







/ 今日科技快讯 /
近日,随着美国消费者对通胀和经济衰退的担忧日益加剧,许多人正在转向来自中国的一款新移动应用,即拼多多海外版Temu。自从9月份上线以来,Temu在美国人气飙升,最近还成为下载量最高的应用。 市场分析公司Sensor Tower的数据显示,在上线不到四个月的时间里,Temu在美国的安装量已达1080万次,成为11月1日至12月14日期间美国下载量最高的移动应用程序。
/ 作者简介 /
本篇文章转自coder_pig的博客,文章主要分享了正则表达式相关的内容,相信会对大家有所帮助!
原文地址:
https://juejin.cn/post/7029544615837433892
/ 0x0、引言 /
正则表达式 → 没有一个开发仔会对这个词陌生吧?没印象的话,想想你是如何判断身份证、手机号码是否合法的?
灵魂拷问:有自己写过正则表达式吗?

可能的回答:
没有,语法看着很难,外星文一样的字符串,看不懂,常规业务用到的正则表达式,网上都有,没必要自己写。
有写好的直接Copy,没毛病,毕竟笔者也是这样,不过不变的是变化,问题来了,假如网上的正则表达式的匹配结果不尽人意、项目中有特殊字符串匹配需求时。
没得抄了,咋整?只能硬着头皮自己写了,一想到那看似枯燥难懂的语法,你:

莫慌,正则真不难,你可以永远相信杰哥,就让这篇短小精悍的文章助你上手正则表达式,然后一脚踢开这只拦路虎。

Tips:本节代码示例基于Python的re库编写,虽大部分编程语言的正则库都是师从 Perl语言,语法基本一样,但也可能略有差异~
/ 0x1、简介与亿点点学习经验 /
正则表达式 (Regular Expression) → 一门为了字符串模式匹配,从而实现搜索和替换功能的工具。
简单点说:
诉求:查找或替换字符串中满足条件的子串;
正则表达式:用来描述这个条件的工具;
Talk is cheap,平时老说正则表达式,字符串匹配的神器,到底有多神,写个简单例子体验下~
有下面这样一串字符串,让你查找当中所有的数字,你会怎么做?
sdfk似懂123非懂就35了框架89路径考669虑看路径

不用正则的话,一种常见的简单思路。遍历每个字符,执行判断,数字拼接,非数字跳过,代码示例如下:
sentence = "sdfk似懂123非懂就35了框架89路径考669虑看路径"
number_dict = {} # 键为数字字符串、值为下标
temp_str = ""
for index, character in enumerate(sentence):
# 判断是否为数字,是追加
if character.isnumeric():
temp_str += character
else:
if len(temp_str) > 0:
number_dict[temp_str] = index
temp_str = ""
continue
print(number_dict)
# 运行输出结果如下:
{'123': 9, '35': 14, '89': 19, '669': 25}而使用正则,只需写一个匹配表达式 \d+,即可实现同样的匹配结果,代码示例如下:
import re
sentence = "sdfk似懂123非懂就35了框架89路径考669虑看路径"
results = re.finditer(r'\d+', sentence)
if results is not None:
for result in results:
print(result)
# 运行输出结果如下:
<re.Match object; span=(6, 9), match='123'>
<re.Match object; span=(12, 14), match='35'>
<re.Match object; span=(17, 19), match='89'>
<re.Match object; span=(22, 25), match='669'>不要简单太多,此时再来需求说,字母也要匹配,遍历的方法还要去改循环逻辑,而正则直接改表达式即可~

Tips:写起来是爽,但性能可能没有遍历的方式好,下面说到正则的性能问题就知道了~
开始讲解正则的具体语法前,share一波自己学正则表达式的心得,毕竟自己也是从害怕它过来的~
① 不要有畏难情绪,越怕越学不会,都是死知识的组合而已,远没有算法难!
② 降低预期,不要上来就想着写出那种贼牛逼的正则表达式,先写出能用就好的正则,后面再慢慢优化,大佬的正则也是经过大量尝试推演出来的;
③ 反复练习,看懂语法谁不会,得去练,加深印象,没机会练习的话,就自己找,安利两个练手方向:
方向一:查找满足条件的网页结点或文本
直接Chrome浏览器,F12打开开发者工具 → 切换到Source选项卡 → Ctrl + Shift + F,输入正则表达式,如:

方向二:推敲网上常用的正则表达式模板
分析下别人为什么那样写,弄点测试样本,自己试着写出来,多写几遍。不要不放过每个可以锻炼自己写正则的机会,只看不练,过不了几天,你的正则姿势就都还给杰哥了,另外,安利一个可视化正则表达式的神器:regexper。
https://regexper.com/
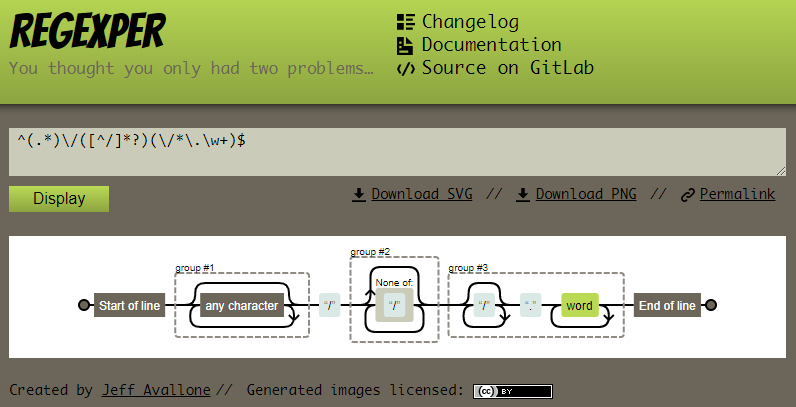
另外,临时的正则校验工具,直接搜索引擎搜关键 在线正则表达式 ,网上一堆。万事具备,开始讲解正则具体的语法姿势了,冲!!!

/ 基础语法 /
完整的正则表达式由两种字符构成:
普通字符;
特殊字符(元字符) → 表示特殊语义的字符,正则表达式功能的最小单位,如 *** ^ $ \d** 等;
① 最简单的匹配
没有特殊语义,普通字符一一对应,比如想在"Hello Python"字符串中查找"tho",直接用 'tho' 这个正则就好;
② 如何匹配特殊字符?
正则中的点 . 是特殊字符,用于匹配任意一个字符(除\n外),如果想把它当成普通字符串对待,即匹配一个点,需要用到转义字符 → 反斜杠\。放在特殊字符前,让其失去原本的特殊语义,比如:\. 就变成单纯地匹配点(.)了;
罗列一波特殊字符元字符:
. → 匹配任意一个字符 (除换行符\n除外)
\d → 匹配数字,0-9;
\D → 匹配非数字;
\s → 匹配空白,即空白符和tab缩进;
\S → 匹配非空白;
\w → 匹配字母、数字或下划线:a-z、A-Z、0-9、_;
\W → 匹配非字母、数字或下划线;
\x → 匹配十六进制数字;
\O → 匹配八进制数字;
\n → 匹配换行符;
\r → 匹配回车符;
\v → 匹配垂直制表符;
\t → 匹配制表符;
\f → 匹配换页符;
[\b] → 匹配退格字符,加[]是为了和\b区分;
③ 数量
只使用上述元字符,只能匹配单个字符,想匹配多个字符还得搭配下述元字符:
| → 逻辑或操作符,比如"ab"和"ac"都想匹配到,可以用这样的正则:"ab|c"
* → 前一个字符(子表达式) 出现0次或无限次,即可有可无;
+ → 前一个字符(子表达式) 出现1次或无限次,即最少一次;
? → 前一个字符(子表达式) 出现0次或1次,即要么不出现,要么只出现一次;
{m} → 前一个字符(子表达式) 出现m次;
{m,} → 前一个字符(子表达式) 至少出现m次;
{m,n} → 前一个字符(子表达式) 出现m到n次;
Tips:尽量使用*+?,因为做了优化,相比起{m}{m,}{m,n}速度更快。
④ 集合与区间
当我们想匹配多个字符中的一个,比如匹配26个小写字母,得怎么写?下面这样吗?
a|b|c|d|e|f|g|h|...太长省略如果还得匹配26个大写字母呢?拼接一堆或操作符,繁琐得一匹,可以使用集合与区间元字符来简化,有下面这些:
[] → 匹配字符集合[]中列举的字符,如:[abc],就是匹配abc中的一个字符;
[^] → 匹配不在字符集合[]中列举的字符,如:[^abc],就是匹配不在abc中的字符;
- → 定义一个区间,或者说匹配一个范围,如:[a-z] 就是匹配26个小写字母中的一个;
⑤ 位置边界
在查找过程中,有时我们还得限制查询的位置,比如只想在单词的开头或结尾查找字符,可以用下面这些元字符:
^ → 匹配一行的开始,多行模式能识别\n;
$ → 匹配一行的结尾,多行模式能识别\n;
\A → 匹配字符串开头,单行模式效果同^,多行模式不能识别\n;
\Z → 匹配字符串结尾,单行模式效果同$,多行模式不能识别\n;
\b → 匹配单词边界,即单词和空格间的位置,如:er\b 可以匹配never中的er,却不能匹配verb中的er;
\B → 匹配非单词边界;
< → 匹配单词开头;
> → 匹配单词结尾;
/ 手撕验证手机号码格式的正则 /
光说不练假把式,光练不说傻把式,又练又说真把式,欲速则不达,学完基础语法,先写个例子练练手,找找感觉~

