







 本文介绍了流程挖掘中的启发式挖掘技术,通过因果网和依赖图表示活动间的关联,强调了频次在模型构建中的重要性。作者展示了如何通过事件日志分析和阈值设置来提取和优化C-net模型,包括考虑罕见和频繁路径,以及模糊挖掘和层次模型的应用。
本文介绍了流程挖掘中的启发式挖掘技术,通过因果网和依赖图表示活动间的关联,强调了频次在模型构建中的重要性。作者展示了如何通过事件日志分析和阈值设置来提取和优化C-net模型,包括考虑罕见和频繁路径,以及模糊挖掘和层次模型的应用。
第九讲-流程挖掘(Process Mining)学习日志之启发式挖掘
概述
通过使用一种类似因果网的表示法描述启发式挖掘算法。 此外,在构建过程模型时考虑事件和序列的频次,基本思想是不频繁的路径不应该被纳入模型中。因果网提供的表示偏好以及频次的使用都使得这一方法比其他多数方法更加健壮。
1 因果网
因果网,也称为C-net 。图6.2展示了C-net的一个例子,图中有一个代表注册保险索赔的开始活动a和一个结束案例的结束活动 e 。活动 a 有 3 个输出绑定 {b,c} 、{d} 和{e},这表明在完成 a 后,可以激活活动 b 和 c、活动 d 或者活动 e 。在分析 C-net 的行为时只考虑有效序列,如果序列满足下面4个条件,那么这个绑定序列是有效的:
- 序列从开始活动 ai=a 为开始;
- 序列以结束活动 ao=e 为结束;
- 只移除待定的合约;
- 结束时没有待定的合约。
