







re元字符说明
'.'
点号,在普通模式,它匹配除换行符外的任意一个字符;如果指定了 DOTALL 标记,匹配包括换行符以内的任意一个字符。
'^'
尖尖号,匹配一个字符串的开始,在 MULTILINE 模式下,也将匹配任意一个新行的开始。
'$'
美元符号,匹配一个字符串的结尾或者字符串最后面的换行符
'*'
星号,指定将前面的RE重复0次或者任意多次,而且总是试图尽量多次地匹配。
'+'
加号,指定将前面的RE重复1次或者任意多次,而且总是试图尽量多次地匹配。
'?'
问号,指定将前面的RE重复0次或者1次,如果有的话,也尽量匹配1次。
*?, +?, ??
从前面的描述可以看到'*','+'和'?'都是贪婪的,所以,可以在后面加个问号,将策略改为非贪婪,只匹配尽量少的RE
{m,n}
m和n都是数字,指定将前面的RE重复m到n次,例如a{3,5}匹配3到5个连续的a。注意,如果省略m,将匹配0到n个前面的RE;如果省略n,将匹配n到无穷多个前面的RE;当然中间的逗号是不能省略的,不然就变成前面那种形式了。
{m,n}?
前面说的{m,n},也是贪婪的,a{3,5}如果有5个以上连续a的话,会匹配5个,这个也可以通过加问号改变。a{3,5}?如果可能的话,将只匹配3个a。
'\'
反斜杆,转义'*','?'等特殊字符,或者指定一个特殊序列(下面会详述)
由于之前所述的原因,强烈建议用raw字符串来表述正则。
[]
方括号,用于指定一个字符的集合。可以单独列出字符,也可以用'-'连接起止字符以表示一个范围。特殊字符在中括号里将失效,比如[akm$]就表示字符'a','k','m',或'$',在这里$也变身为普通字符了。[a-z]匹配任意一个小写字母,[a-zA-Z0-9]匹配任意一个字母或数字。
注意:在中括号里,+、*、(、)这类字符将会失去特殊含义,仅作为普通字符。反向引用也不能在中括号内使用。
'|'
管道符号,A和B是任意的RE,那么A|B就是匹配A或者B的一个新的RE。任意个数的RE都可以像这样用管道符号间隔连接起来。
(...)
匹配圆括号里的RE匹配的内容,并指定组的开始和结束位置。组里面的内容可以被提取,也可以采用\number这样的特殊序列,被用于后续的匹配。要匹配字面意义上的'('和')',可以用反斜杆转义:\(、\),或是包含在反括号内:[(]、[)]。
re.I
re.IGNORECASE
让正则表达式忽略大小写,这样一来,[A-Z]也可以匹配小写字母了。此特性和locale无关。
re.L
re.LOCALE
让\w、\W、\b、\B、\s和\S依赖当前的locale。
re.M
re.MULTILINE
影响'^'和'$'的行为,指定了以后,'^'会增加匹配每行的开始(也就是换行符后的位置);'$'会增加匹配每行的结束(也就是换行符前的位置)。
re.S
re.DOTALL
影响'.'的行为,平时'.'匹配除换行符以外的所有字符,指定了本标志以后,也可以匹配换行符。
re.U
re.UNICODE
让\w、\W、\b、\B、\d、\D、\s和\S依赖Unicode库。
re.X
re.VERBOSE
运用这个标志,你可以写出可读性更好的正则表达式:除了在方括号内的和被反斜杠转义的以外的所有空白字符,都将被忽略,而且每行中,一个正常的井号后的所有字符也被忽略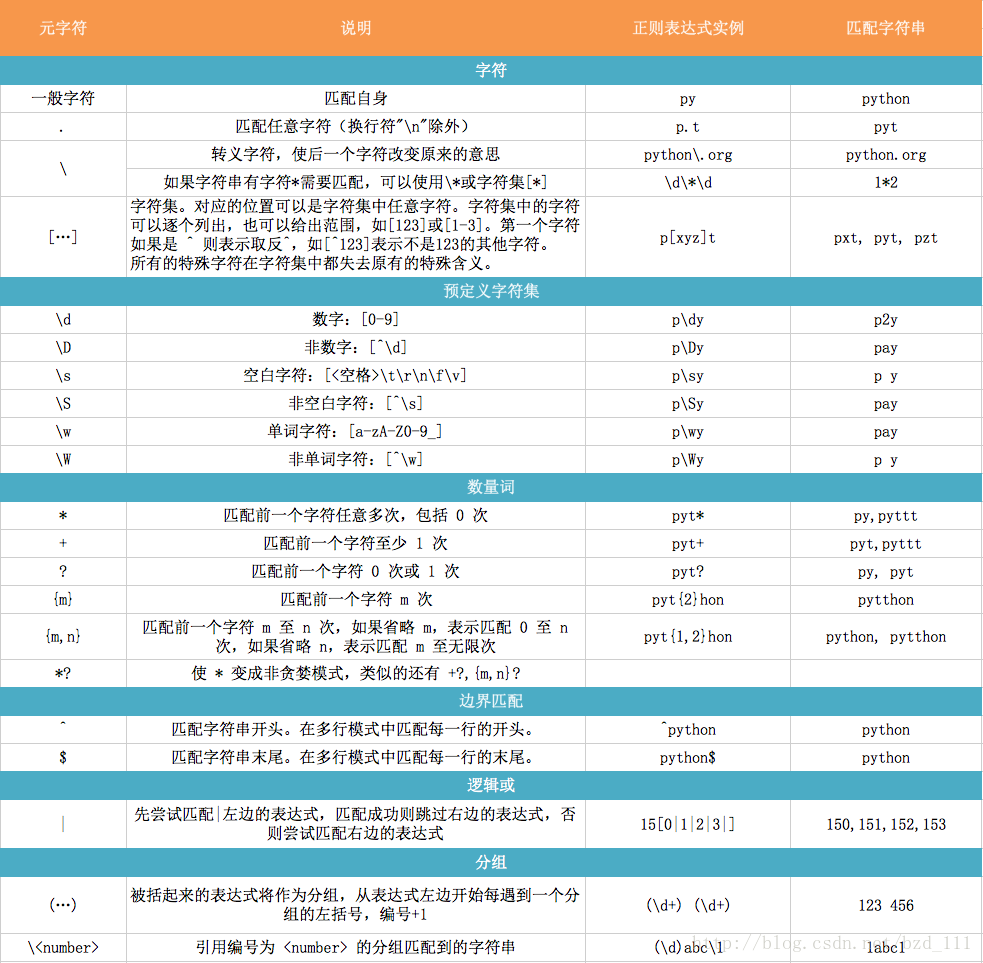
使用习惯
一种是直接匹配
In [9]: result = re.match(r"hello,\w+","hello,world")
In [10]: result
Out[10]: <_sre.SRE_Match at 0x4288f38>
一种是通过编译,再使用
In [24]: regex = re.compile(r"hello,\w+")
In [25]: result = regex.match("hello,world")
In [26]: result.groups()
Out[26]: ()
In [27]: result.group()
Out[27]: 'hello,world'
In [28]: result.groups?
Docstring:
groups([default=None]) -> tuple.
Return a tuple containing all the subgroups of the match, from 1.
The default argument is used for groups
that did not participate in the match
Type: builtin_function_or_method
In [29]: result.group?
Docstring:
group([group1, ...]) -> str or tuple.
Return subgroup(s) of the match by indices or names.
