







/ 今日科技快讯 /
近日,BOSS直聘宣布将从2021年9月1日起取消“大小周”。恢复双休后,员工薪资中的“周末加班费”仍正常发放,薪资总额不变。BOSS直聘的薪资结构中,“周末加班费”部分约占员工年薪的20%,此举也相当于变相全员涨薪。
/ 作者简介 /
本篇文章转载自RicardoMJiang的博客,作者翻译了一篇关于Google如何设计并迭代一个API的文章,相信会对大家有所帮助!
原文地址:
https://juejin.cn/post/6994066804758806564
/ 前言 /
众所周知,Google发布一个新的Library都要经历alpha,beta,rc,release等多个版本的迭代,在这个漫长的迭代过程中,通常会有Bug的修复,代码与功能的增删等等,哪些代码应该该增加,哪些代码应该删除,这就是考验设计者的地方。
本文主要讲述了Google在设计及迭代repeatOnLifecycle API过程中的设计与决策repeatOnLifecycle主要用于在UI中收集flow,关于它的用法可见之前转载的文章:
通过本文你将了解以下内容:
repeatOnLifecycle API背后的设计决策
为什么alpha版本中添加的addRepeatingJob API会被移除?
为什么flowWithLifecycle API会被保留?
为什么API命名是重要且困难的
为什么只保留库中最基础的几个 API
/ 正文 /
repeatOnLifecycle介绍
Lifecycle.repeatOnLifecycle API主要是为了在UI层进行更安全的Flow收集
比如lifecycle.repeatOnLifecycle(Lifecycle.State.STARTED),会在onStart时启动协程,在onStop时取消协程,然后在Activity重新回到onStart时重新启动一个协程。
这种特性与UI生命周期的可重启性比较契合,让它成为仅当UI可见时才收集flow的完美默认API。
repeatOnLifecycle 是一个挂起函数,repeatOnLifecycle 会挂起调用协程
每次给定的生命周期达到目标状态或更高时,都会启动一个新的协程,运行传入的block
如果生命周期状态低于目标,则为块启动的协程将被取消
最后,在生命周期被销毁之前,repeatOnLifecycle 函数本身不会恢复调用协程
下面来看一下这个API的示例。
class LocationActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
// 从lifecycleScope创建一个新的协程
// 因为repeatOnLifecycle 是一个挂起函数
lifecycleScope.launch {
// 阻塞协程,直到生命周期到达DESTOYED
// repeatOnLifecycle会在每次生命周期处于 STARTED 状态(或更高状态)时,启动一个新的协程运行传入的block
// 并在 STOPPED 时取消协程。
repeatOnLifecycle(Lifecycle.State.STARTED) {
// 安全的collect flow当生命周期到达STARTED
// 当生命周期到达STOPPED 时停止collect
someLocationProvider.locations.collect {
// 收集到新的位置,更新UI
}
}
// 注意,当运行到这的时候,说明lifecycle已经是DESTROYED
}
}
}
如果你对repeatOnLifecycle是怎么实现的感兴趣,可以查看源码。
repeatOnLifecycle源码地址:
https://cs.android.com/androidx/platform/frameworks/support/+/androidx-main:lifecycle/lifecycle-runtime-ktx/src/main/java/androidx/lifecycle/RepeatOnLifecycle.kt
为什么repeatOnLifecycle是挂起函数?
针对repeatOnLifecycle可重启的特性,挂起函数是最佳选择。
因为它保留了调用的上下文,即CoroutineContext
同时repeatOnLifecycle内部使用了suspendCancellableCoroutine,因此它支持取消,当取消协程时,repeatOnLifecycle与它的子协程都会被取消
此外,我们可以在repeatOnLifecycle之上扩展更多API,例如Flow.flowWithLifecycle流操作符。
更重要的是,如果项目需要,它还允许在此API基础上扩展封装辅助函数。这就是我们尝试使用LifecycleOwner.addRepeatingJob API做的事情,我们在 lifecycle-runtime-ktx:2.4.0-alpha01 中添加了该API,但是在alpha02中删除了该API。
为什么移除addRepeatingJob API?