如题,手撕验证手机号码格式的正则,怎么玩?可以把一个正常的手机号码拆成三个部分写正则,最后再拼起来~
① 号码前缀
要么要么,要么有的话只有一个,用?接着取值的话可能是下面这三种:
0 (长途)
86 (天朝国际区号)
17951 (国际电话)
不难写出这样的正则:(0|86|17951)?,圆括号代表子表达式,你可以先理解成分组,等下会详细讲~
② 1xx
接着到1xx,有这几种:13x、14x、15x、17x、18x,然后后面的x对应的取值范围是不一样的:
13x:0123456789
14x:579
15x:012356789
17x:01678
18x:0123456789
看着很复杂?其实不然,用好 | 和集合与区间元字符就好,根据规则不难写出这样的正则:(13[0-9]|14[579]|15[0-35-9]|17[01678]|18[0-9])
③ 剩下的8个数字
数字就行,想都不用想直接写出:(\d{8}),最后拼接下三段正则:
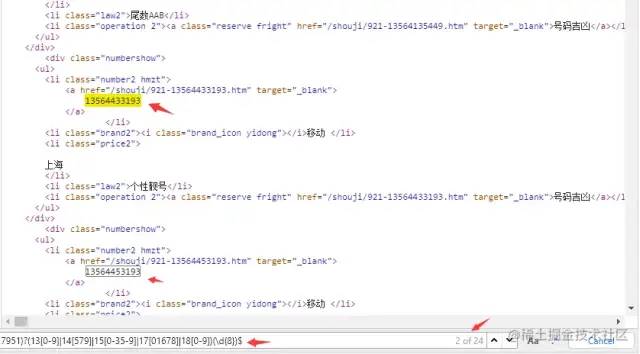
(0|86|17951)?(13[0-9]|14[579]|15[0-35-9]|17[01678]|18[0-9])(\d{8})接着搜索引擎搜下 手机号码大全,随手点开一个站点,F12 → Source 输入上述正则查下看看:

可以,匹配到了,但是好像也匹配了一些奇怪的东西,比如上面的 921-xxx.html,简单,加上$匹配一行结束即可~

例子刷完了,简单吧!接着继续了解正则的高级语法~
/ 高级语法 /
说是高级也不见得有多高级,只是得稍微动下脑子而已~
① 分组
就是使用一对圆括号()包裹子表达式,它是构成高级正则表达式的基础。如果没用到后续的语法,分不分组其实是一样的~
② 反向引用
又称回溯引用,指的是:模式的后面内容,引用前面已经匹配到的子字符串。有点懵?写个简单例子帮助理解,现在有这样一段字符串:
pineapple peach plum watermelon durian durian grape mango strawberry strawberry chestnut想匹配两个连续相同的单词,可以这样写正则:
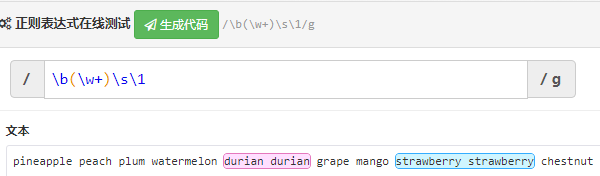
所以反向引用的语法就是:\第几个子字符串,反向引用在替换字符串的场景很常用。替换时语法上有些许差异,一般使用 \g<第几个字符串> 来引用要被替换的字符串。以之前文章替换字符串部分内容为例~

Markdown语法的图片URL,被一个换行符\n分割成了两行,又不能全局替换\n,因为会影响其他文本的格式,只替换这种异常的图片URL,利用反向引用就可以做到。
error_pic_pattern_n = re.compile(r'(http.*?)(\n)(.*?\.\w+\))', re.M)
# 就是划分成了三个分组(子表达式),然后把1、3分组拼接结果作为替换结果
new_content = error_pic_pattern_n.sub(r"\g<1>\g<3>", new_content)反向引用,就这?就拿子表达式的匹配结果乱玩而已?是的,就是这么简单~

