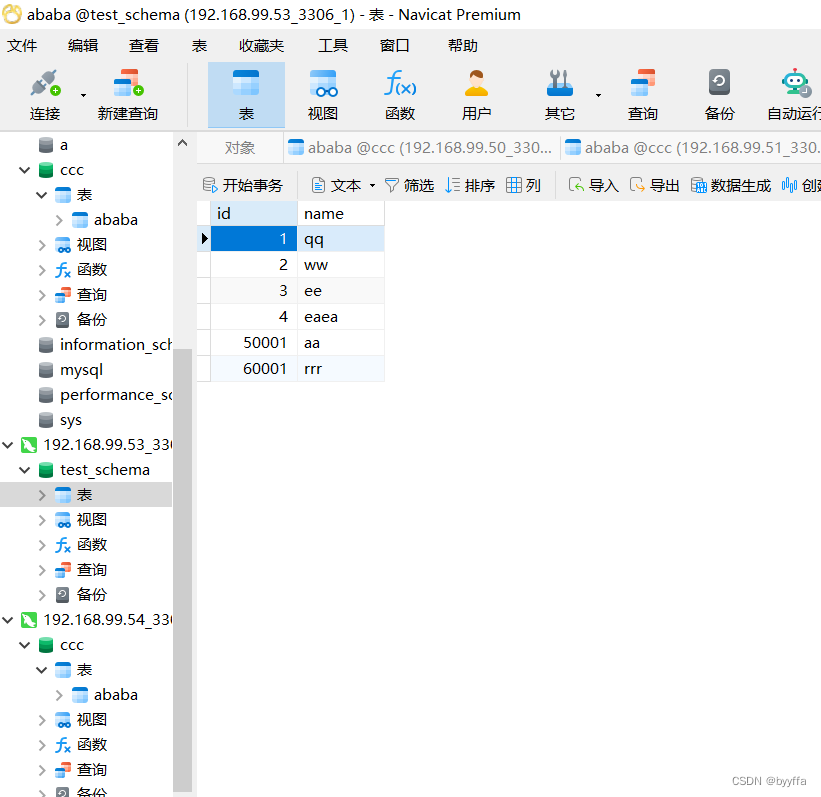
测试
我们登陆mycat,可以看见他把第一个数据库的内容和第二个数据库内容组合在一起了
我们添加一个500001的数据
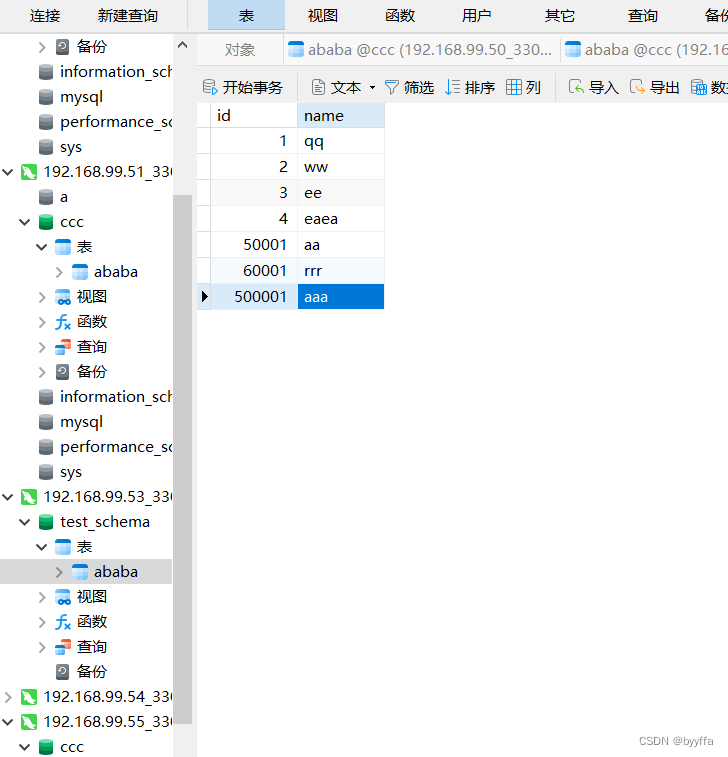
我们可以发现数据在第二组数据库中添加,没有在第一组