LifecycleOwner.addRepeatingJob API在alpha01中添加,但是在alpha02中被移除了,为什么呢?我们先来看看实现:
public fun LifecycleOwner.addRepeatingJob(
state: Lifecycle.State,
coroutineContext: CoroutineContext = EmptyCoroutineContext,
block: suspend CoroutineScope.() -> Unit
): Job = lifecycleScope.launch(coroutineContext) {
repeatOnLifecycle(state, block)
}
可以看出代码很简单,本质上就是对repeatOnLifecycle的封装,传入state与block就能实现与repeatOnLifecycle同样的效果,之所以引入这个API是为了简化调用方式,一起看下代码:
class LocationActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
lifecycleOwner.addRepeatingJob(Lifecycle.State.STARTED) {
someLocationProvider.locations.collect {
//...
}
}
}
}
乍一看,您可能认为这段代码更简洁,需要的代码更少。但是,如果您不密切注意,使用这个API会带来一些隐藏的陷阱。
尽管addRepeatingJob需要传入一个挂起的block,但addRepeatingJob不是挂起函数。因此,你不应该在协程中调用它!!!
再来看收益,您只节省了一行代码,代价是拥有了一个更容易出错的API。
第一点可能有些同学会奇怪,为什么不应该在协程中调用非挂起函数?实际上是因为协程最核心的概念之一——结构化并发。
什么是结构化并发?
要了解结构化并发,我们先来看看线程,线程的并发是非结构化的。可以想想这几个问题在线程中要怎么解决:
结束一个线程时,怎么同时结束这个线程中创建的子线程?
当某个子线程在执行时需要结束兄弟线程要做怎么做?
如何等待所有子线程都执行完了再结束父线程?
当然这些问题,都可以通过共享标记位等方式解决,但是这几个问题说明,线程间没有级联关系;所有线程执行的上下文都是整个进程,多个线程的并发是相对整个进程的,而不是相对某一个父线程。这就是线程并发的非结构化。
但与此同时,业务的并发通常是结构化的。通常,每个并发操作都是在处理一个任务单元,这个任务单元可能属于某个父任务单元,同时它也可能有子任务单元。而每个任务单元都有自己的生命周期,子任务的生命周期理应继了父任务的生命周期。这就是业务的结构化。
因此协程中引入结构化并发的概念,在结构化并发中,每个并发操作都有自己的作用域,并且:
1.在父作用域内新建作用域都属于它的子作用域;
2.父作用域和子作用域具有级联关系;
3.父作用域的生命周期持续到所有子作用域执行完;
4.当主动结束父作用域时,会级联结束它的各个子作用域。
Kotlin的协程就是结构化的并发,它有协程作用域(CoroutineScope)的角色。全局的 GlobalScope 是一个作用域,每个协程自身也是一个作用域。新建的协程对象和父协程保持着级联关系。
addRepeatingJob的问题
addRepeatingJob不是挂起函数,因此默认情况下不支持结构化并发。由于block参数是一个挂起的lambda,很容易将此API与协程相关联,你可以轻松编写如下危险代码:
class LocationActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
val job = lifecycleScope.launch {
doSomeSuspendInitWork()
// 危险的! 此 API 没有保留调用上下文!
// 当父协程被取消时它不会被取消!
addRepeatingJob(Lifecycle.State.STARTED) {
someLocationProvider.locations.collect {
// 更新ui
}
}
}
// 如果发生错误,取消上面启动的协程
try {
/* ... */
} catch(t: Throwable) {
job.cancel()
}
}
}
这段代码有什么问题?addRepeatingJob 是处理协程相关的东西,没有什么能阻止我在协程中调用它,对吧?