假设输出绑定 {b,c} 发生了,在执行 <(a,∅,{b,c}> 之后,有两个待定的合约:(a,b)和(a,c),这意味着未来 b 发生时 a 应该在它的输入绑定中。类似的,c 发生时 a 也应该在 c 的输入绑定中。执行b会移除合约(a,b), 同时创建一个新的合约(b,e),依此类推。一个有效序列的例子是<<a,∅,{b,c}),(b,{a},{e}), (c,{a},{e}),(e,{b,c},∅>,在结束时不存在待定的合约。<(a,∅,{d}),(d,{a},{d}),(d,{d},{e}),(e,{d},∅)> 是另一个有效序列。由于存在一个包含 d 的循环,所以此处存在无数个有效序列。
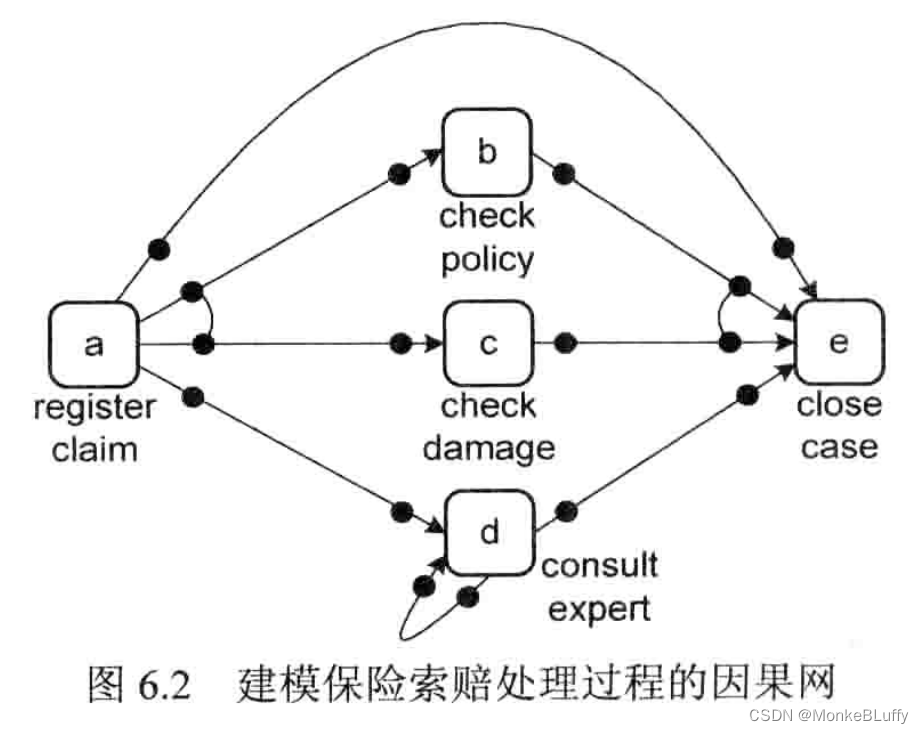
无法使用工作流网(假定所有变迁都有唯一可见标签)来表达图 6.2 建模的过程,这意味着 C-net 是一种更加合适的过程发现表示法。
在原始的启发式挖掘算法中,输入和输出绑定是互斥析取的合取,例如,O(t)={{a,b},{b,c},{b,d}} 意味着 t 会激活 a 或 b、b 或 c 以及 b 或 d,这是排他的或关系。因此,使用提供的 C-net 语义,这对应着O(t)={{a,c,d},{b}},也就是只激活 b 或者激活 a、c 和 d。C-net 比原始的启发式网更加接近直觉并且更具表达能力(在实践意义上), 因此在余下的部分中我们使用C-net。
2 依赖图
我们使用下面这个事件日志来解释启发式挖掘算法用到的基本概念:
L=[<a,e>5,<a,b,c,e>10,<a,c,b,e>10,<a,b,e>1,<a,c,e>1,<a,d,e>10,<a,d,d,e>2,<a,d,d,d,e>1]
如果我们假设频次为 1 的 3 个轨迹都是噪声,那么日志中剩下的 37 个轨迹对应着图 6.2 中 C-net的有效序列。在解释如何获得这一 C-net 之前,我们先将α算法应用到事件日志L上,得到的结果如图6.3所示。