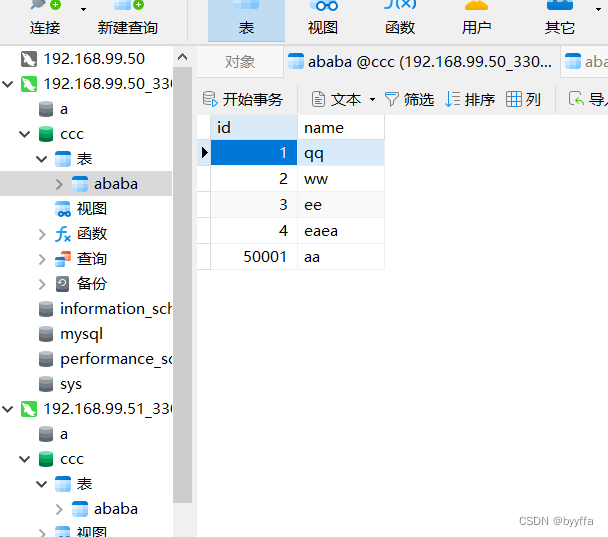
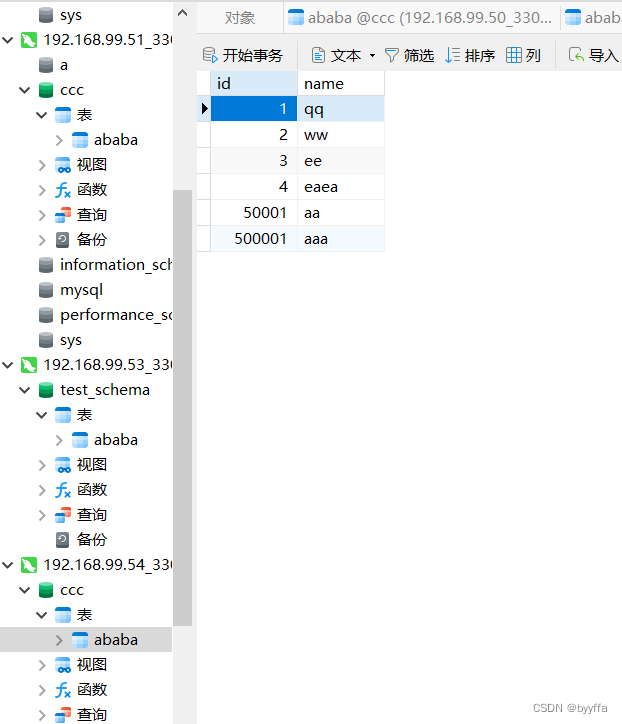
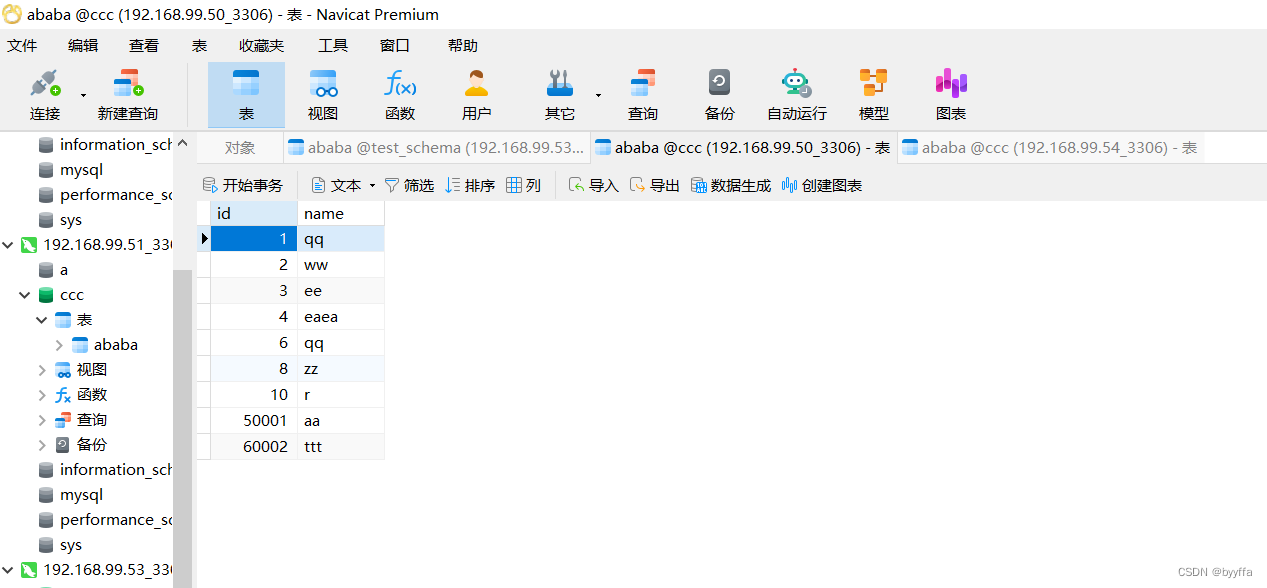
相反我们添加一个60001的数据,他会按分组在第一组添加,第二组没有