For 0 returns the entire match.
Type: builtin_function_or_method
In [30]: regex = re.compile(r"hello,(\w+)")
In [31]: result = regex.match("hello,world")
#返回值是一个tuple
In [32]: result.groups()
Out[32]: ('world',)
#返回值是tuple或者str
In [33]: result.group()
Out[33]: 'hello,world'
第二种编译好的比第一种运行的时间快,而且可以重复使用编译好的正则对象
简单例子
匹配日期
In [3]: regex = re.compile("(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})")
In [6]: result =regex.match("2017-01-12")
In [7]: result.group()
Out[7]: '2017-01-12'
In [8]: result.group(1)
Out[8]: '2017'
In [9]: result.group(2)
Out[9]: '01'
In [10]: result.group(3)
Out[10]: '12'
In [12]: result.group("year")
Out[12]: '2017'
In [13]: result.group("day")
Out[13]: '12'
In [16]: result.groupdict()
Out[16]: {'day': '12', 'month': '01', 'year': '2017'}
匹配用户名
In [50]: re.match("^[a-zA-Z0-9]{3,16}$","avz123").group()
Out[50]: 'avz123'匹配邮箱
In [76]: re.match("^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$",'1234567890@qq.com').group()
Out[76]: '1234567890@qq.com'匹配url链接
In [78]: regex = re.compile(r'^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w\.-]*)\/?$',re.X)
In [79]: regex.match('www.baidu.com')
Out[79]: <_sre.SRE_Match at 0x423bf48>
In [80]: regex.match('www.baidu.com').group()
Out[80]: 'www.baidu.com'
In [82]: regex.match('http://www.baidu.com').group()
Out[82]: 'http://www.baidu.com'
In [83]: regex.match('https://www.baidu.com').group()
Out[83]: 'https://www.baidu.com'
In [84]: regex.match('https://www.baidu.com/2.html').group()
Out[84]: 'https://www.baidu.com/2.html'
匹配IPv4地址
In [92]: regex = re.compile(r'''^(?:(?:25[0-5]
...: |2[0-4][0-9]
...: |[1]?[0-9][0-9]?)\.){3}
...: (?:25[0-5]
...: |2[0-4][0-9]
...: |[1]?[0-9][0-9]?)$''', re.X)
In [93]: regex.match("10.1.10.22").group()
Out[93]: '10.1.10.22'
In [94]: regex.match("255.255.255.0").group()
Out[94]: '255.255.255.0'
In [95]: regex.match("255.255.256.0").group()
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-95-c87c2f8f246d> in <module>()
----> 1 regex.match("255.255.256.0").group()
AttributeError: 'NoneType' object has no attribute 'group'
匹配MAC地址
In [96]: import random
In [97]: mac = [random.randint(0x00,0x7f),]