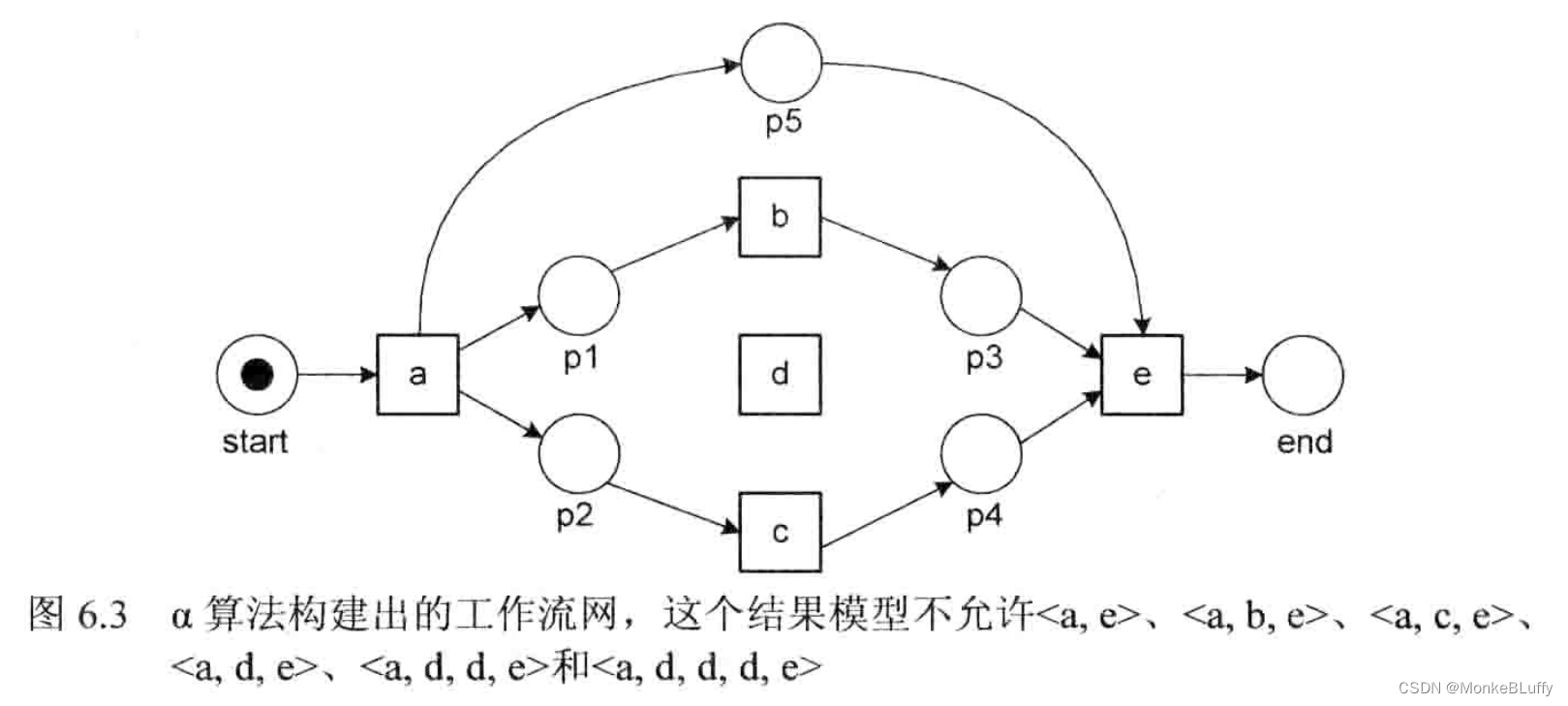
正如我们所预料的,α算法没有挖出合适的模型,这一模型不允许频繁轨迹如<a,e> 和 <a,d,e>,意外的是它同样不允许罕见轨迹如<a,b,e>、<a,c,e>和<a,d,d,e>。对此有两个主要原因:一是α算法的表示偏好不允许跳过活动(例如从 a 跳到 e ),并且无法处理 d 被选中时至少执行一次的要求;二是α算法不考虑频次。因此,我们使用 C-net 并且在启发式挖掘中将频次考虑在内。
表6.1展示了一个活动被另一个活动直接跟随的次数。具体来说,|d>Ld|=4 意味着在整个日志中,d 4次被另一个 d 直接跟随(两次在<a,d,d,e>2中,两次在<a,d,d,d,e>1中)。使用表6.1,我们可以计算任一对活动之间的依赖关系值。
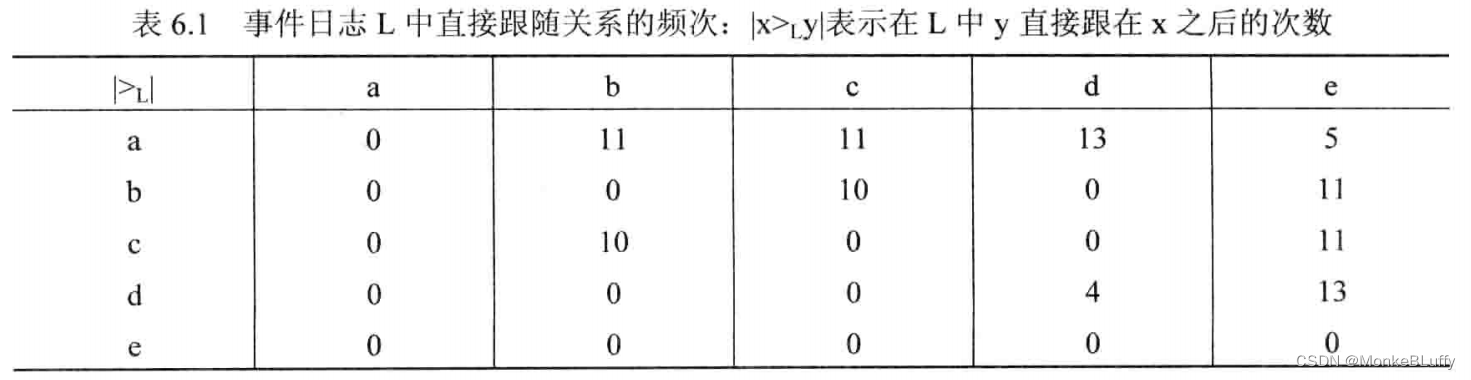

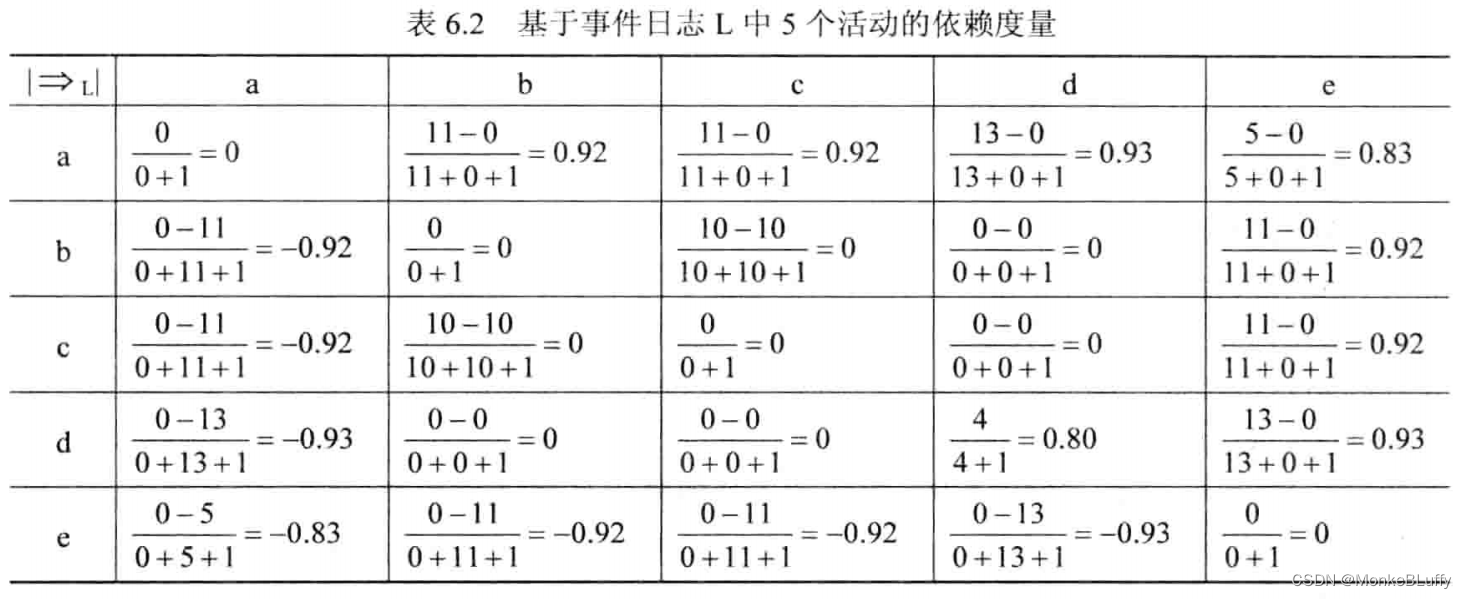
使用表 6.1 和表 6.2 中的信息,可以推出依赖图。在依赖图中,只有满足确定阈值的弧才被展示出来。图6.4中展示的依赖图设定|>L|阈值为2并且 |→L|阈值为0.7,这意味着只有当|x>Lyl≥2 并且x→Lyl≥0.7 时,图中才包含 x 与 y 之间的弧。
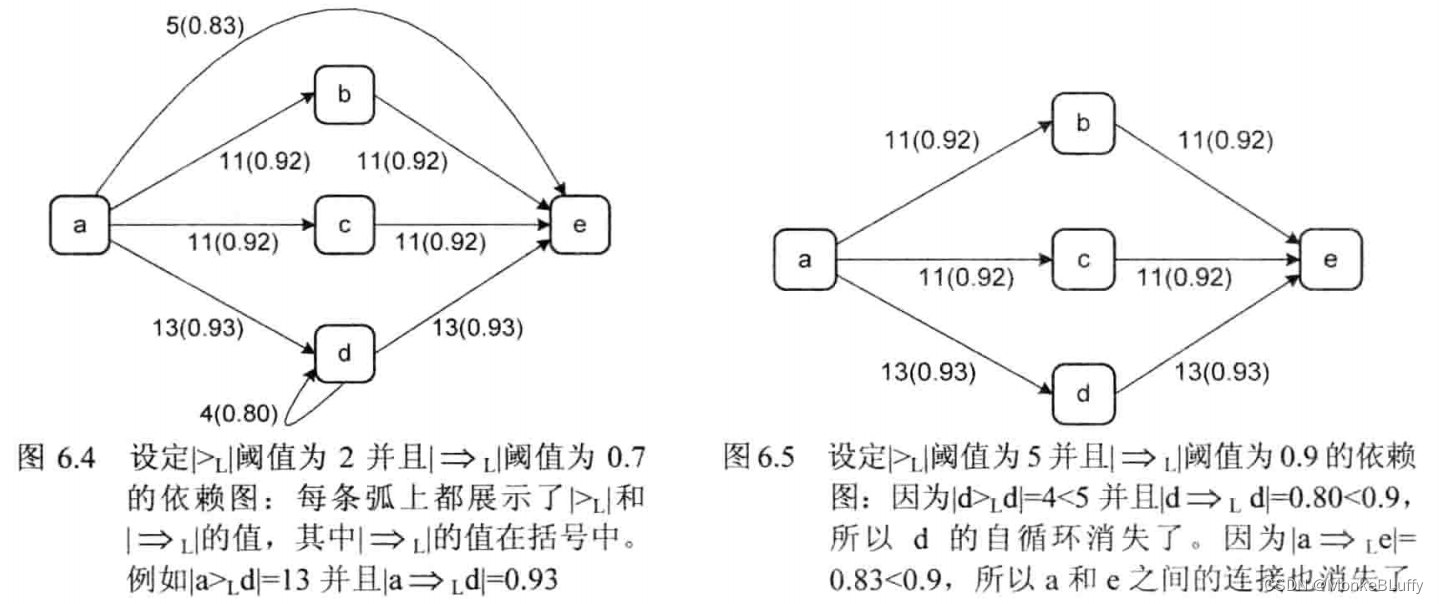