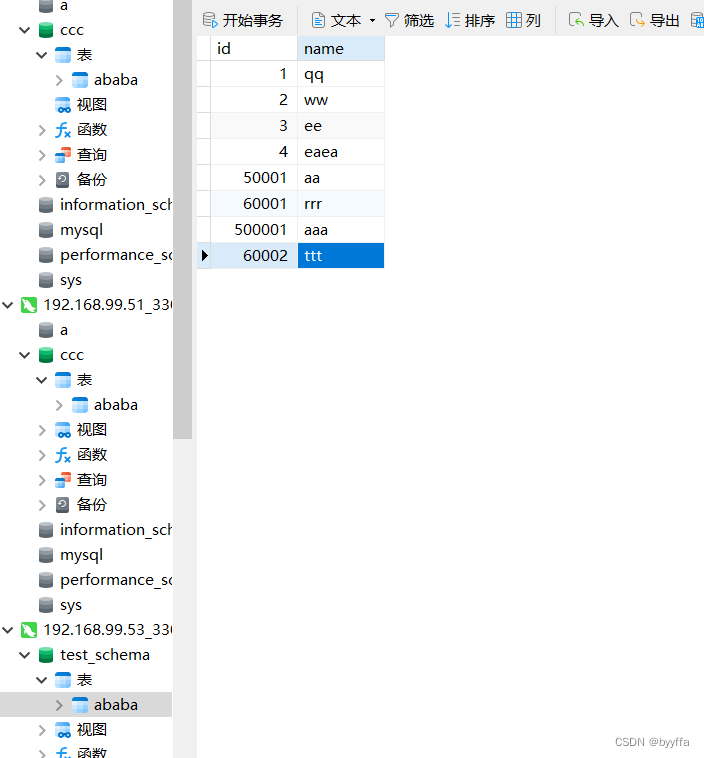

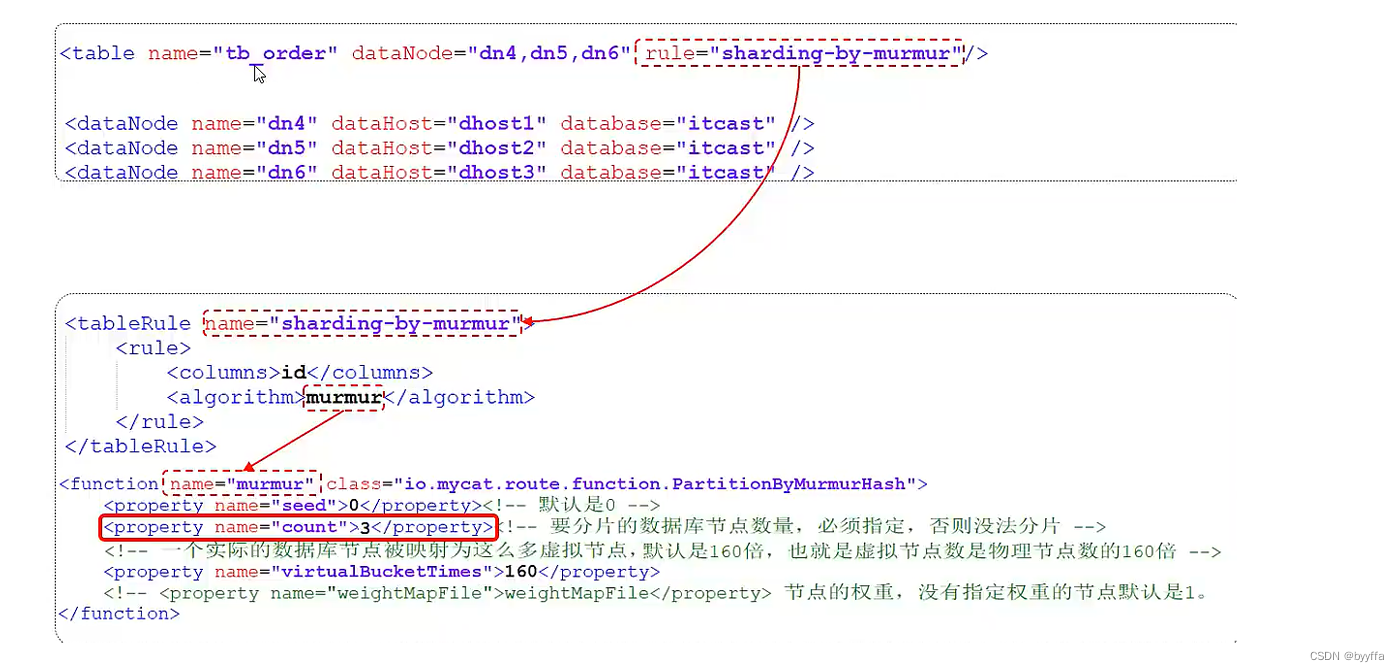
 3.2取模分片
3.2取模分片
根据指定的字段值与节点数量进行求模运算,根据运算结果, 来决定该数据属于哪一个分片
