 流程挖掘:数据获取与事件日志处理详解
流程挖掘:数据获取与事件日志处理详解





 本文详细阐述了流程挖掘中的关键环节,如数据源的抽取、转换和装载,事件日志的结构、XES文件的特性以及在实际应用中的挑战,特别关注了非扁平业务过程实例中的数据整合和视图选择。
本文详细阐述了流程挖掘中的关键环节,如数据源的抽取、转换和装载,事件日志的结构、XES文件的特性以及在实际应用中的挑战,特别关注了非扁平业务过程实例中的数据整合和视图选择。
第四章-数据获取——流程挖掘(Process Mining)
流程挖掘离不开有效的事件日志,事件日志是多种多样的,比如数据库、文本文件、消息日志、事务日志、ERP系统和文件系统等。同时在整合和获取数据的过程中,语义和语法扮演着重要的角色。因此本章学习我打算从数据源、事件日志、日志语法、实例学习的几个角度进行学习,参考的教材是Process Mining。
4.1数据源
数据源可以是简单的文本文件、Excel表格、事务日志或者数据库表等。其实所有数据往往并不来自于单一的结构良好的数据源,而是分布在不通过的数据源当中。针对跨部门的过程挖掘,可以通过监听消息交换,记录读写活动来捕获事件。
“抽取、转换、装载”的步骤:
- 从外部数据源抽取数据;
- 根据业务目标进行数据转换(在保证预定义的质量水平的前提下进行语义和语法上的处理);
- 将数据加载到目标系统,如数据仓库或者关系型数据库中;
数据挖掘通常情况下需要使用顺序的信息。
4.2 事件日志
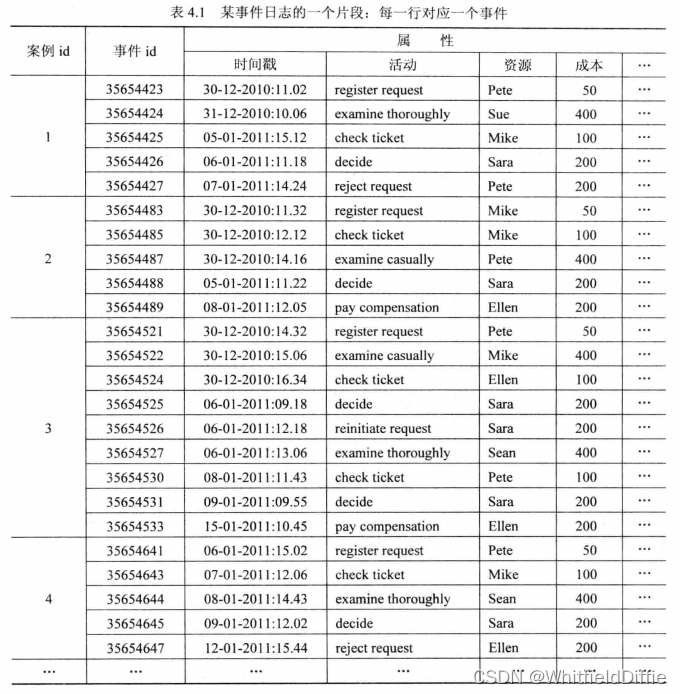
下表描述了一段用于过程挖掘的事件日志中的信息。
案例:日志中的每个事件都需要对应到一个过程实例当中,即过程的一次执行。例如下标的案例1;
事件:指如register request、check ticket、reject等。
过程挖掘模型,通常都会将过程设计成为一系列活动的集合,而这些活动描述了一个实例的生命周期。因此下表中的案例id和活动项都是必须的。并且案例中的事件还必须是有时间顺序的。如果日志中不包含事件顺序信息,则无法发现过程模型中的依赖关系。
事件日志的树形结构
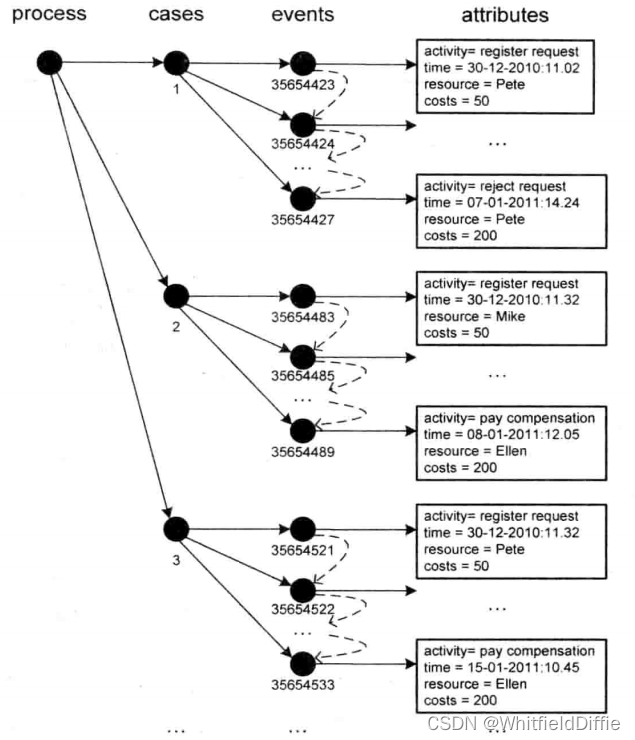
- 过程是由案例组成的。
- 案例是由事件组成的,且每一个事件仅属于一个案例。
- 案例中事件是有序的。
- 事件具有属性,典型的属性包括活动、时间戳、成本和资源。
4.3 XES
需要知道的几个标准与标记语言:
MXML:Mining eXtensible Markup Language,挖掘可扩展标记语言。基于XML语法。有一套存储时间戳,资源和事务类型的标准标记。可进行自定义扩展,例如SA-MXML(Semantically Annotated Mining eXtensible Markup Language,语义注释的面向挖掘的可扩展标记语言)是被ProM框架使用的MXML格式的语义注释版本,里面包含日志中的元素
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1102
1102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