图6.5展示了基于表 6.1 和表 6.2 的另一个依赖图,它使用了更高的阈值,因此有两条弧消失了。显然,依赖图没有展示路由逻辑,例如我们没有看到在 a 之后能够并发执行 b 和 c。尽管如此,依赖图揭示了过程模型的“中枢”。
上面的两张依赖图说明对于给定的事件日志,通过调整阈值可以生成不同的模型,这样用户可以决定只关注主流行为,还是也包含低频次(即噪声)行为。图 6.4 和图 6.5 中的活动集合是相同的,两个阈值无法去掉低频活动(只能去掉低频依赖),低频活动可以通过预处理事件日志来完成这一任务。举例而言,我们可以决定专注于最频繁的活动,并且简单地在计算依赖度量之前从事件日志中移除低频活动。另一些技术,例如模糊挖掘器中使用的技术,在构造依赖图的时候移除低频次的活动。有各种各样的方法可以改进依赖图,例如,可以更好地处理长度为2的循环以及长距离依赖。
3 分裂与合并
启发式挖掘的目标是从事件日志中提取出一个 C-net C=(A,ai,ao,D,I,O)。依赖图的结点对应活动集合 A,依赖图的弧对应依赖关系 D。在一个 C-net 中,有唯一的开始活动 ai 和唯一的结束活动 ao。这只是一个技术问题,我们可以预处理日志然后人工为每个轨迹插入开始和结束事件,因此假设存在一个唯一的开始活动 ai 和唯一的结束活动 ao,并不会带来任何实际限制。事实上,明确的开始和结束可以方便应用。我们也假设在依赖图中,所有的活动都在从 ai 到 ao 的路径上,不在这样的路径上的活动应该被移除,或者阈值应该被局部调整来建立连接的一个最小集合。包含不出现在从 ai 到 ao 的路径上的活动是无意义的:这样的活动可能是死的,或者活跃在案例开始前,总之它们对案例的完成没有贡献。