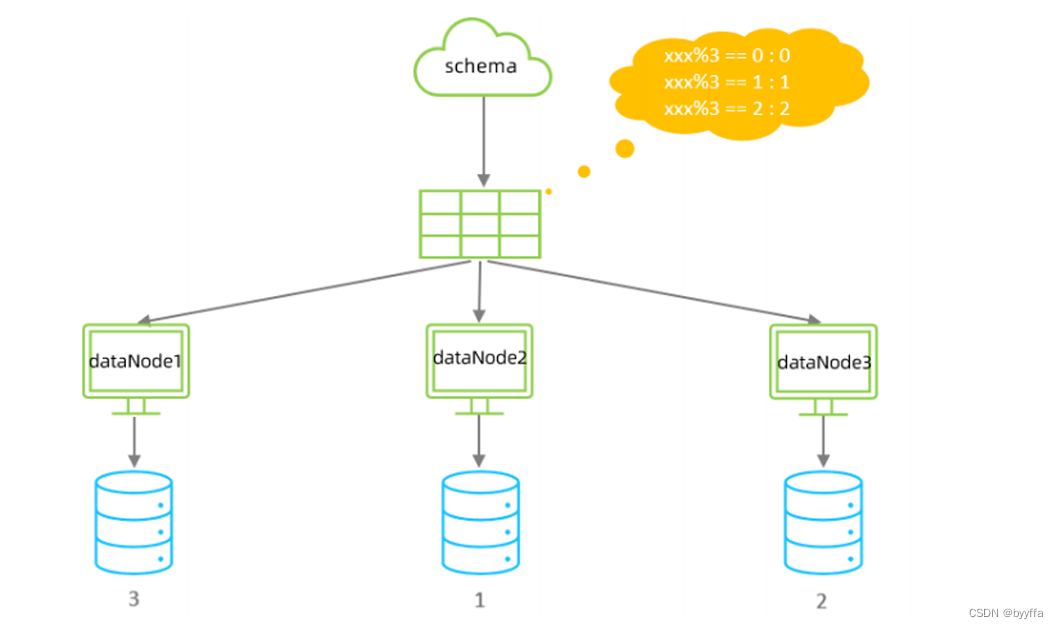
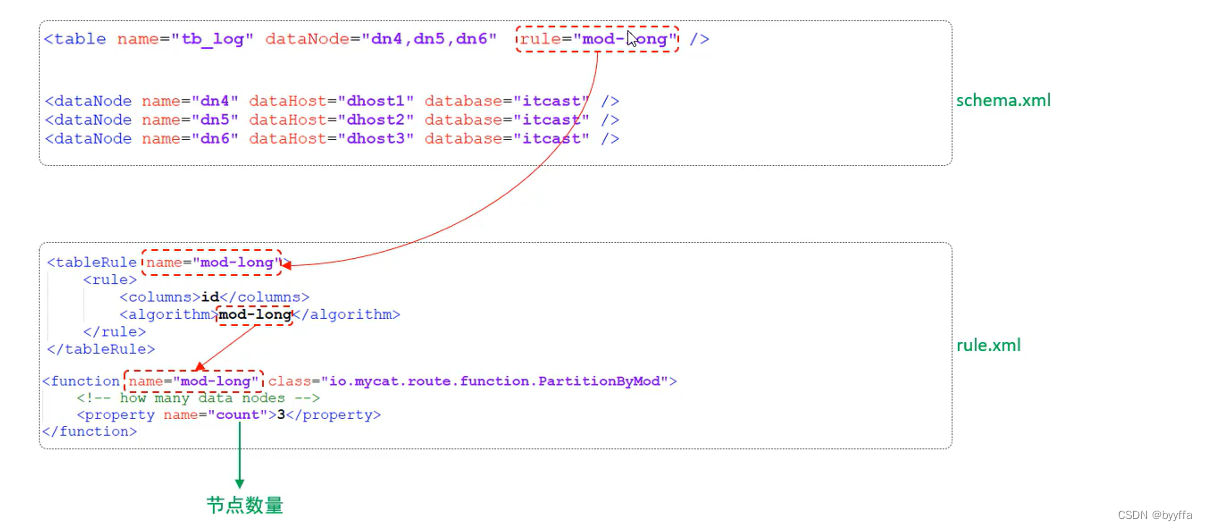
测试
按id号%2取,整数走一,余数走2
加个五,走2
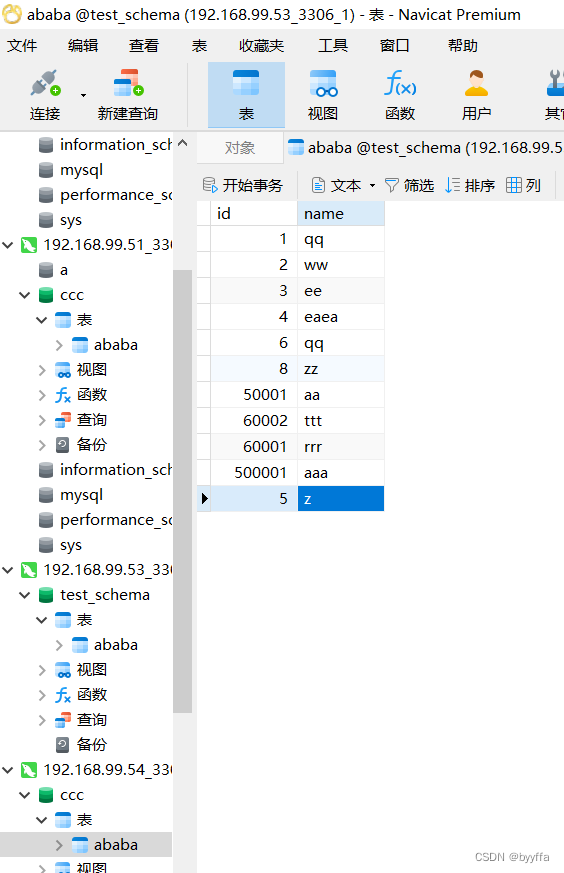