另外,如果不想子表达式被引用,可以使用非捕获正则 → (?:子表达式),这样玩还可以避免浪费内存~
③ 前/后向查找
又称前/后向段言、顺序/逆序环视、前瞻后顾等,又是些牛马专业名词?
不急,写个简单例子帮助理解它得玩法,打开苹果官网识别您的 iPhone 机型。现在有个这样的需求:
想看下iphone 11、12、13都有哪些机型,要求写个正则筛一波。先写个能提取所有机型的正则吧:
<h2>iPhone .*?</h2>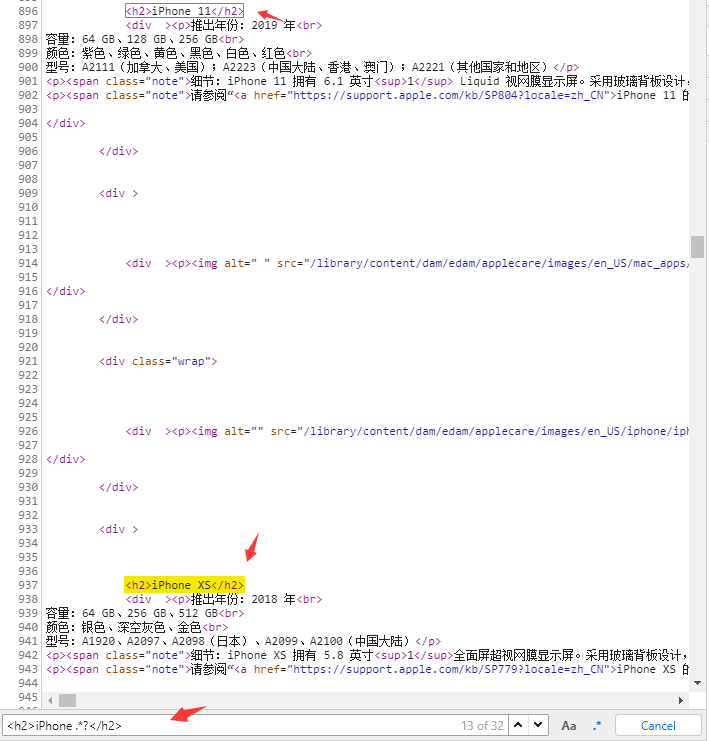
可以拿到机型,但是原需求只想筛11、12、13的机型,什么XS、XR的不感兴趣,这个时候就可以上向前肯定断言(?=) 了。改完后的正则:
<h2>iPhone (?=13|12|11).*?</h2>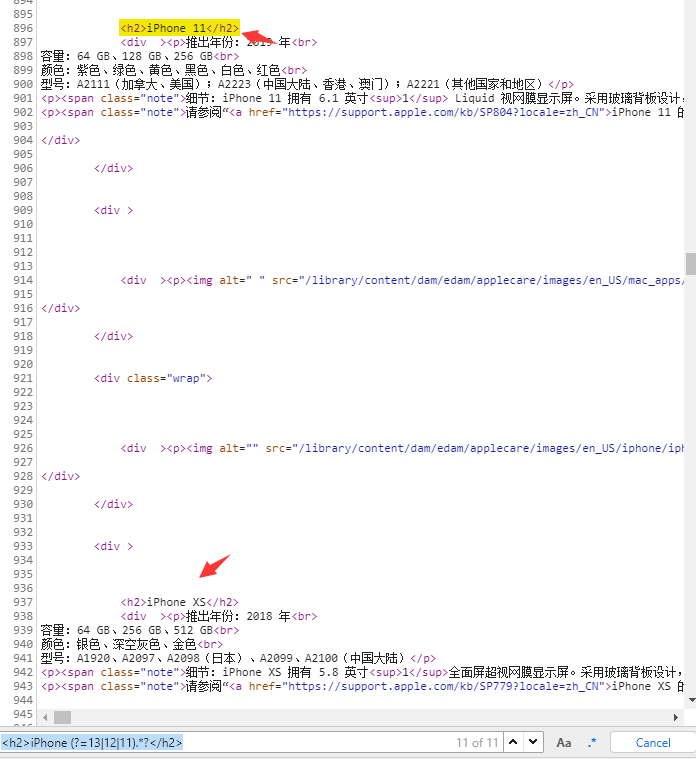
可以,除了11、12、13,其他型号的阿猫阿狗都没匹配到,不难看出前向肯定断言(?=re) 在这里的作用就是先找到满足断言里子表达式 → 13|12|11 的位置,然后在这个位置往前找匹配 <h2>iPhone 的字符串;
这个顺序很关键哈!!!先找断言里的子表达式,再找前面的表达式,这一点,很多教程都说得不清不楚!!向前肯定断言的玩法了解了,其他三种断言也就一点就通了:
(?!re) → 前向否定断言,先匹配不满足re的位置,然后向前匹配;
(?<=re) → 后向肯定断言,先匹配满足re的位置,然后向后匹配;
(?<!re) → 后向否定断言,先匹配不满足re的位置,然后向后匹配;
读者可以自行试试下述例子加深理解:
# 前向否定断言,看11、12、13外的机型
<h2>iPhone (?!11|12|13).*?</h2>
# 后向肯定断言,看下有Plus系列的机型有哪些
<h2>iPhone .*?(?<=Plus)</h2>
# 向后否定断言,看下没Plus系列的机型有哪些
<h2>iPhone .*?(?<!Plus)</h2>限于篇幅就不贴结果图了哈,再说两个个要注意的点哈:
① 断言里的子表达式,不消耗字符!不会影响你外部正则表达式的匹配!!!
② 前瞻后顾在某些语言或环境下可能不支持,使用时要谨慎验证支持情况哈!!!
④ 贪婪与非贪婪
正则匹配默认是贪婪匹配,即匹配尽可能多的字符~

简单得很,写个例子你就懂了:
re.match(r'^(\d+)(0*)$','12345000').groups()
# 原意是想得到('12345', '000')这样的结果的,但输出的却是:('12345000', '')
# 由于贪婪匹配,直接把后面的0都给匹配了,结果0*没东西匹配了
# 若果想尽可能少的匹配,可在\d+后加上一个问号?,采用非贪婪匹配,改成介样:
re.match(r'^(\d+?)(0*)$','12345000').groups()
# 输出结果:('12345', '000')/ 背后的原理 /
这Part选读哈,不感兴趣可以跳过,多熟悉熟悉上面的正则语法就行了,笔者想弄清楚正则表达式背后原理的原因:
网上很多文章都说到,正则表达式令人诟病的性能问题,但却很少人说清具体是什么问题?怎么引起的?如何规避优化~
下述图片和内容大部分来源于:《正则表达式引擎执行原理——从未如此清晰!》
https://segmentfault.com/a/1190000021787021
① 正则表达式的工作流程