因此,我们可以假设,在完成依赖图的构建之后,我们已经拥有了目标 C-net 的核心结构:(A,ai,ao,D) 。因此,只需要推出函数I∈A→AS 和 O∈A→AS,就能够完成这个 C-net。
给定一个依赖图(A,ai,ao,D),对于任意 a∈A,我们定义 oa={a`∈A|(a’,a)∈D} 和 ao={a’∈A|(a,a’)∈D} 。显然,I(ai)=O(ao)={φ}。对于任意a≠ai,I(a) 有2|oa|-1个可能的元素;对于任意 a≠a₀,O(a) 有 2|ao|-1个可能的元素。举例来说,考虑图6.4中的依赖图,ao={b,c,d,e},因此O(a) 有2⁴-1=15种可能的输出绑定:{b},{c},{d},{e},{b,c},{b,d},…,{b,c,d,e} 。O(b) 仅有2¹-1=1个可能元素:{e},I(b) 也只有一个可能元素:{a}。O(d) 有2²-1=3种可能的输出绑定:{d} 、{e} 和{d,e},I(d) 也有2²-1=3种可能的输入绑定:{a}、{d}和{a,d}。
如果只有一个可能的绑定元素,那么这个元素应该被采用。因此I(b)={{a}},I©={{a}},O(b)={{e}}并且 O©={{e}}。对其他的输入和输出绑定而言,需要基于事件日志对子集进行选择。为了完成这一任务,需要在依赖图上重演事件日志,观察输出集合被触发得多频繁。以 O(d) 为例,在事件日志 L 中,活动 d 有4次被 d 跟随,有13 次被 e 跟随;d 从不同时被 d 和 e 跟随。因此,作为最频繁的输出绑定,{e}肯定要被包含在O(d)中。{d}也许会被包含,这取决于包含绑定的阈值。如果我们假设这两个可能的绑定都被包含,那么O(d)={{d},{e}}。类似的,我们会得到I(d)={{a},{d}}。