In [98]: mac = [random.randint(0x00,0x7f),]
In [99]: mac = [random.randint(0x00,0x7f),]
In [100]: mac = [random.randint(0x00,0x7f),
...: random.randint(0x00,0x7f),
...: random.randint(0x00,0x7f),
...: random.randint(0x00,0x7f),
...: random.randint(0x00,0x7f),
...: random.randint(0x00,0x7f)]
In [101]: mac =":".join(map(lambda x:"%02x" %x,mac))
In [102]: mac
Out[102]: '73:76:22:01:29:6d'
In [105]: regex = re.compile(r"""[0-9a-f]{2}([:])
...: [0-9a-f]{2}
...: (\1[0-9a-f]{2}) {4}$""",re.X)
In [106]: regex.match(mac).group()
Out[106]: '73:76:22:01:29:6d'匹配运算符
In [107]: import re
...: from collections import namedtuple
...: tokens = [r'(?P<NUMBER>\d+)',
...: r'(?P<PLUS>\+)',
...: r'(?P<MINUS>-)',
...: r'(?P<TIMES>\*)',
...: r'(?P<DIVIDE>/)',
...: r'(?P<WS>\s+)']
...: lex = re.compile('|'.join(tokens))
...: Token = namedtuple('Token', ['type', 'value'])
...: def tokenize(text):
...: scan = lex.scanner(text)
...: return (Token(m.lastgroup, m.group())
...: for m in iter(scan.match, None) if m.lastgroup != 'WS')
...:
...: for _t in tokenize('1 + 2* 3 - 4'):
...: print(_t)
...:
Token(type='NUMBER', value='1')
Token(type='PLUS', value='+')
Token(type='NUMBER', value='2')
Token(type='TIMES', value='*')
Token(type='NUMBER', value='3')
Token(type='MINUS', value='-')
Token(type='NUMBER', value='4')
修改时间格式
In [112]: re.sub(r"(\d{4})-(\d{2})-(\d{2})",r"\2/\3/\1","2017-01-12")
Out[112]: '01/12/2017'
In [114]: re.sub(r"(\d{4})-(\d{2})-(\d{2})",r"[\2/\3/\1]","2017-01-12")
Out[114]: '[01/12/2017]'
In [113]: re.sub(r"(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})",r"\g<month>/\g<day>/\g<year>","2017-01-12")
Out[113]: '01/12/2017'
匹配时使用函数
In [115]: s = "<@U1EAT8MG9>, <@U0K1MF23Z>"
...: ID_NAMES = {'U1EAT8MG9': 'zxc', 'U0K1MF23Z': 'zdy'}
...: REGEX_AT = re.compile(r'\<@.*?\>')
...: def id_to_name(match):
...: content = match.group()
...: name = ID_NAMES.get(content[2:-1])
...: return '@{}'.format(name) if name else content
...:
...: print REGEX_AT.sub(id_to_name, s)
...:
@zxc, @zdy参考资料
python正则表达式re模块详细介绍
Python正则备忘单
Python Regular Expression cheatsheet















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