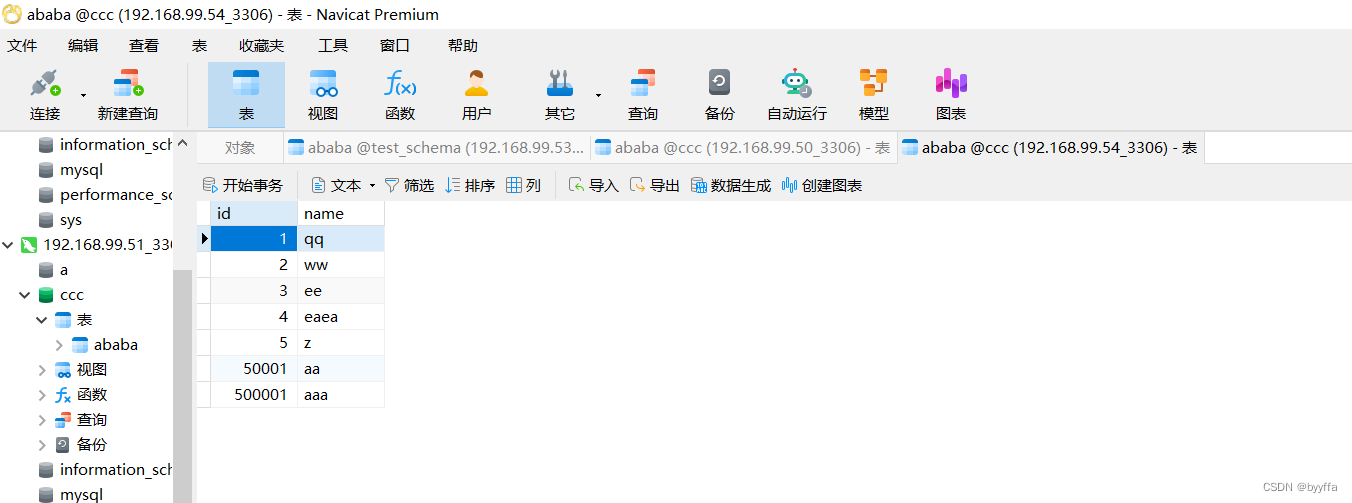
加10走1
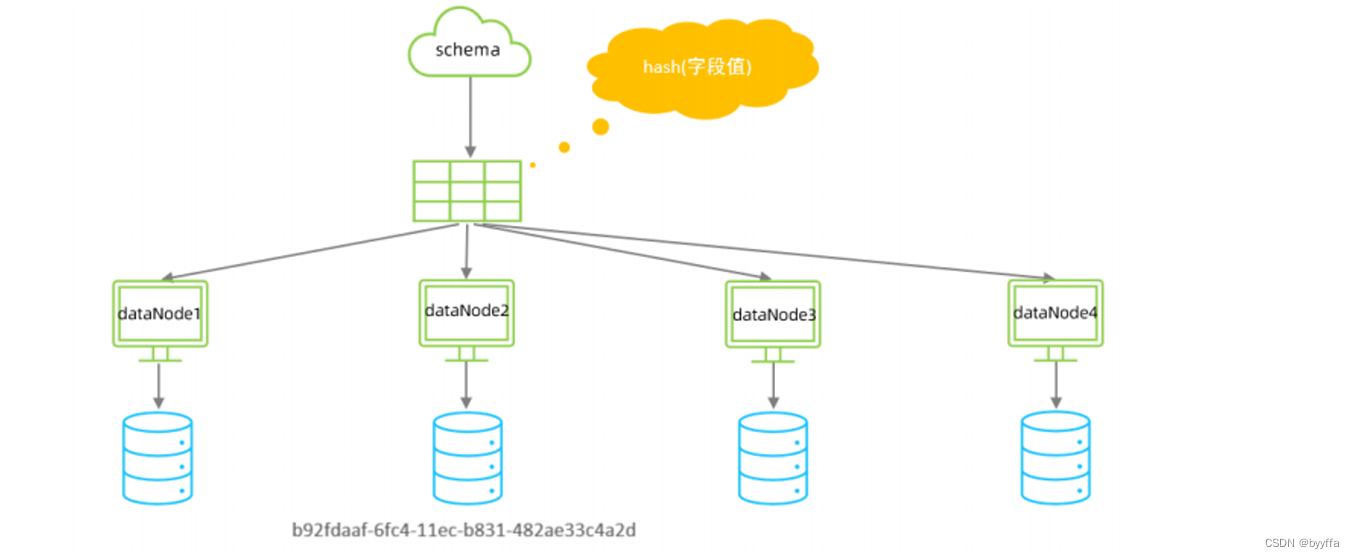
 3.3一致性hash
3.3一致性hash
在进行分片操作的时候会计算我们所指定的字段的哈希值,然后根据字段的哈希值来决定当前这条记录 到底应该落在哪一个数据节点上。
我们再增加一个节点,只要我们的id相同,就会放在同一个分片当中,所以不用担心增加分片后,相同 的数据会不会落在同一个分片的问题。















 2561
2561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