这里的预编译指的是提前初始化好正则对象,如Python中的re库,建议调用 re.compile(patter) 预编译返回Pattern对象,后续用到正则的地方直接引用;预编译的方式,在循环中,用同一个正则进行匹配的场景有奇效(避免重复创建、编译)。
② 引擎
程序对正则表达式进行语法分析,建立语法分析树,再根据分析树结合正则表达式引擎生成执行程序(状态机、又称状态自动机)用于字符匹配。
这里的引擎就是一套 用于建立状态机的核心算法,主要分为下述两大类:
DFA (Deterministic finite automaton) → 确定型有穷自动机;
NFA (Non-deterministic finite automaton) → 非确定型有穷自动机;
拆词:
确定型与非确定型 → 字符串在没编写正则表达式的前提下,能否直接确定字符匹配顺序?能就是确定型,不能的就是不确定型;
有穷 → 在有限次数内能得到结果;
自动机 → 在设置好匹配规则后由引擎自动完成,不需人为干预;
对比:
构造DFA的成本代价(用内存多、编译速度慢)远高于NFA,但DFA的执行效率高于NFA;
假设字符串长度为n,DFA的匹配时间复杂度为O(n),NFA因为匹配过程中存在大量分支和回溯,假设状态数为s,NFA的匹配的时间复杂度为O(ns);
NFA的优势是支持更多功能,如捕获Group、环视、量词等高级功能,这些功能都是基于子表达式独立进行匹配,因此在编程语言中,使用正则表达式的库都是 基于NFA实现的;
DFA自动机是如何进行匹配的?

要点:
文本主导 → 按文本顺序执行,稳定;
记录当前有效的所有可能 → 如执行到(d|b),会同时比较表达式中的a|b,故需要更多的内存;
每个字符只检查一次 → 提高了执行效率,且速度与正则表达式无关;
不能使用反向引用等功能 → 每个字符只检查一次,位置只记录当前值,故无法使用反向引用、环视等功能;
NFA自动机是如何进行匹配的?