因为addRepeatingJob不是挂起函数,在内部实现中会调用lifecycleScope来启动一个新的协程,因此不会保留调用协程的上下文,也不支持结构化并发,即当调用job.cancel()时不会取消addRepeatingJob中创建的协程,这是非常不符合预期的,也很容易导致难以调试的不可预知的BUG。
在addRepeatingJob内部隐式调用了CoroutineScope,导致这个API在某些情况下使用是不安全的。用户如果要正确使用这个API,还需要了解一下额外的知识,这是不可接收的,这也是移除这个API的原因。而repeatOnLifecycle的主要好处在于它默认支持结构化并发,它还可以帮助您思考您希望重复工作在哪个生命周期内发生。API一目了然,符合开发人员的期望。
为什么保留Flow.flowWithLifecycle?
Flow.flowWithLifecycle运算符构建在repeatOnLifecycle之上,并且仅在生命周期至少处于minActiveState时才发出上游流发送的元素,当生命周期低于minActiveState会取消上游流。
class LocationActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
lifecycleScope.launch {
someLocationProvider.locations
.flowWithLifecycle(lifecycle, STARTED)
.collect {
//更新UI
}
}
}
}
尽管这个API也有一些隐式的需要注意的问题,但我们决定保留它,因为它作为一个Flow操作符很实用。例如,它可以轻松地用于Jetpack Compose。尽管您可以通过使用produceState 和repeatOnLifecycle API 在Compose 中实现相同的功能,我们将此API 保留在库中,作为一个替代方案。
flowWithLifecycle需要注意的问题是,添加flowWithLifecycle运算符的顺序很重要。当生命周期低于minActiveState时,在flowWithLifecycle运算符之前添加的运算符将被取消。但是,即使没有发送任何元素,在flowWithLifecycle之后添加的运行符也不会被取消。因此,这个API命名参照了Flow.flowOn(CoroutineContext)运算符。因为此API更改了用于收集上游流的CoroutineContext,同时使下游不受影响,与flowOn类似。
我们应该添加更多的API吗?
鉴于我们已经拥有了Lifecycle.repeatOnLifecycle、LifecycleOwner.repeatOnLifecycle 和 Flow.flowWithLifecycle API。
我们还应该添加任何其他API吗?
新API可能会带来与它们解决的问题一样多的混乱。支持不同用例的方式有多种,最好的方式取决于你的业务代码是怎样的.对您的项目有效的方法可能对其他人无效。这就是为什么我们不想为所有可能的情况提供API,可用的 API 越多,开发人员就越不知道何时使用什么。因此,我们决定只保留最底层的 API。有时,少即是多。
API命名是重要且困难的
API命名是重要的,命名应符合开发人员的期望并遵循Kotlin协程的约定。例如:
如果API中隐式地使用CoroutineScope启动新的协程,则必须在名称中反映出来,以避免错误的期望!在这种情况下,launch 应该以某种方式包含在命名中。
collect是一个挂起函数。如果API不是挂起函数,则不要在API命名中加上collect。
LifecycleOwner.addRepeatingJob API也很难命名。API内部使用CoroutineScope创建新的协程时,看起来它应该以launch为前缀。但是,我们想将此API与内部的协程分离开来,同时因为它添加了一个新的Lifecycle Observer,因此命名与其他LifecycleOwner API更加一致。
命名也受到现有的LifecycleCoroutineScope.launchWhenX API的影响。
因为launchWhenStarted和repeatOnLifecycle(STARTED)提供完全不同的功能(launchWhenStarted挂起协程的执行,而repeatOnLifecycle取消并重新启动一个新的协程)
如果新API的名称相似(例如,使用launchWhenever作为重新启动的API) ,开发人员可能会感到困惑,甚至在没有注意到的情况下混淆使用它们。
一行代码实现flow收集
目前的收集方法还是有些烦琐的,如果你是从LiveData迁移到Flow,你可能会觉得要是可以一行代码实现collect就好了。这样你就可以删除模板代码,并且使迁移变得简单。
因此,您可以像Ian Lake刚开始使用repeatOnLifecycle API 时所做的那样。
他创建了一个名为collectIn的包装器,如下所示(为了遵循上面讨论的命名约定,我将其重命名为launchAndCollectIn):
inline fun <T> Flow<T>.launchAndCollectIn(
owner: LifecycleOwner,
minActiveState: Lifecycle.State = Lifecycle.State.STARTED,
crossinline action: suspend CoroutineScope.(T) -> Unit
) = owner.lifecycleScope.launch {
owner.repeatOnLifecycle(minActiveState) {
collect {
action(it)
}
}
}
然后你可以在UI中这样使用:
class LocationActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
someLocationProvider.locations.launchAndCollectIn(this, STARTED) {
// 更新UI
}
}
}
这个包装器在这个例子中看起来很好很简单,但遇到了我们之前提到的LifecycleOwner.addRepeatingJob相同的问题。它不支持结构化并发,在其他协程中使用可能很危险。
此外,原来的名称确实具有误导性:collectIn不是挂起函数!如前所述,开发人员预期collect会挂起。也许,这个包装器的更好名称可能是Flow.launchAndCollectIn 以防止不良用法。
你需要一个API包装器吗?
