1.引入依赖
<!--sharding jdbc springboot-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.1</version>
</dependency>
2.配置
# 开发环境
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 打印sql
props:
sql:
show: true
datasource:
names: kebang
kebang:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:4000/kebang?serverTimezone=Asia/Shanghai&useSSL=false&characterEncoding=UTF-8&zeroDateTimeBehavior=CONVERT_TO_NULL
username: root
password: 001nX123456
# 数据源其他配置
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
#每个数据库都不一样的 注意要
validationQuery: SELECT 1
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,log4j
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
#慢SQL记录 如果上面validationQuery: SELECT 1 没有配置,而你配置了就会报错null
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
sharding:
# 表策略配置
tables:
# t_msg 是逻辑表
t_msg:
# 分表节点 可以理解为分表后的那些表 比如 t_msg_1 ,t_msg_2
actualDataNodes: kebang.t_msg_$->{1..2}
tableStrategy:
inline:
# 根据哪列分表
shardingColumn: msg_id
# 分表算法 例如:msg_id为奇数 则为t_msg_2 msg_id为偶数 t_msg_1
algorithmExpression: t_msg_$->{msg_id % 2 + 1}
# 分表后,sharding-jdbc的全局id生成策略
# keyGenerator:
# type: SNOWFLAKE
# # 对id列采用 sharding-jdbc的全局id生成策略
# column: id
3.启动器配置
@SpringBootApplication(exclude={DruidDataSourceAutoConfigure.class})

4.编写测试代码测试
@SpringBootTest
@RunWith(SpringRunner.class)
class KeBangApplicationTests {
@Autowired
private MsgService msgService;
@Test
void contextLoads() {
Msg msg = new Msg();
msg.setId(1).setContent("测试").setMsgId(4).setQos(1).setTime(new Date()).setTopic("topic");
msgService.save(msg);
}
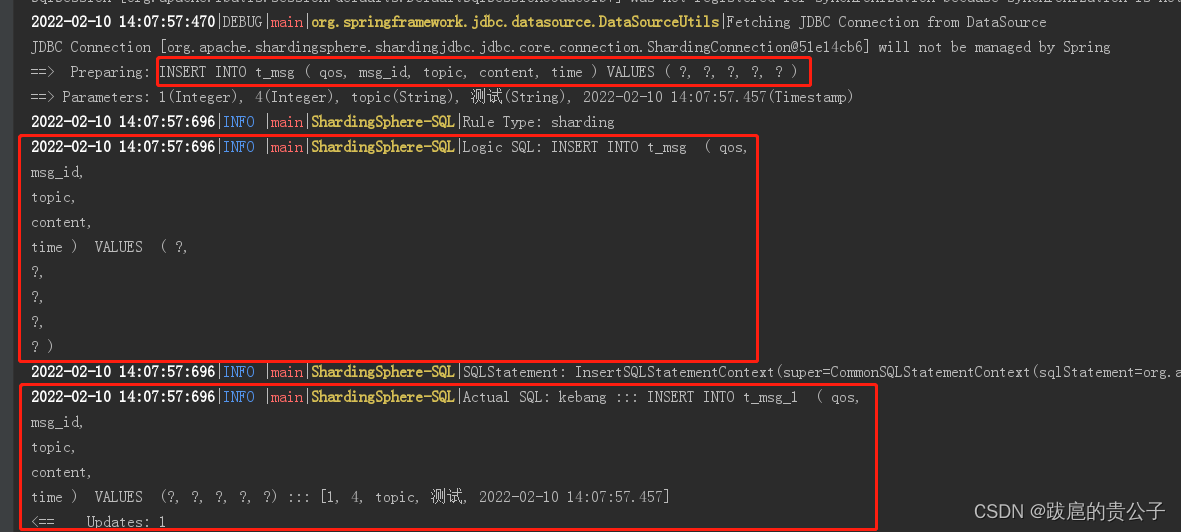
5.测试结果






















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