要点:
表达式主导 → 按照表达式的一部分执行,不匹配换其他部分继续匹配,直到表达式匹配完成;
会记录某个位置 → 如执行到(d|b)时,记录字符的位置,然后选择其中一个先匹配;
每个字符可能检查多次 → 执行到(d|b)时,比较d后发现不匹配,换成表达式的另外一个分支b,同时文本位置 回退,重新匹配字符b。这也是NFA非确定及效率可能没有DFA高的原因;
能使用反向引用等功能 → 因为有回退功能,所以很容易实现反向引用、环视等功能;
③ NFA自动机的回溯问题
上述回退专业术语叫回溯,原理类似于走迷宫时走过的路设置一个标志物,不对原路返回,换成另一条路。
回溯机制不但要重新计算正则表达式和文本的对应位置,还需要维护括号子表达式所匹配的文本状态,保存到内存中以数字编号的组中,这个组也叫捕获组。
捕获组保存括号内的匹配结果,后面的正则表达式中可以使用,就是上面说到的反向引用。还不是很理解?画个简单的回溯流程示意图~
content_str = "HELLO"
content_regex = "HEL+O"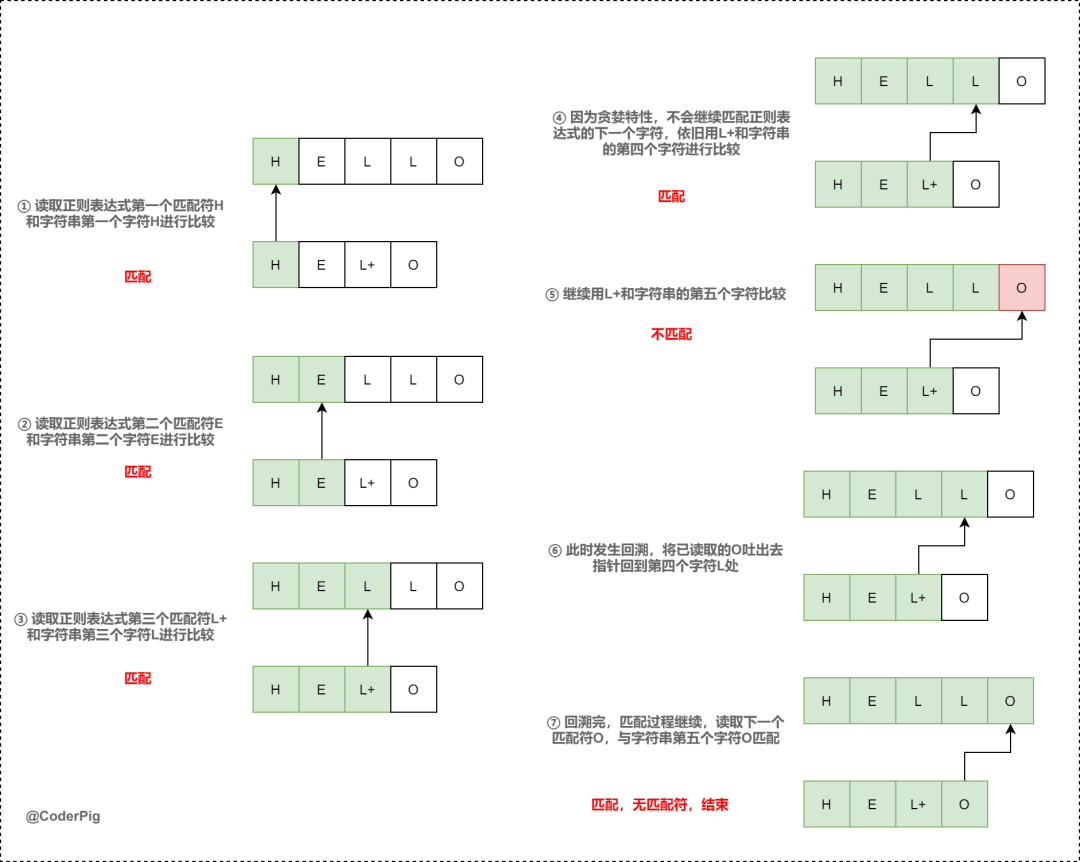
不难看出,回溯问题的导火索就是贪婪匹配,吃得多,要吐的也多,如果匹配的文本长度几W,引擎可能就要回溯几w次。
如果碰到复杂的正则表达式,有多个部分要回溯,那回溯次数就是指数级别。比如文本长度为500,表达式有两部分要回溯,次数可能就是500^2=25w次了。够呛的...
④ 优化
优化的方向:减少引擎回溯次数 + 更快更直接地匹配到结果。
1) 少用贪婪模式
可使用非贪婪模式(加?,会首先选择最小的匹配范围)和独占模式(加+,不匹配结束匹配,不回溯)来避免回溯。
2) 减少分支选择
少用,一定要用的话可通过下述几种方式优化:
选择的顺序 → 更常用的选择项放前面,使得它们能较快地被匹配;
提取共用模式 → 如:将(abcd|abef) 替换成→ ab(cd|ef);
简单的分支选择 → 不用正则,直接用字符串查找函数(如index())找,效率还高一些;
3) 使用非捕获型括号
一般一个()就是一个捕获组,如果不需要引用括号中的文本,可使用非捕获组 (?:er),既能减少捕获时间,又能减少回溯使用的状态数量。
4) 一些零碎的优化点
长度判断优化 → 匹配字符串的长度都没正则长度长,就没必要匹配了;
预查必须字符 → 预先扫描必须字符,找都找不到,就没必要匹配了;
用好行和字符串开始、结束符 → 用好 ^$\A\Z 更精确匹配行头、行尾、字符串开头和字符串结尾;
别滥用括号 → 在需要的时候才用括号,在其他时候使用括号会阻止某些优化措施;
别滥用* → 点符号可以匹配任意字符串,但贪婪匹配会导致大量的回溯;
量词等价替换 → a{3} 可比 aaa要快上一些;
拆分表达式 → 有时,多个小正则表达式的速度比一个大正则表达式的速度要快很多;
/ 小结 /
本节,系统过了一波正则表达式,从知道是什么,到语法,然后到原理,内容虽少,五脏俱全,希望能帮到想学正则的朋友,别再下次一定了,这次一定,学废 正则表达式~