如果您需要在repeatOnLifecycle API之上创建包装器来方便开发,请问问自己是否真的需要它,以及为什么需要它。如果你确信需要,我建议你选择一个非常明确的API命名来清楚地定义包装器的行为,以避免误用。此外,要非常清楚地记录它,以便新手可以完全理解使用它的含义。
/ 阅读源码的小技巧 /
当我们查看源码的时候,已经是API完成的状态了,其实我们可以查看API迭代开发过程的源码,看看在迭代过程中都发生了什么,这些都是开源的。
比如repeatOnLifecycle API是在lifecycle-runtime-ktx库中,我们可以看下它的git log,lifecycle-runtime-ktx库git历史如下图所示:
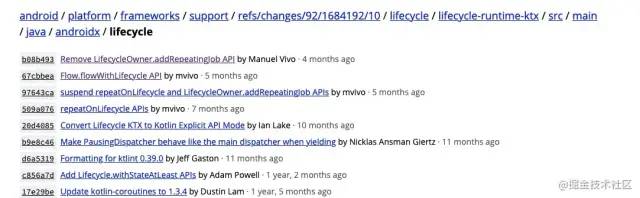
从上面我们可以看出repeatOnLifecycle功能是怎样一步一步被引入并修改的。
我们甚至可以看看代码的review过程,看看reviewer有提出什么意见,比如addRepeatingJob Review过程如下图所示:
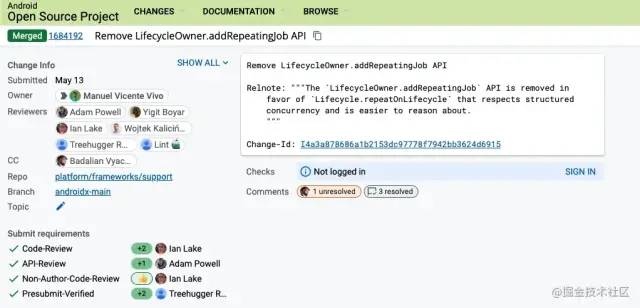
通过查看功能引入的git log,我们可以学习Google是怎么一步一步引入一个新功能并迭代的,相信对我们学习或者开发API都有所帮助。
/ 总结 /
本文主要讲解了repeatOnLifecycle API在开发与迭代过程中的一些设计与思考,总结如下:
API决策通常需要在复杂性、可读性以及
API容易出错的程度方面进行一些权衡思考之所以移除addRepeatingJob API是因为它不支持结构化并发,在协程中使用可能会带来不可预期的错误
API命名是重要且困难的,命名应符合开发人员的期望并遵循原有
API的规范我们不可能为所有情况提供API, 可用的API 越多,开发人员反倒不知道何时使用什么,因此我们只需保留最底层的API,有时少就是多
我们可以通过查看新API引入的git log,来学习理解新API的引入与迭代过程
推荐阅读:
再见JCenter,将你的开源库发布到MavenCentral上吧
欢迎关注我的公众号
学习技术或投稿


长按上图,识别图中二维码即可关注

















 1685
1685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