让我们考虑O(a),正如之前提到的,它有2⁴-1=15种可能的输出绑定。在依赖图上重演事件日志,可以得到 a 有 5 次被 e 跟随(在轨迹 <a,e>⁵ 中),有20次同时被 b 和 c 跟随(在轨迹<a,b,c,e>10 和<a,c,b,e>10中),并且有13次被 d 跟随(在轨迹<a,d,e>10、<a,d,d,e>2和<a,d,d,d,e>1中)。活动 a 只有一次单独被 b 跟随(在轨迹<a,b,e>中),并且只有一次单独被 c 跟随(在轨迹<a,c,e>中)。让我们假设后面两个绑定低于预先设定的阈值,那么 O(a) = {{b,c},{d},{e}},也就是说,在15个可能的输出绑定中,只有3个是够频繁所以能够被包含的。
许多重演策略能够决定绑定的频次。使用试探法去选择应该包含的绑定。使用了A*算法的一个变体来寻找依赖图上轨迹的“最佳”重演。C-net 的语义是全局的,也就是说一个绑定序列的有效性无法被局部决定(就像在Petri网中一样)。
通过在依赖图上重演事件日志,我们可以估计输入和输出绑定的频次。使用阈值,可以基于绑定的频次来排除一些绑定,得到函数 I 和 O,从而完成这个 C-net 。图6.6展示了基于图6.4中依赖图的C-net 。如图中所示,O(a)={{b,c},{d},{e}}并且I(e)={{a},{b,c},{d}} 。绑定{b}和{c}没有被包含在 O(a)和 I(e)中,因为它们只发生了一次(低于阈值)。图6.6展示了活动的频次、依赖和绑定。例如,活动a 发生了40次,其输出绑定{b,c} 发生了20次。活动 d 发生了17次:其中13次被 a 触发,4次被 d 自身触发。活动 b 发生了21次,而它唯一的输入绑定{a}的频次仅20,这一差异是由于我们排除了a 的不频繁输出绑定 {b} (这一绑定仅在轨迹<a,b,e>中发生)。在活动 c 上可以找到相似的差异。