常用的正则表达式模板网上有很多,菜鸟工具上还挺全,取需,就不搬运了~
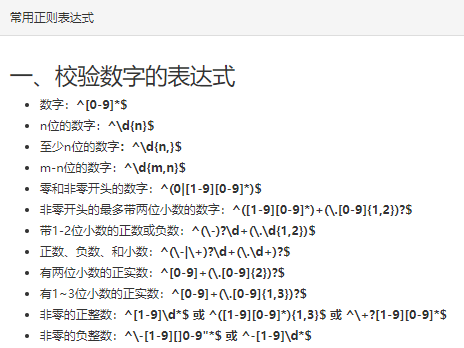
再安利一个插件吧:any-rule,同样取需~

最后,附上Python中re模块的常用函数速查,有问题欢迎在评论区反馈,谢谢~
Python中re模块的常用函数
import re
# 将正则表达式编译成Pattern对象,好处:预编译+复用
test_pattern = re.compile(正则表达式字符串,标志位修饰符)
# 标志位修饰符(flags) 用于控制匹配模式,支持同时选择多个(|连接),有下述这些:
#
# re.I IGNORECASE → 忽略大小写
# re.M MULTILINE → 多行匹配,影响^和$
# re.S DOTALL → 使.匹配包括换行在内的所有字符
# re.X VERBOSE → 忽略空白和注释,并允许使用'#'来引导一个注释
# re.U UNICODE → 根据Unicode字符集解析字符,影响\w、\W、\b和\B
# re.L LOCALE → 做本地化识别(locale-aware)匹配
# 匹配:尝试从字符串的开头进行匹配,匹配成功返回匹配对象,否则返回None
re.match(pattern, string, flags=0)
# 匹配:扫描整个字符串,返回第一个匹配对象,否则返回None;
re.search(pattern, string, flags=0)
# 检索:扫描整个字符串,匹配所有能匹配的对象,以列表形式返回;
re.findall(pattern, string, flags=0)
# 检索:同findall,匹配所有能匹配的对象,但是是以迭代器形式返回;
re.finditer(pattern, string, flags=0)参数
# 替换:将匹配的字符串替换为其他字符串,count为替换的最大次数,默认为0,替换所有。
re.sub(pattern, repl, string, count=0, flags=0)
# 分割:将匹配的字符串进行分割,返回列表,maxsplit为分割的最大次数,默认为0,分割所有。
re.split(pattern, string, maxsplit=0, flags=0)
# 分组:获取匹配结果中,每个分组匹配内容,可传入分组序号,不传整个匹配结果,传获取对应分组内容
pattern_result.group()
# 分组:从group(1)开始往后的所有值,返回一个元组
pattern_result.groups()
# 匹配的开始、结束位置
pattern_result.start() # 返回匹配的开始位置
pattern_result.end() # 返回匹配的结束位置
pattern_result.span() #返回一个元组,表示匹配位置(开始,结束)
# 加载正则表达式字符串前的'r',如re.compile(r'xxx'),作用:
# 告知编译器这个str是raw string(原始字符串),不要转义反斜杠,如r'\n'是两个字符
# 反斜杠 + n,而不是换行!推荐阅读:
欢迎关注我的公众号
学习技术或投稿


长按上图,识别图中二维码即可关注















 266
266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