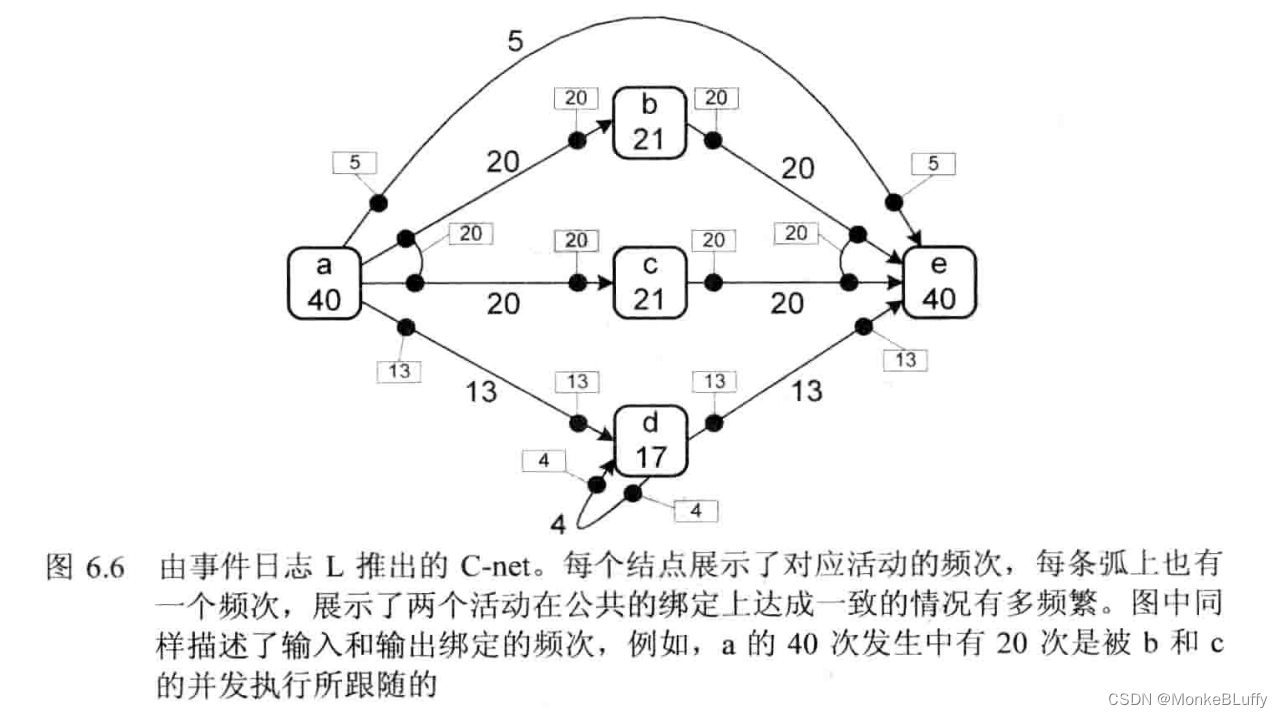
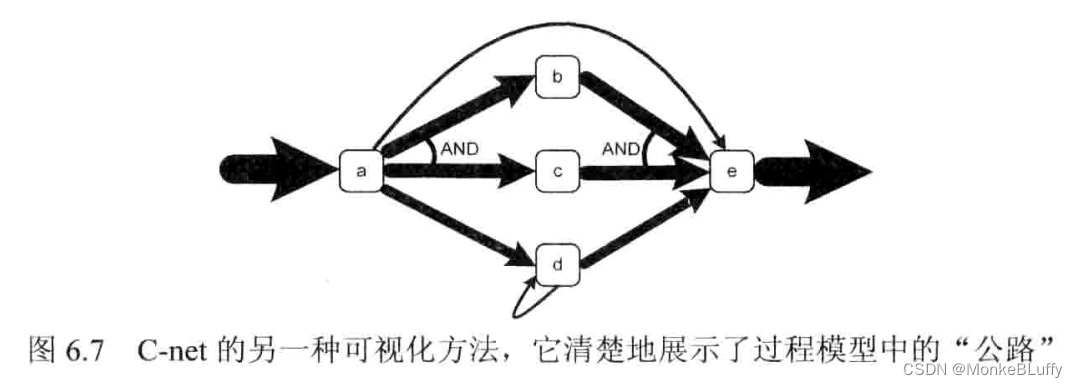
图6.7是图6.6中 C-net 的一个更加直观的展示,现在弧的粗细对应着相应路径的频次。 这种展示方法对于观察主要过程流很重要。第13章会使用地图作为比喻来可视化过程模型。在地图中,会使用粗线和明亮的色彩使公路变得显著,同时不显示不太重要的道路,图6.7 告诉我们,在启发式挖掘中可以做同样的事情。
 本节介绍的方法非常通用,可以被应用到其他的表示法中。 一个著名的例子是模糊挖掘方法,这种方法提供一个可扩展的参数集合,用于决定包含哪些活动和弧。此外,这种方法可以构建层次模型,即把低频次的活动移到子过程中。同样,在提供活动和路径的重要性与频次信息时,可以使用地图形式来创建过程模型,从而使它更加易于理解。
本节介绍的方法非常通用,可以被应用到其他的表示法中。 一个著名的例子是模糊挖掘方法,这种方法提供一个可扩展的参数集合,用于决定包含哪些活动和弧。此外,这种方法可以构建层次模型,即把低频次的活动移到子过程中。同样,在提供活动和路径的重要性与频次信息时,可以使用地图形式来创建过程模型,从而使它更加易于理解。

















 806
806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









